第六章 链路层和LAN
第六章 链路层和LAN
在前两章中,我们了解到网络层在任意两个网络主机之间提供通信服务。在两台主机之间,数据报通过一系列的通信链路传输,有些是有线的,有些是无线的,从源主机开始,通过一系列数据包交换机(交换机和路由器),最后到达目标主机。当我们继续沿着协议栈向下走,从网络层到链路层,我们自然想知道数据包是如何在组成端到端通信路径的各个链路上发送的。如何将网络层数据报封装在链路层帧中以便在单个链路上传输?在通信路径的不同链路上是否使用不同的链路层协议?如何解决广播链路中的传输碰撞?在链路层有寻址吗?如果有,链路层寻址如何与我们在第四章学到的网络层寻址操作?那么交换机和路由器到底有什么区别呢?我们将在本章中回答这些问题和其他重要问题。
在讨论链路层时,我们将看到有两种基本的不同类型的链路层信道。第一种是广播信道,它连接无线局域网、卫星网络和混合光纤同轴电缆(HFC)接入网中的多个主机。由于许多主机连接到同一个广播通信信道,因此需要一种所谓的媒体接入协议来协调帧传输。在某些情况下,可以使用中央控制器来协调传输;在其他情况下,主机本身协调传输。第二类链路层信道是点对点通信链路,例如经常出现在通过长距离链路连接的两个路由器之间,或者用户的办公室计算机和附近的以太网交换机之间。协调对点对点链路的访问更简单;本书网站上的参考资料详细讨论了点对点协议(PPP),该协议用于从电话线上的拨号服务到光纤链路上的高速点对点帧传输等各种设置。
在本章中,我们将探讨几个重要的链路层概念和技术。我们将更深入地讨论错误检测和纠正,这是我们在第3章中简要讨论过的主题。我们将探讨多种接入网络和交换局域网,包括以太网,目前最流行的有线局域网技术。我们还将讨论虚拟局域网和数据中心网络。虽然WiFi和更普遍的无线局域网是链路层的主题,但我们将把这些重要主题的研究推迟到第7章。
6.1链路层介绍
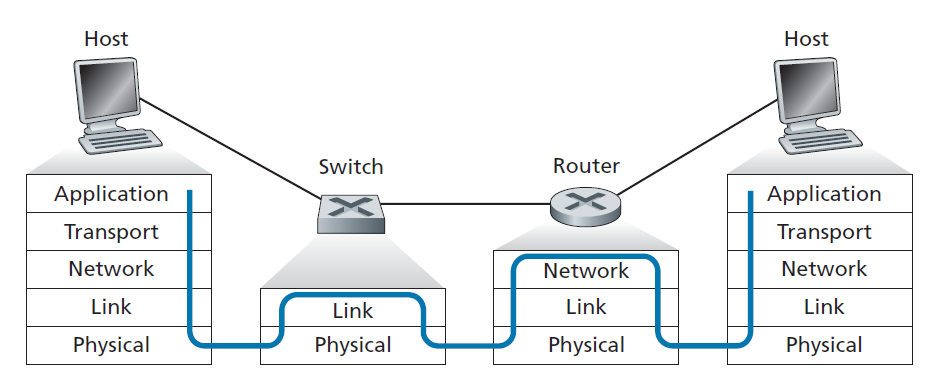
让我们从一些重要的术语开始。我们将在本章中方便地将任何运行链路层(即第2层)协议的设备称为 节点 。节点包括主机、路由器、交换机和WiFi接入点(在第7章讨论)。我们也将沿着通信路径连接相邻节点的通信信道称为 链路 。为了将数据报从源主机传输到目标主机,它必须在端到端路径中的每个 单独链路 上移动。例如,在图6.1底部所示的公司网络中,考虑从一个无线主机向一个服务器发送数据报。这个数据报实际上会经过6条链路:发送主机和WiFi接入点之间的WiFi链路,接入点和链路层交换机之间的以太网链路;链路层交换机与路由器之间的链路,两个路由器之间的链路;路由器和链路层交换机之间的以太网链路;最后是交换机和服务器之间的以太网链路。在给定的链路上,传输节点将数据报封装在链路层帧中,并将该帧传输到链路中。
为了进一步深入了解链路层以及它与网络层的关系,让我们考虑一个传输的类比。考虑一个旅行社代理,他正在为一个从新泽西州普林斯顿到瑞士洛桑的游客计划旅行。旅行社认为,游客最方便的方式是,先乘坐豪华轿车从普林斯顿到肯尼迪机场,然后乘坐飞机从肯尼迪机场到日内瓦机场,最后乘坐火车从日内瓦机场到洛桑火车站。一旦旅行社完成了三次预订,普林斯顿豪华轿车公司就有责任把游客从普林斯顿送到肯尼迪机场;把旅客从肯尼迪机场送到日内瓦是航空公司的责任;把游客从日内瓦送到洛桑是瑞士火车服务的责任。这三段行程中的每一段都直接在两个相邻的地点之间。请注意,这三个运输部分由不同的公司管理,使用完全不同的运输方式(豪华轿车、飞机和火车)。虽然运输方式不同,但它们都提供了将乘客从一个地点转移到相邻地点的基本服务。在这个运输类比中,游客是一个数据报,每个运输段是一个链路,运输模式是一个链路层协议,而旅行代理是一个路由协议。
6.1.1链路层提供的服务
尽管任何链路层的基本服务都是通过单个通信链路将数据报从一个节点移动到相邻的节点,但所提供的服务的细节可能因链路层协议的不同而不同。链路层协议可以提供的可能服务包括:
- 组帧 几乎所有的链路层协议在链路上传输之前都将每个网络层数据报封装在链路层帧中。一个帧由一个插入网络层数据报的数据字段和一些头字段组成。帧的结构由链路层协议指定。在本章的后半部分,当我们研究特定的链路层协议时,我们将看到几种不同的帧格式。
- 链路接入 媒体接入控制(MAC,medium access control)协议指定了帧在链路上传输的规则。对于在链路一端只有一个发送方,另一端只有一个接收方的点对点链路,MAC协议是简单的(或不存在)——发送方可以在链路空闲时发送帧。更有趣的情况是,当多个节点共享一个广播链路时——所谓的多路接入(multiple access)问题。在这里,MAC协议负责协调多个节点的帧传输。
- 可靠交付 当链路层协议提供可靠的传输服务时,它保证每个网络层的数据报在链路上无错误地移动。回想一下,某些传输层协议(如TCP)也提供可靠的交付服务。与传输层可靠交付服务类似,链路层可靠交付服务可以通过确认和重传实现(见第3.4节)。链路层可靠传输服务通常用于出错率高的链路,例如无线链路,其目标是在发生错误的链路上本地纠正错误,而不是通过传输层或应用层协议强制进行端到端重传数据。然而,链路层的可靠传输可以被认为是低比特错误链路(包括光纤、同轴电缆和许多双绞线铜链路)的不必要开销。由于这个原因,许多有线链路层协议不提供可靠的传输服务。
- 检错和纠错 接收节点中的链路层硬件在将帧中的比特作为1传输时可能错误地判定为0,反之亦然。这种比特错误是由信号衰减和电磁噪声引起的。由于不需要转发有错误的数据报,许多链路层协议提供了一种检测这种比特错误的机制。这是通过让发送节点在帧中包含错误检测位,并让接收节点执行错误检查来完成的。回顾第3章和第4章,Internet的传输层和网络层也提供了一种有限形式的错误检测——Internet校验和。链路层的错误检测通常更加复杂,并且在硬件上实现。纠错类似于错误检测,不同的是接收端不仅要检测帧中何时发生了比特错误,而且要确定错误发生在帧中的确切位置(然后纠正这些错误)。
6.1.2链路层实现位置
在深入研究链路层之前,让我们考虑在哪里实现链路层的问题,从而结束本文的介绍。主机的链路层是在硬件还是软件中实现的?它是在单独的卡片或芯片上实现的吗?它如何与主机的其余硬件和操作系统组件连接?
图6.2显示了一个典型的主机架构。以太网功能要么集成到主板芯片组,要么通过低成本的专用以太网芯片实现。在大多数情况下,链路层是在称为 网络适配器(network adapter) 的芯片上实现的,有时也称为 网络接口控制器 (NIC,network interface controller)。网络适配器实现许多链路层服务,包括组帧、链路接入、错误检测等。因此,链路层控制器的大部分功能是在硬件上实现的。例如,Intel 700系列适配器[Intel 2020]实现了我们将在第6.5节中学习的以太网协议;Atheros AR5006 [Atheros 2020]控制器实现802.11 WiFi协议,我们将在第七章中研究。
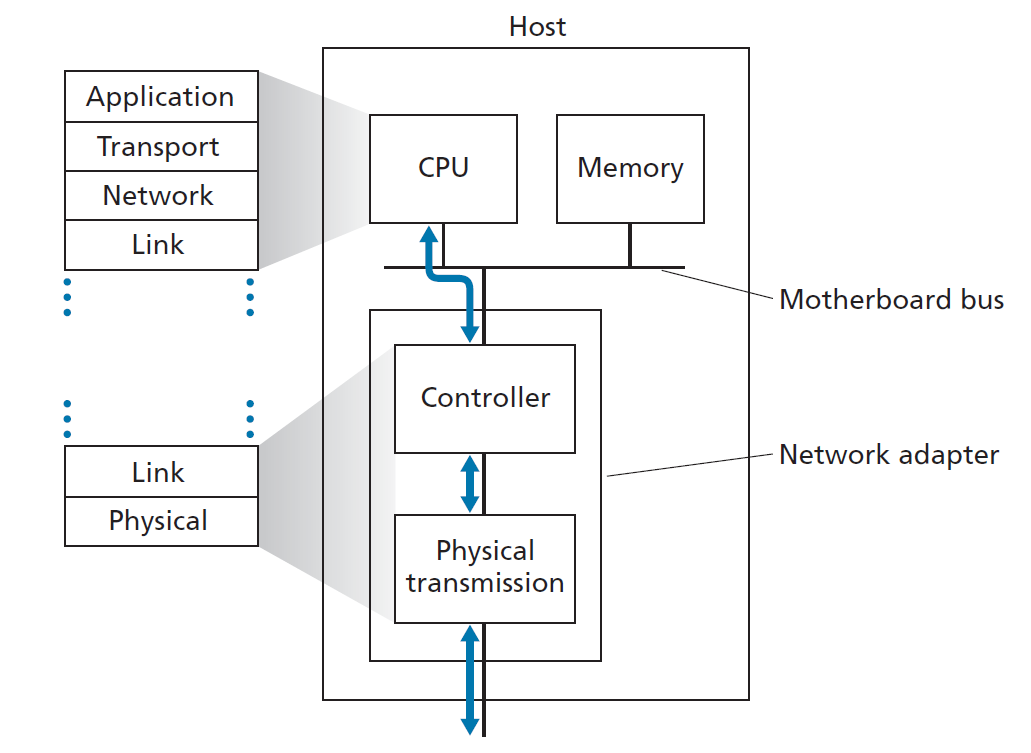
在发送端,控制器接收一个由协议栈的较高层创建并存储在主机内存中的数据报,将数据报封装在链路层帧中(填充帧的各个字段),然后按照链路接入协议将该帧传输到通信链路中。在接收端,控制器接收整个帧,并提取网络层数据报。如果链路层进行错误检测,则发送控制器设置帧头中的错误检测位,接收控制器进行错误检测。
图6.2显示,虽然大部分链路层是在硬件中实现的,但部分链路层是在运行在主机CPU上的软件中实现的。链路层的软件组件实现更高级的链路层功能,如组装链路层寻址信息和激活控制器硬件。在接收端,链路层软件响应控制器中断(例如,由于接收到一个或多个帧),处理错误条件并将数据报传递到网络层。因此,链路层是硬件和软件的组合,是协议栈中软件与硬件相遇的地方。[Intel 2020]从软件编程的角度提供了XL710控制器的可读概述(以及详细描述)。
检错和纠错技术
在上一节中,我们提到了 比特级错误检测和纠正 ——检测和纠正从一个节点发送到另一个物理上连接的邻居节点的链路层帧中损坏的比特——链路层通常提供两种服务。我们在第3章中看到,错误检测和纠正服务也经常在传输层提供。在本节中,我们将研究一些最简单的技术,这些技术可用于检测和在某些情况下纠正这种比特错误。对这一主题的理论和实施的全面论述本身就是许多教科书的主题(例如,[Schwartz 1980]或[Bertsekas 1991]),我们在这里的论述必然是简短的。我们的目标是对错误检测和纠正技术提供的功能有一个直观的感受,并了解一些简单的技术是如何工作的,以及在链路层中是如何实际使用的。
图6.3说明了我们研究的场景。在发送节点,需要防止比特错误的数据D被错误检测和纠正比特(EDC,error-detection and -correction)增强。通常,需要保护的数据不仅包括从网络层向下传输的数据报,还包括链路层的寻址信息、序列号和链路帧头中的其他字段。D和EDC都以链路层帧的形式发送到接收节点。在接收节点,一个比特序列,D'和EDC'被接收。注意:D'和EDC'由于传输中的比特翻转,可能与原来的D和EDC不同。
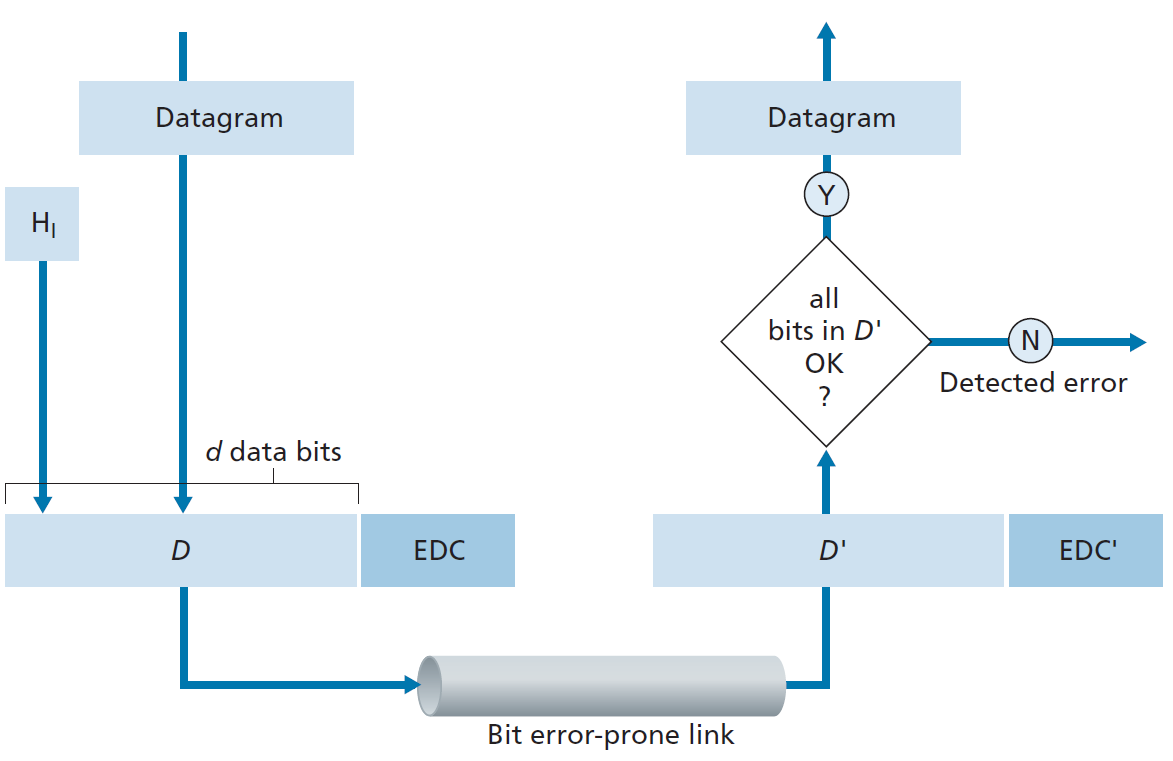
接收方的挑战是确定D'是否和原来的D一样,因为它只收到了D'和EDC'。图6.3中接收方决定的确切措辞(我们询问是否检测到错误,而不是是否发生了错误!)很重要。错误检测和纠正技术允许接收端间或(但并非总是)检测到比特错误的发生。即使使用了错误检测比特,仍然可能存在 未检测到的比特错误 ;也就是说,接收端可能不知道接收到的信息包含比特错误。因此,接收端可能会向网络层发送损坏的数据报,或者不知道帧头中的某个字段的内容已经损坏。因此,我们希望选择一个错误检测方案,使这种发生的概率变小。一般来说,更复杂的错误检测和纠正技术(即允许未检测到比特错误的概率更小的技术)会产生更大的开销——需要更多的计算来计算和传输更多的错误检测和纠正比特。
现在,让我们研究三种用于检测传输数据中的错误的技术——奇偶校验(以说明错误检测和纠正背后的基本思想)、校验和方法(通常在传输层中使用)和循环冗余检查(通常在适配器的链路层中使用)。
6.2.1奇偶校验
也许最简单的错误检测形式是使用单个 奇偶校验位(parity bit) 。假设要发送的信息(图6.4中的D)有d位。在偶数奇偶校验方案中,发送方只需添加一个额外的比特,并选择它的值,使d + 1位(原始信息加上一个奇偶校验位)中的1总数为偶数。对于奇数奇偶校验方案,奇偶校验位值的选择使1的个数为奇数。图6.4演示了一个偶数奇偶校验方案,单个奇偶校验位存储在一个单独的字段中。

接收方的操作也很简单,只有一个奇偶校验位。接收方只需要计算接收到的d + 1位中1的数量。如果在偶数奇偶校验方案中发现值为1的位的个数是奇数,接收端就知道至少有一个比特错误发生了。更准确地说,它知道已经发生了奇数个比特错误。
但是如果出现偶数个比特错误会发生什么呢?您应该说服自己这将导致一个未被发现的错误。如果比特错误的概率很小,并且可以假定比特错误是独立发生的,那么一个数据包中出现多个比特错误的概率就会非常小。在这种情况下,一个奇偶校验位就足够了。然而,测量结果表明,错误不是独立发生的,而是经常聚集在一起。在突发错误条件下,由单比特(single-bit)奇偶校验保护的帧中未被检测到错误的概率可以接近50% [Spragins 1991]。显然,需要一种更健壮的错误检测方案(幸运的是,它已经在实践中使用了!)。但在研究实际应用的错误检测方案之前,让我们思量一个1位奇偶校验的简单概括,它将为我们提供对错误纠正技术的洞察。
图6.5展示了单比特奇偶校验方案的二维推广。这里,d中的d位被分成i行和j列。为每一行和每列计算奇偶校验值。所得到的i + j + 1奇偶校验位构成链路层帧的错误检测位。

假设在原始的d位信息中出现了一个比特错误。在这种二维奇偶校验方案中,包含翻转比特的列和行的奇偶校验都将出错。因此,接收方不仅可以检测单个比特错误已经发生的事实,而且可以使用奇偶校验错误的列和行索引来实际识别损坏的比特和纠正错误!图6.5展示了位置(2,2)中的1位损坏并切换为0的例子——在接收端既可检测又可纠正的一种错误。虽然我们的讨论集中在原始的d位信息上,但奇偶位本身的一个错误也是可检测和纠正的。二维奇偶校验还可以检测(但不是正确的!)数据包中任何两个错误的组合。本章最后的问题探讨了二维奇偶格式的其他性质。
接收方检测错误和纠正错误的能力被称为 前向纠错(FEC,forward error correction) 。这些技术通常用于音频存储和回放设备,如音频cd。在网络环境中,FEC技术可以单独使用,也可以与类似于我们在第三章中研究的链路层ARQ技术结合使用。FEC技术是有价值的,因为它们可以减少发送方重发所需的次数。也许更重要的是,它们允许在接收端立即纠正错误。这就避免了发送端接收NAK数据包和重传数据包传播回接收端所需要的往返传播延迟的等待,对于具有长传播延迟的实时网络应用程序[Rubenstein 1998]或链路(如深空链路)来说,这是一个潜在的重要优势。在错误控制协议中使用FEC的研究包括[Biersack 1992;Nonnenmacher 1998;Byers 1998;Shacham 1990]。
6.2.2校验和方法
在校验和技术中,图6.4中的d位数据被视为k位整数序列。一种简单的校验和方法是简单地对这些k位整数求和,并使用所得的和作为错误检测位。 Internet校验和 基于这种方法——字节数据被视为16位整数并求和。这个和的1补就构成了Internet校验和,在段头中携带。如3.3节所讨论的,接收方通过取接收到的数据之和(包括校验和)的1补,并检查结果是否全部为0位来检查校验和。如果任意一位为1,则表示错误。RFC 1071详细讨论了Internet校验和算法及其实现。在TCP和UDP协议中,对所有字段(包括头和数据字段)计算Internet校验和。在IP中,校验和是通过IP头计算的(因为UDP或TCP段有自己的校验和)。在其他协议中,例如XTP [Strayer 1992],一个校验和是在头上计算的,另一个校验和是在整个数据包上计算的。
校验和方法需要相对较少的数据包开销。例如,TCP和UDP中的校验和只使用16位。但是,与循环冗余校验相比,它们对错误的保护相对较弱,循环冗余校验在下面讨论,通常在链路层使用。在这一点上一个自然的问题是,为什么校验和在传输层使用,而循环冗余校验在链路层使用?回想一下,传输层通常是作为主机操作系统的一部分在软件中实现的。由于传输层错误检测是在软件中实现的,因此具有简单、快速的错误检测方案(如校验和)是非常重要的。另一方面,链路层的错误检测是在适配器中的专用硬件中实现的,可以快速执行更复杂的CRC操作。Feldmeier[Feldmeier 1995]提出了不仅是加权校验和码(weighted checksum codes),而且CRC(见下文)和其他码的快速软件实现技术。
6.2.3循环冗余校验(CRC)
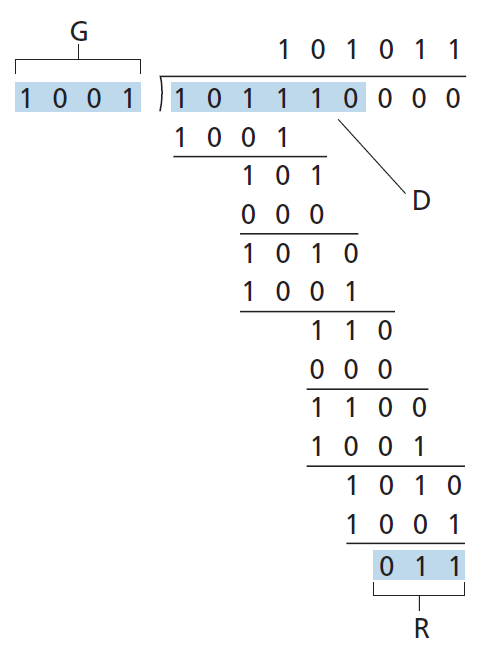
基于 循环冗余校验(CRC)码 的错误检测技术是当今计算机网络中广泛使用的一种错误检测技术。CRC码也称为 多项式码(polynomial codes) ,因为可以将要发送的位串(bit string)视为多项式,其系数为位串中的0和1值,对位串的操作解释为多项式算术。
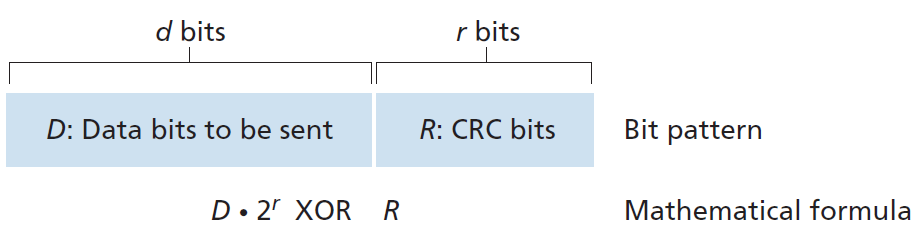
CRC码的操作如下。考虑发送节点想要发送给接收节点的d位数据D。发送方和接收方必须首先在r + 1位型样(bit pattern)上达成一致,被称为 生成器(generator) ,我们将其表示为G。我们将要求G的最高有效(最左)位为1。CRC编码背后的关键思想如图6.6所示。对于一个给定的数据块D,发送端将选择r个额外的位R,并将它们附加到D,这样得到的d + r位型样(解释为一个二进制数)使用modulo-2算法能被G整除(即没有余数)。因此,使用CRC进行错误检查的过程很简单:接收方将接收到的d + r比特除以G,如果余数非零,接收方就知道发生了错误;否则,数据被认为是正确的。
所有CRC计算都采用modulo-2算法,没有加法进位或减法借位。这意味着加法和减法是相同的,并且两者等价于操作数的按位异或(XOR)。因此,例如,
1011 XOR 0101 = 1110
1001 XOR 1101 = 0100
同样,我们也有
1011 - 0101 = 1110
1001 - 1101 = 0100
乘法和除法与以2为底的算术相同,不同的是任何必需的加减运算都不需要进位或借位。在常规的二进制算术中,乘以2k则向左偏移一个位型样k位。因此,给定D和R,量D·2r XOR R产生如图6.6所示的d + r位型样。我们将在下面的讨论中使用图6.6中的d + r位型样的代数描述。
现在,让我们转向关键的问题,发送方如何计算R,回想一下,我们想找到R,使之有一个n满足:
D·2r XOR R = n G
也就是说,我们要选择R使G能除D·2r XOR R而无余数。如果对方程两边异或(即加上modulo-2,不带进位)R,得到:
D·2r = nG XOR R
这个方程告诉我们,如果我们把D·2r除以G,余数的值正好是R。换句话说,我们可以把R计算为:
R = remainder D·2r / G
图6.7说明了D = 101110, d = 6, G = 1001,和r = 3情况下的计算。在这种情况下传输的9位是101 110 011。你应该自己检查这些计算,也检查确实D ·2r = 101011 · G XOR R。
对于8位、12位、16位和32位生成器,G,已经有了国际标准的定义。CRC-32 32位标准已经被许多链路级IEEE协议采用:
GCRC-32 = 100000100110000010001110110110111
每种CRC标准都可以检测到小于r + 1位的突发错误。(这意味着将检测到r位或更少的所有连续的比特错误。)此外,在适当的假设下,检测到长度大于r + 1位的情况,概率为1 - 0.5r。此外,每个CRC标准可以检测任何奇数位的比特错误。参见[Williams 1993]关于实施CRC校验的讨论。CRC码和更强大的码背后的理论超出了本文的范围。文本[Schwartz 1980]对这个主题提供了一个很好的介绍。
6.3多路接入链路与协议
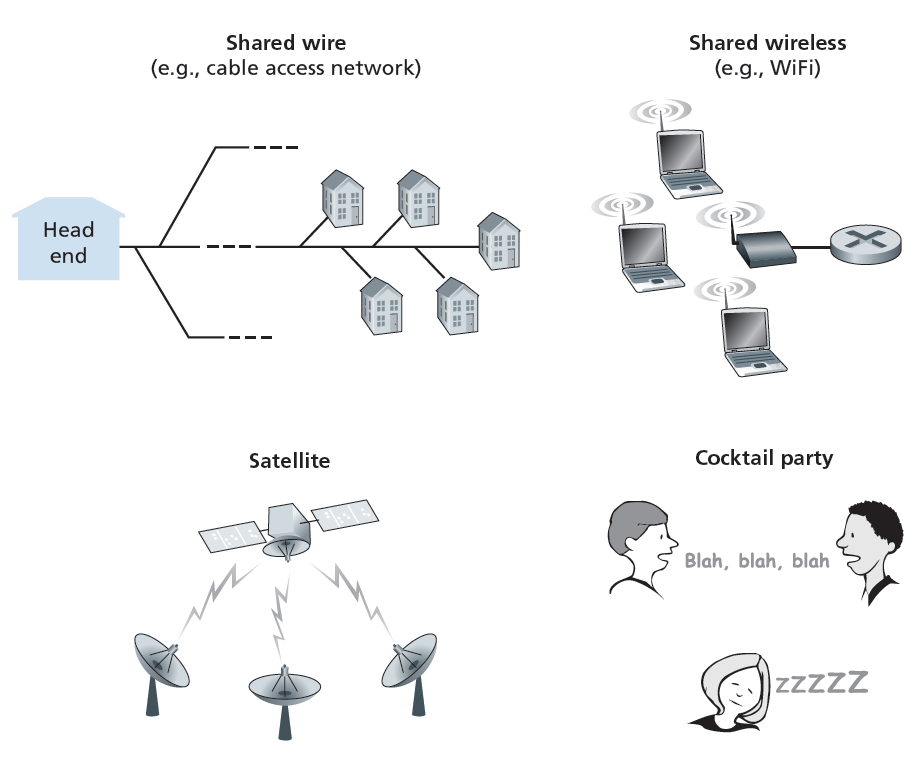
在本章的介绍中,我们注意到网络链路有两种类型:点对点链路和广播链路。 点对点链路 由在链路一端的单个发送方和在链路另一端的单个接收方组成。为点对点链路设计了许多链路层协议;PPP (point-to-point protocol)和HDLC (high-level data link control)就是其中的两种协议。第二种类型的链路是 广播链路 ,可以有多个发送和接收节点连接到同一个、单一的、共享的广播信道。这里使用广播这个术语是因为当任何一个节点传输一个帧时,信道就会广播这个帧,而其他每个节点都会收到一个副本。以太网和无线局域网是广播链路层技术的例子。在本节中,我们将从特定的链路层协议开始,探讨一个对链路层至关重要的问题:如何协调多个发送和接收节点对共享广播信道的接入——即 多路接入问题(multiple access problem) 。广播频道通常用于局域网,这种网络在地理上集中在一栋大楼(或公司或大学校园)。因此,我们将在本节的最后看到如何在局域网中使用多个接入信道。
我们都熟悉广播电视的概念,自从它发明以来就一直在使用。但传统电视是单向广播(即一个固定节点向多个接收节点发送信号),而计算机网络广播信道上的节点既可以发送信号,也可以接收信号。也许对广播频道更贴切的人类类比是鸡尾酒会,许多人聚集在一个大房间里(空气提供广播媒介)交谈和倾听。第二个好的类比是许多读者都熟悉的——教室——教师和学生同样使用单一的广播媒介。这两种方案的一个核心问题是确定谁可以说话(也就是说,传输到信道)以及何时说话。作为人类,我们已经进化出一套详细的协议来共享广播频道:
给每个人一个发言的机会。
没人跟你说话前不要说话。
不要滔滔不绝的交谈。
有问题的请举手。
别人说话时不要插嘴。
不要在别人说话的时候睡着。
计算机网络也有类似的协议,称为 多路接入协议 —— 节点通过它来调节它们进入共享广播信道的传输。如图6.8所示,在各种各样的网络设置中需要多种接入协议,包括有线和无线接入网络,以及卫星网络。虽然从技术上讲,每个节点都通过它的适配器接入广播信道,我们将该节点称为发送和接收设备。实际上,数百甚至数千个节点可以通过广播信道直接通信。
因为所有节点都有传输帧的能力,所以可以有两个以上的节点同时传输帧。当这种情况发生时,所有节点同时接收多个帧;也就是说,传输的帧在所有的接收方 碰撞(collide) 。通常情况下,当发生碰撞时,没有一个接收节点能够理解任何传输的帧;在某种意义上,碰撞帧的信号不可避免地纠缠在一起。因此,在碰撞间隔内,所有涉及到碰撞的帧都将丢失,广播信道被浪费。显然,如果许多节点想要频繁地传输帧,许多传输将导致碰撞,广播信道的大部分带宽将被浪费。
为了确保广播信道在多个节点活动时能执行有用的工作,有必要以某种方式协调活动节点的传输。这项协调工作是多路接入协议的责任。在过去的40年里,有数千篇论文和数百篇博士论文是关于多路接入协议的;[Rom 1990]是对这一工作头20年的全面调查。此外,由于新型链路,特别是新型无线链路的不断出现,对多路接入协议的研究仍在继续。
多年来,在各种链路层技术中已经实现了几十个多路接入协议。尽管如此,我们可以将任何多路接入协议归类为属于以下三类协议之一: 信道分区协议(channel partitioning protocols)、随机接入协议(random access protocols)和轮流接入协议(taking-turns protocols) 。我们将在以下三个小节中介绍这些多路接入协议。
让我们总结一下,理想情况下,速率为每秒R比特的广播信道的多路接入协议应该具有以下理想的特征:
- 当只有一个节点需要发送数据时,该节点的吞吐量为R bps。
- 当M个节点有数据要发送时,每个节点的吞吐量为R/M bps。这并不一定意味着每个节点总是有一个瞬时的R/M速率,而是每个节点在某个适当定义的时间间隔内应该有一个平均的R/M传输速率。
- 协议是去中心化的;也就是说,不存在代表网络单故障点的主节点。
- 该协议很简单,因此实现开销很低。
6.3.1信道分区协议
回想一下我们在1.3节早期的讨论,时分多路复用(TDM)和频分多路复用(FDM)是两种可用于在共享广播信道的所有节点之间划分广播信道带宽的技术。例如,假设信道支持N个节点,信道传输速率为R bps。TDM将时间分为 时间帧(time frames) ,每个时间帧又分为N个 时隙(time slots) 。(TDM时间帧不应与发送和接收适配器之间交换数据的链路层单元(也称为帧)相混淆。为了减少混淆,在本小节中,我们将把交换数据的链路层单元称为数据包。)然后将每个时隙分配给N个节点中的一个。每当一个节点有一个数据包要发送时,它就在循环的TDM帧中分配的时隙中发送数据包。通常,选择时隙大小以便在时隙时间内传输单个数据包。图6.9显示了一个简单的4节点TDM示例。回到我们的鸡尾酒会类比,TDM管理下的鸡尾酒会允许一个派对参与者在一段固定的时间内发言,然后允许另一个派对参与者在相同的时间内发言,以此类推。一旦每个人都有机会交谈,这种模式就会重复。
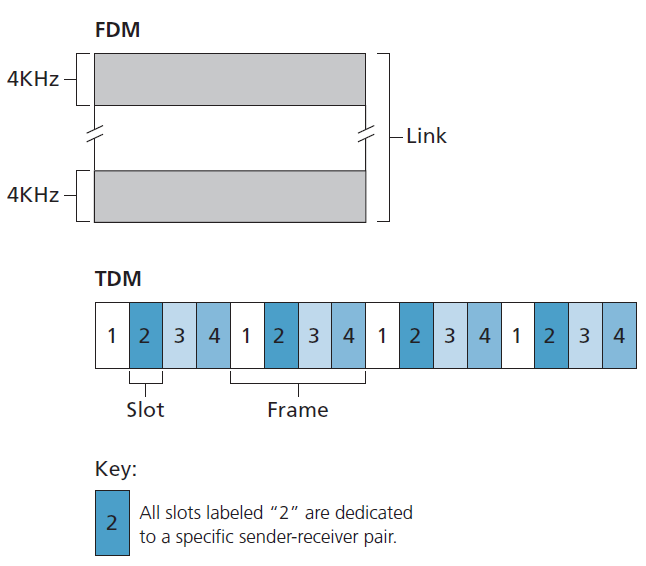
TDM之所以吸引人,是因为它消除了碰撞,而且非常公平:每个节点在每一帧时间内都获得一个专用的R/N bps传输速率。然而,它有两个主要缺点。首先,一个节点被限制在R/N bps的平均速率,即使它是唯一需要发送数据包的节点。第二个缺点是节点必须总是等待它在传输序列中再次轮到它,即使它是唯一一个需要发送帧的节点。想象一下,一个参加派对的人是唯一一个有话要说的人(想象一下,这是一种更罕见的情况,每个人都想听那个人说什么)。显然,对于这一特定群体来说,TDM将是一个糟糕的多路接入协议选择。
TDM在时间上共享广播信道,而FDM将R bps信道分成不同的频率(每个频率的带宽为R/N),并将每个频率分配给N个节点中的一个。因此,FDM从单个大的R bps的信道创建了N个较小的R/N bps的信道。FDM具有TDM的优点和缺点。它避免了碰撞,并在N个节点之间公平分配带宽。然而,FDM与TDM也有一个主要缺点——一个节点的带宽被限制在R/N,即使它是唯一需要发送数据包的节点。
第三种信道分区协议是 码分多路接入(CDMA,code division multiple access) 。TDM和FDM分别为节点分配时隙和频率,CDMA为每个节点分配不同的码。然后,每个节点使用其唯一的码对其发送的数据比特进行编码。如果码选的仔细,那么CDMA网络有一个奇妙的特性,即不同的节点可以同时传输,而且它们各自的接收方可以正确地接收到发送方码的数据比特(假设接收方知道发送方的码),而不受其他节点传输的干扰。CDMA已经在军事系统中使用了一段时间(由于其抗干扰特性),现在已广泛用于民用,特别是蜂窝电话。由于CDMA的使用与无线信道紧密相连,所以有关CDMA的技术细节的讨论将留到第7章。目前,只要知道CDMA码就足够了,就像TDM中的时隙和FDM中的频率一样,可以分配给多路接入信道用户。
6.3.2随机接入协议
第二大类多路接入协议是随机接入协议。在随机接入协议中,传输节点始终以信道的全速率传输,即R bps。当发生碰撞时,每个参与碰撞的节点都会重复重传自己的帧(即数据包),直到自己的帧不发生碰撞通过为止。但是当一个节点发生碰撞时,它并不一定要立即重传帧。相反,它在重传帧之前会等待一个随机的延迟。每个涉及碰撞的节点选择独立的随机延迟。因为随机延迟是独立选择的,有可能其中一个节点会选择一个比其他碰撞节点的延迟足够小的延迟,因此能够在不发生碰撞的情况下偷偷地将它的帧导入信道。
在文献中描述的随机接入协议有几十上百种[Rom 1990;Bertsekas 1991]。在本节中,我们将描述一些最常用的随机接入协议ALOHA协议[Abramson 1970;Abramson 1985;Abramson 2009]和载波感知多路接入(CSMA,carrier sense multiple access)协议[Kleinrock 1975b]。以太网[Metcalfe 1976]是一种流行的、广泛部署的CSMA协议。
时隙ALOHA
让我们以一种最简单的随机接入协议,即时隙ALOHA协议,开始对随机接入协议的研究。在我们对时隙ALOHA的描述中,我们假定如下:
- 所有帧都由L比特组成。
- 时间分为大小为L/R秒的隙(即一个时隙等于发送一帧的时间)。
- 节点只在时隙开始时传输帧
- 节点是同步的,所以每个节点知道时隙何时开始。
- 如果两个或更多的帧在一个时隙内发生碰撞,那么在这个时隙结束之前,所有的节点都会识别到碰撞事件。
设p是一个概率,也就是一个介于0和1之间的数。时隙ALOHA在每个节点上的操作非常简单:
- 当节点有新的帧要发送时,它会等待下一个时隙的开始,然后在这个时隙发送整个帧。
- 如果没有碰撞,则节点已经成功传输了帧,因此不需要考虑重传帧。(节点可以准备一个新的传输帧,如果有的话。)
- 如果发生碰撞,则节点在时隙结束之前检测到碰撞。节点以p的概率在随后的每个时隙重传它的帧,直到帧在传输时没有碰撞。
通过概率为p的重传,我们的意思是该节点有效地投掷了一枚有偏向的硬币;人头事件对应重传,重传发生的概率为p。国徽事件对应跳过这个时隙,在下一个时隙中再次抛硬币;这发生的概率为(1 - p),所有参与碰撞的节点各自独立地投掷硬币。
时隙ALOHA似乎有很多优点。与信道分区不同,时隙ALOHA允许节点以全速率R连续传输,当该节点是唯一活动节点时。(如果一个节点有帧要发送,它就被称为活动节点。)时隙ALOHA也是高度分散的,因为每个节点检测碰撞并独立决定何时重传。(然而,时隙ALOHA确实要求时隙在节点中同步;稍后我们将讨论非时隙版本的ALOHA协议,以及CSMA协议,它们都不需要这样的同步。)时隙ALOHA也是一个非常简单的协议。
当只有一个活动节点时,时隙ALOHA工作得很好,但当有多个活动节点时,它的效率如何?这里有两个可能的效率问题。首先,如图6.10所示,当有多个活动节点时,一定比例的时隙会发生碰撞,因此会被浪费。第二个问题是另一部分时隙将是空的,因为所有活动节点都避免传输,这是概率传输策略的结果。唯一未浪费的时隙将是那些只有一个节点传输的时隙。恰好有一个节点进行传输的时隙被称为 成功时隙 。当有大量的活动节点,每个节点总是有大量的帧要发送时,时隙多路接入协议的 效率 被定义为成功时隙的长期运行比例。注意,如果不使用任何形式的接入控制,并且每个节点在每次碰撞后都要立即重新传输,那么效率将为零。时隙ALOHA明显提高了效率,但提高了多少?
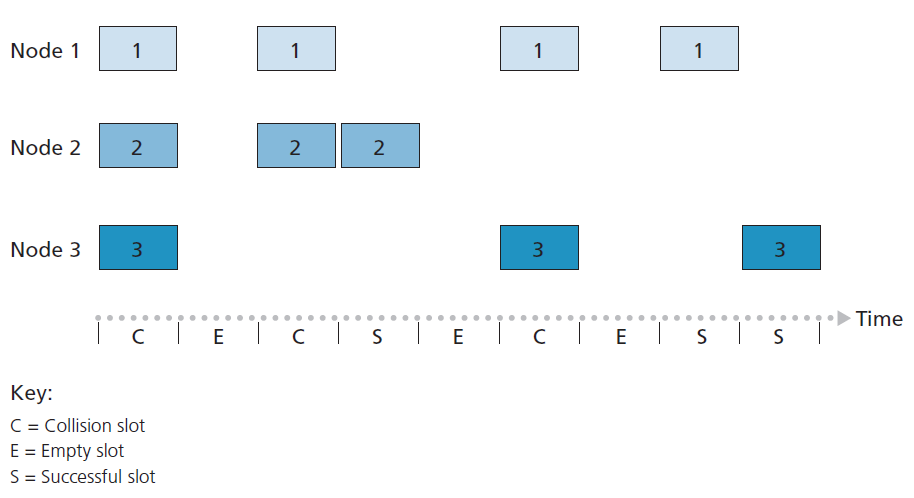
现在,我们来大致推导时隙ALOHA的最大效率。为了简化这个推导,让我们稍微修改一下协议,假设每个节点在每个时隙尝试传输一帧,概率为p(也就是说,我们假设每个节点总是有一帧要发送,节点传输新帧和已经发生碰撞的帧的概率为p)。假设有N个节点。那么,一个给定时隙成功的概率就是其中一个节点传输而其余N - 1个节点不传输的概率。给定节点传输的概率为p;剩余节点不转发的概率为(1 - p)N-1。因此,给定节点成功的概率为p(1 - p)N-1。因为有N个节点,这N个节点中任何一个成功的概率是Np(1 - p)N-1。
因此,当有N个活动节点时,时隙ALOHA的效率为Np(1 - p)N-1。为了获得N个活动节点的最大效率,我们必须找到使这个表达式最大化的 p* (请参阅作业问题了解这个推导过程的大致轮廓。)为了获得大量活动节点的最大效率,我们取N趋于无穷时Np*(1 - p*) N-1的极限。(还是看作业上的问题。)执行这些计算后,我们将发现协议的最大效率为1/e = 0.37。也就是说,当大量节点有许多帧要传输时,(最多)只有37%的时隙做有用的工作。因此,该信道的有效传输速率不是R bps,而是0.37 R bps!类似的分析还显示,37%的时隙是空的,26%的时隙有碰撞。想象一下,一个可怜的网络管理员购买了一个100mbps的时隙ALOHA系统,期望能够使用网络在大量用户之间以聚合速率(比如80mbps)传输数据!尽管该信道能够以100 Mbps的全信道速率传输给定的帧,但从长远来看,该信道的成功吞吐量将小于37 Mbps。
ALOHA
时隙ALOHA协议要求所有节点同步它们的传输,以便在时隙的开始位置开始。第一个ALOHA协议[Abramson 1970]实际上是一个非时隙的、完全分散的协议。在纯ALOHA中,当一帧第一次到达时(即从发送节点的网络层向下传递网络层数据报),该节点立即将帧的全部传输到广播信道中。如果一个传输的帧与一个或多个传输发生碰撞,节点将立即(在完全传输完它的碰撞帧后)以p的概率重传该帧。否则,节点将等待一个帧传输时间。等待之后,它以p的概率发送帧,或者以1 - p的概率等待(保持空闲)另一帧时间。
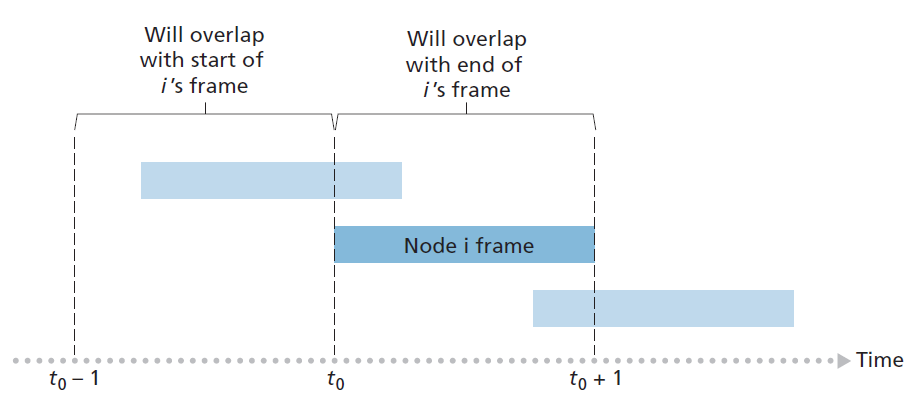
为了确定纯ALOHA的最大效率,我们关注单个节点。我们将做出与时隙ALOHA分析相同的假设,并以帧传输时间为时间单位。在任意给定时间,节点正在传输一帧的概率为p。假设该帧在t0开始传输。如图6.11所示,为了使该帧传输成功,在[t0 - 1, t0]时间间隔内,没有其他节点开始传输。但这样的传输将与节点i的帧传输的开始部分重叠。所有其他节点在此间隔内未开始传输的概率为(1 - p)N-1。同样,当节点i正在传输时,没有其他节点可以开始传输,因为这样的传输将与节点i传输的后半部分重叠。所有其他节点在此间隔内没有开始传输的概率也是(1 - p)N-1。因此,给定节点成功传输的概率为p(1 - p)2(N-1)。通过在时隙ALOHA情况下取极限,我们发现纯ALOHA协议的最大效率仅为时隙ALOHA的1/(2e)恰好是它的一半。这就是完全去中心化的ALOHA协议所要付出的代价。
CSMA
在时隙ALOHA和纯ALOHA中,节点的传输决定是独立于附加在广播信道上的其他节点的活动做出的。具体来说,当一个节点开始传输时,它不关注另一个节点是否恰好在传输,当另一个节点开始干扰它的传输时,它也不停止传输。在我们的鸡尾酒派对类比中,ALOHA协议很像一个粗鲁的派对参与者,他继续喋喋不休,不管其他人是否在说话。作为人类,我们有人类的协议,它不仅允许我们表现得更有礼貌,而且还减少了在对话中花费在彼此碰撞上的时间,从而增加了我们在对话中交换的数据量。具体来说,有两个重要的规则,礼貌的人类对话:
- 说话之前倾听 如果有人在讲话,等他们说完。在网络世界中,这被称为 载波感知(carrier sensing) ——一个节点在传输之前监听信道。如果当前正在传输来自另一个节点的帧到信道中,那么这个节点会等待,直到它在短时间内检测到没有传输,然后开始传输。
- 如果另一个人在同一时间开始说话,停止说话 在网络世界中,这被称为 碰撞检测(collision detection) ——传输节点在传输时监听信道。如果它检测到另一个节点正在传输干扰帧,它会停止传输,并随机等待一段时间,然后重复“空闲-感知-传输”的周期。
这两个规则体已嵌入到 CSMA 和带有碰撞检测的 CSMA/CD(CSMA with collision detection) 协议系列中[Kleinrock 1975b; Metcalfe 1976; Lam 1980; Rom 1990]。已经被提出了CSMA和CSMA/CD的许多变种。在这里,我们将考虑CSMA和CSMA/CD的一些最重要、最基本的特性。
关于CSMA,你可能会问的第一个问题是,如果所有节点都进行载波感知,第一次碰撞会发生吗?毕竟,当一个节点感知到另一个节点正在传输数据时,它就会停止传输数据。这个问题的答案可以用时空图来说明[Molle 1987]。图6.12显示了连接在线性广播总线(linear broadcast bus)上的四个节点(A、B、C、D)的时空图。横轴表示每个节点在空间中的位置;纵轴表示时间。
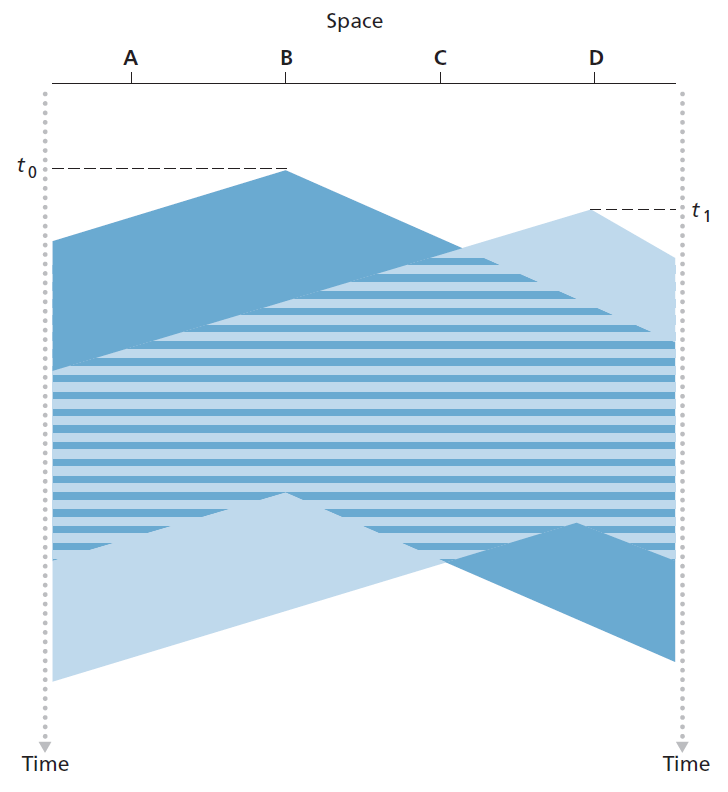
在时间为t0时,节点B感知到信道空闲,因为目前没有其他节点在传输。因此,节点B开始传输,它的比特沿着广播介质向两个方向传播。图6.12中B的比特随着时间的增加向下传播,表明B的比特在广播介质中实际传播(尽管接近光速)需要非零的时间。在t1时刻(t1 > t0),节点D有一个帧要发送。虽然节点B目前在t1传输,但B传输的比特还没有到达D,因此,D感知到信道在t1时空闲。根据CSMA协议,D开始传输它的帧。一段时间后,B的传输开始干扰D的传输。从图6.12可以明显看出广播信道的端到端 信道传播延迟 ——信号从一个节点传播到另一个节点所花费的时间——将在决定其性能方面发挥关键作用。这种传播延迟越长,载波感知节点还不能感知网络中另一个节点已经开始的传输的机会就越大。
NORM ABRAMSON 和 ALOHANET
Norm Abramson是一名工程师博士,他酷爱冲浪,对数据包交换也很感兴趣。这些共同的兴趣使他于1969年来到夏威夷大学。夏威夷由许多多山的岛屿组成,因此很难安装和操作陆基网络。不能上网的时候,Abramson想到了如何设计一个在无线电上进行数据包交换的网络。他设计的网络有一个中央主机和几个次要节点,分散在夏威夷群岛上。该网络有两个频道,每个频道使用不同的频段。下行信道将数据包从中央主机广播到辅助主机;上行信道将从辅助主机发送的数据包发送到中央主机。除了发送数据包外,中央主机还在下行信道上对从辅助主机成功接收到的每个数据包发送一个确认信息。
由于辅助主机以非中心化的方式传输数据包,因此上行信道不可避免地会发生碰撞。这一观察结果促使Abramson设计了纯ALOHA协议,如本章所述。1970年,在ARPA的持续资助下,Abramson将他的ALOHAnet与ARPA网络连接起来。Abramson的工作之所以重要,不仅是因为他是无线数据包网络(radio packet network)的第一个例子,还因为他启发了Bob Metcalfe。几年后,Metcalfe修改了ALOHA协议,创建了CSMA/CD协议和以太网局域网。
CSMA/CD
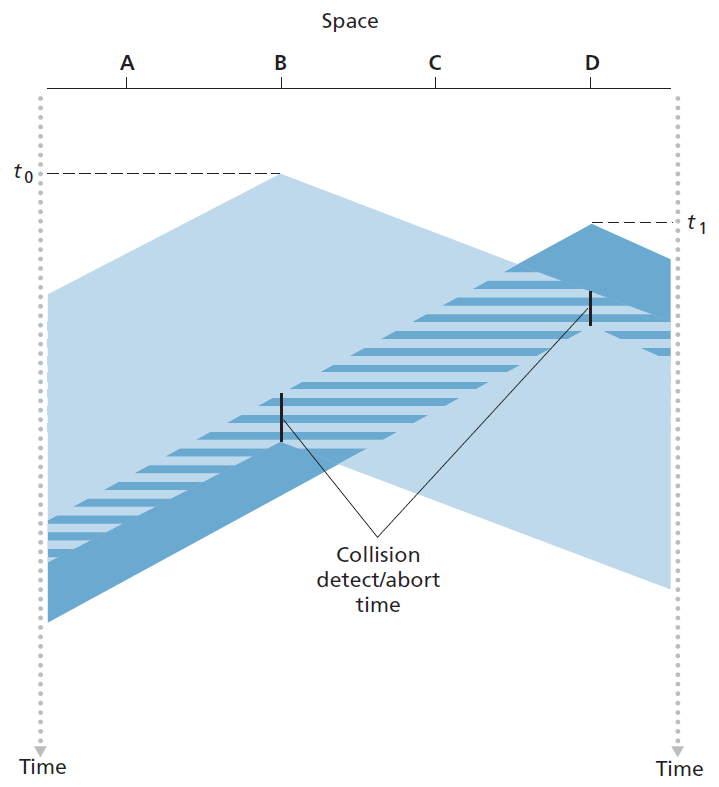
在图6.12中,节点不进行碰撞检测;即使发生了碰撞,B和D仍然继续完整地传输它们的帧。当节点执行碰撞检测时,一旦检测到碰撞,它就会立即停止传输。图6.13显示了与图6.12相同的场景,不同的是,两个节点在检测到碰撞后都在短时间内中止传输。显然,在多路接入协议中加入碰撞检测将有助于协议的性能,因为它不会完整地传输无用的、损坏的(由于对来自另一个节点的帧的干扰)帧。
在分析CSMA/CD协议之前,现在让我们从连接到广播信道的适配器(在节点中)的角度来总结它的操作:
- 适配器从网络层获取数据报,准备链路层帧,并放置帧适配器缓冲区。
- 如果适配器感知到信道是空闲的(也就是说,没有信号能量从信道进入适配器),它就开始传输帧。另一方面,如果适配器感知到信道繁忙,它会等待,直到没有信号能量(signal energy),然后开始传输帧。
- 在传输时,适配器监测来自使用广播信道的其他适配器的信号能量的存在。
- 如果适配器传输整个帧而没有检测到来自其他适配器的信号能量,则适配器结束该帧。另一方面,如果在传输时,适配器检测到来自其他适配器的信号能量,它就会中止传输(也就是说,它停止传输它的帧)。
- 中止之后,适配器会随机等待一段时间,然后返回到步骤2。
需要等待的随机时间(而不是固定时间)很有可能是明确的——如果两个节点同时传输帧,并且等待相同的固定时间,它们将永远继续碰撞。但是,选择随机回退时间的最佳时间间隔是什么?如果间隔较大且碰撞节点数量较少,节点可能会等待大量时间(信道保持空闲),然后才重复空闲-感知-传输步骤。另一方面,如果间隔小,而碰撞节点数量大,则很有可能选择的随机值几乎相同,传输节点再次碰撞。我们想要的是一个间隔,当碰撞节点的数量很小时很短,当碰撞节点的数量很大时很长。
在以太网和DOCSIS电缆网络多路接入协议[DOCSIS 3.1 2014]中使用的 二进制指数回退(binary exponential backoff) 算法,优雅地解决了这个问题。具体来说,当传输一个已经发生n次碰撞的帧时,节点从{0,1,2,. . . .2n - 1}中随机选择K的值。因此,帧经历的碰撞越多,K的选择间隔就越大。对于以太网,节点等待的实际时间是k · 512比特的倍数(即K乘以512比特发送到以太网所需的时间),n所能获得的最大值为10。
让我们来看一个例子。假设一个节点第一次尝试传输一个帧,并且在传输过程中检测到一个碰撞。然后节点以0.5的概率选择K = 0或以0.5的概率选择K = 1。如果节点选择K = 0,那么它立即开始感知信道。如果节点选择K = 1,它将等待512比特时间(例如,对于100 Mbps以太网,等待5.12微秒),然后才开始空闲-感知-传输周期。在第二次碰撞后,从{0,1,2,3}中以相等概率选择K。经过三次碰撞后,从{0,1,2,3,4,5,6,7}中以相等概率选择K。在10次或更多的碰撞后,K以相等的概率从{0,1,2,…1023}中选择。因此,选择K的集合的大小随碰撞次数呈指数增长;因此,这种算法被称为二进制指数后退算法。
我们还注意到,每次节点准备传输新帧时,它都会运行CSMA/CD算法,而不会考虑最近可能发生的任何碰撞。因此,当其他几个节点处于指数回退状态时,具有新帧的节点可能立即能够偷偷地成功传输。
CSMA / CD的效率
当只有一个节点发送帧时,该节点可以以全信道速率传输(例如,以太网的典型速率为10mbps、100mbps或1Gbps)。但是,如果有很多节点传输帧,信道的有效传输速率就会大大降低。我们将 CSMA/CD的效率 定义为:当有大量活动节点(每个节点都有大量的帧要发送)时,在信道上传输帧时不发生碰撞的运行时间分数。为了给出一个以太网效率的封闭式近似(closed-form approximation),让dprop表示信号能量在任意两个适配器之间传播所需的最大时间。设dtrans为传输最大帧的时间(对于10mbps以太网约为1.2毫秒)。CSMA/CD的效率推导超出了本书的范围(参见[Lam 1980]和[Bertsekas 1991])。这里我们简单地陈述以下近似:
Efficiency = 1 / (1 + 5dprop/dtrans)
从这个公式可以看出,当dprop趋于0时,效率趋于1。这与我们的直觉相吻合,即如果传播延迟为零,碰撞节点将立即终止,而不会浪费信道。此外,当dtrans变得非常大时,效率接近1。这也很直观,因为当一个帧抓住信道时,它会在很长一段时间内占用信道,因此,信道大部分时间都在做有效的工作。
6.3.3轮流接入协议
请记住,多路接入协议的两个理想属性是(1)当只有一个节点是活动的,活动节点有R bps的吞吐量,当M节点活跃时(2),然后每个活动节点都有接近R / M bps的吞吐量。ALOHA和CSMA协议有第一个属性,但没有第二个属性。这促使研究人员创建了另一种协议—— 轮流接入协议 。与随机接入协议一样,有几十种轮流接入协议,而且每一种协议都有许多变体。我们将在这里讨论两个较重要的协议。第一个是 轮询协议(polling protocol) 。轮询协议要求将其中一个节点指定为主节点。主节点以循环(round-robin)的方式轮询每个节点。具体来说,主节点首先向节点1发送一条消息,表示它(节点1)可以发送的最大帧数的一些。节点1发送完一些帧后,主节点告诉节点2它(节点2)可以发送的最大帧数。(主节点可以通过观察信道上缺失信号来确定一个节点何时完成了帧的发送。)这个过程以这种方式继续,主节点以循环的方式轮询每个节点。
轮询协议消除了困扰随机接入协议的碰撞和空槽。这允许轮询实现更高的效率。但它!也有一些缺点。第一个缺点是该协议引入了轮询延迟——通知一个节点它可以传输所需的时间。例如,如果只有一个节点是活动的,那么该节点的传输速率将小于R bps,因为每当活动节点发送其最大帧数时,主节点必须轮流轮询每个不活动的节点。第二个缺点可能更严重,即如果主节点失败,整个信道就会失效。我们将在7.3节中学习的蓝牙协议,它是一个轮询协议的例子。
第二个轮流接入协议是 令牌传递协议(token-passing protocol) 。在该协议中没有主节点。一个被称为 令牌 的小的、特殊用途的帧以某种固定的顺序在节点之间交换。例如,节点1可能总是将令牌发送给节点2,节点2可能总是将令牌发送给节点3,节点N可能总是将令牌发送给节点1。当一个节点接收到一个令牌时,只有当它有一些帧要传输时,它才会保留这个令牌;否则,它将立即将令牌转发到下一个节点。如果一个节点在接收到令牌时确实有帧要传输,它会发送最大帧数,然后将令牌转发给下一个节点。令牌传递是分散且高效的。但它也有它的问题。例如,一个节点的故障可能导致整个信道崩溃。或者,如果一个节点意外地忽略了释放令牌,那么必须调用一些恢复过程来让令牌回到循环中。多年来,已经开发了许多令牌传递协议,包括光纤分布式数据接口(FDDI,fiber distributed data interface)协议[Jain 1994]和IEEE 802.5令牌环协议[IEEE 802.5 2012],每个协议都必须解决这些以及其他棘手的问题。
6.3.4 DOCSIS:电缆Internet接入的链路层协议
在前面的三小节中,我们已经了解了多路接入协议的三大类:信道分区协议、随机接入协议和轮流接入协议。在这里,有线接入网将是一个很好的研究案例,因为我们将在有线接入网中找到这三类多路接入协议的各个方面 !
回顾第1.2.1节,电缆接入网络通常将数千个家用电缆调制解调器连接到电缆网络头端的电缆调制解调器终端系统(CMTS)。电缆数据服务接口规范(DOCSIS) [DOCSIS 3.1 2014;Hamzeh 2015]指定了电缆数据网络架构及其协议。DOCSIS利用FDM将下行网段(CMTS到modem)和上行网段(modem到CMTS)划分为多个频率信道。每个下行信道在24 MHz和192 MHz之间,每个信道的最大吞吐量约为1.6 Gbps;每个上行信道的信道宽度从6.4 MHz到96 MHz,最大上行吞吐量约为1 Gbps。每个上行和下行信道都是一个广播信道。所有接收该信道的电缆调制解调器接收由CMTS在下行信道上传输的帧;由于只有一个CMTS传输到下行信道,因此不存在多路接入问题。然而,上游方向更有趣,在技术上更具挑战性,因为多个电缆调制解调器共享同一上游信道(频率)到CMTS,因此可能会发生碰撞。
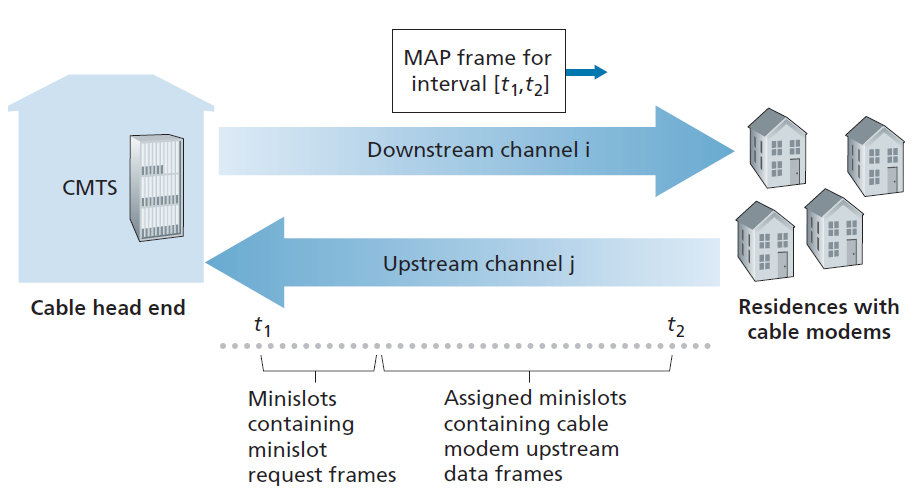
如图6.14所示,每个上行信道被划分为时间间隔(类似于TDM),每个信道包含一系列的时隙(mini-slots),在此期间电缆调制解调器可以向CMTS传输数据。CMTS明确地授予个别电缆调制解调器在特定的时隙传输的权限。CMTS通过在下行信道上发送一个称为MAP消息的控制消息来实现这一点,该消息指定在控制消息中指定的时间间隔内,哪个电缆调制解调器(带有要发送的数据)可以在哪个时隙中传输。由于时隙明确分配给电缆调制解调器,CMTS可以确保在时隙期间没有碰撞传输。
但是CMTS如何知道哪些有线调制解调器有数据要发送呢?这是通过让电缆调制解调器在专用于此目的的一组时隙间隔期间向CMTS发送时隙请求(mini-slot-request)帧来完成的,如图6.14所示。这些时隙请求帧以随机接入的方式传输,因此可能会相互碰撞。电缆调制解调器既不能感知上行信道是否繁忙,也不能检测碰撞。相反,电缆调制解调器推断,如果它在下一个下行控制消息中没有收到对请求分配的响应,则它的时隙请求帧经历了碰撞。当推断出碰撞时,电缆调制解调器使用二进制指数回退来延迟它的时隙请求帧的重传到未来的时隙。当上行信道上的流量很少时,电缆调制解调器实际上可以在名义上分配给时隙请求帧的时隙中传输数据帧(从而避免等待时隙分配)。
因此,有线接入网是多路接入协议的一个很好的例子——FDM、TDM、随机接入和集中分配的时隙都在一个网络中。
6.4 交换式局域网
在前一节中已经介绍了广播网络和多种接入协议,现在让我们把注意力转向交换式本地网络。图6.15显示了一个交换式局域网连接三个部门,两台服务器和一台路由器,四个交换机。因为这些交换机工作在链路层,它们交换链路层帧(而不是网络层数据报),不识别网络层地址,不要使用像OSPF这样的路由算法来确定路径!通过二层交换机组网。我们很快就会看到,它们不是使用IP地址,而是使用链路层地址在交换机网络中转发链路层帧。我们将通过先介绍链路层寻址(第6.4.1节)来开始我们对交换式局域网的研究。然后我们研究著名的以太网协议(第6.4.2节)。在研究了链路层寻址和以太网之后,我们将看看链路层交换机是如何工作的(第6.4.3节),然后参阅(第6.4.4节)这些交换机通常是如何用于建立大规模局域网的。
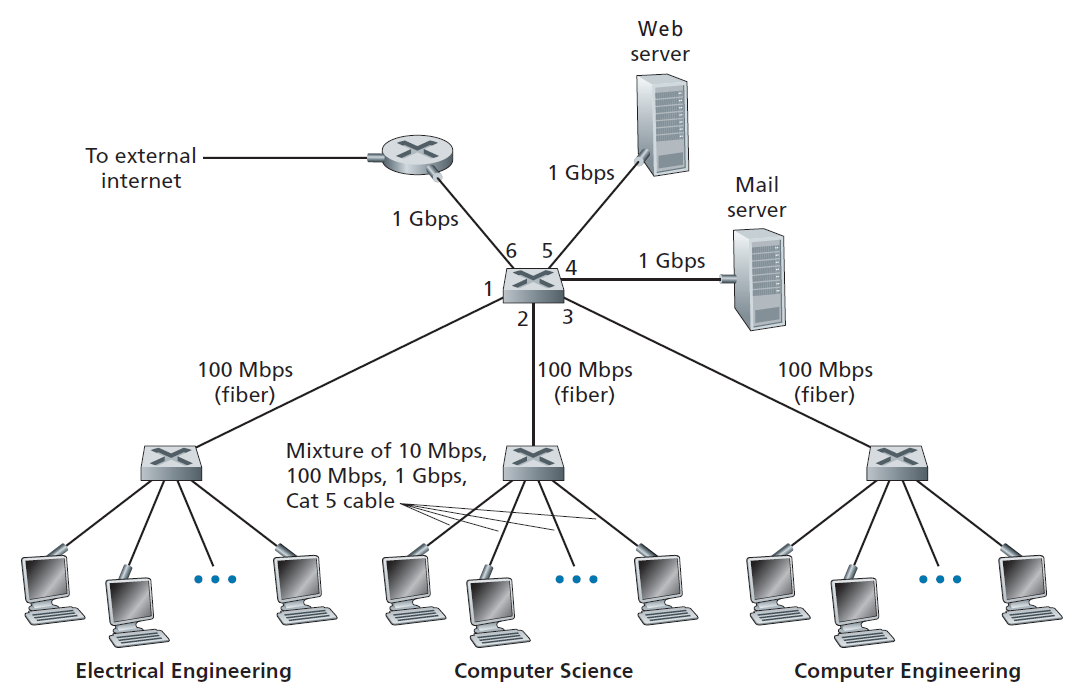
6.4.1链路层寻址和ARP
主机和路由器有链路层地址。回顾第四章,主机和路由器也有网络层地址,你可能会感到惊讶。您可能会问,为什么我们需要在网络层和链路层都有地址呢?除了描述链接层地址的语法和功能之外,在本节中,我们希望阐明为什么这两层地址是有用的,事实上是必不可少的。我们还将介绍地址解析协议(ARP,Address Resolution Protocol),它提供了一种将IP地址转换为链路层地址的机制。
MAC地址
实际上,不是主机和路由器具有链路层地址,而是它们的适配器(即网络接口)具有链路层地址。因此,具有多个网络接口的主机或路由器将具有多个相关联的链路层地址,就像它也将具有多个相关联的IP地址一样。但是,需要注意的是,链路层交换机没有与它们连接主机和路由器的接口相关联的链路层地址。这是因为链路层交换机的工作是在主机和路由器之间传送数据报;交换机透明地完成这项工作,也就是说,主机或路由器不必显式地将帧定位到其间的交换机。如图6.16所示。链路层地址可以被称为 局域网地址 、 物理地址 或 MAC地址 。因为MAC地址似乎是最流行的术语,所以我们今后将把链路层地址称为MAC地址。对于大多数局域网(包括以太网和802.11无线局域网),MAC地址是6字节长,提供248 个可能的MAC地址。如图6.16所示,这些6字节的地址通常用十六进制表示法表示,地址的每个字节用一对十六进制数表示。虽然MAC地址是永久性的,但现在可以通过软件更改适配器的MAC地址。但是,在本节的其余部分中,我们将假设适配器的MAC地址是固定的。
MAC地址的一个有趣属性是没有两个适配器具有相同的地址。考虑到适配器在许多国家由许多公司生产,这似乎令人惊讶。在台湾生产适配器的公司如何确保它使用的地址与在比利时生产适配器的公司不同?答案是IEEE管理MAC地址空间。特别是,当一个公司想要制造适配器时,它会以象征性的费用购买一大块由224个地址组成的地址空间。IEEE分配224个地址的方式是固定MAC地址的前24位,并让公司为每个适配器创建后24位的独特组合。
适配器的MAC地址具有扁平结构(与层次结构相反),无论适配器到哪里都不会改变。有以太网接口的笔记本电脑无论到哪里都有相同的MAC地址。带有802.11接口的智能手机无论到哪里都有相同的MAC地址。回想一下,与此相反,IP地址具有层次结构(即,一个网络部分和一个主机部分),当主机移动时,主机的IP地址需要更改,即更改它所连接的网络。适配器的MAC地址类似于一个人的身份证号码,它也有一个平面地址结构,无论这个人去哪里都不会改变。IP地址类似于人的邮政地址,具有层次结构,只要移动就必须更改。就像一个人可能发现同时拥有邮政地址和身份证号码很有用一样,主机和路由器接口同时拥有网络层地址和MAC地址也很有用。
当一个适配器向某个目标适配器发送帧时,发送适配器会在帧中插入目标适配器的MAC地址,然后将帧发送到局域网。我们很快就会看到,交换机偶尔会将传入的帧广播到所有的接口上。我们将在第7章中看到802.11也广播帧。因此,一个适配器可能接收到一个不是针对它的帧。因此,当一个适配器接收到一个帧时,它将检查帧中的目标MAC地址是否与它自己的MAC地址匹配。如果匹配,适配器提取所包含的数据报,并将数据报向上传递到协议栈。如果没有匹配,适配器将丢弃帧,而不向上传递网络层数据报。因此,只有当接收到帧时,目的地才会被中断。
然而,有时发送适配器确实希望局域网上的所有其他适配器接收和处理它将要发送的帧。在这种情况下,发送适配器将一个特殊的MAC广播地址插入帧的目标地址字段。对于使用6字节地址的局域网(如以太网、802.11),广播地址是连续48个1的字符串(即FF-FF-FF-FF-FF-FF,十六进制格式)。
ARP
由于同时存在网络层地址(例如,Internet IP地址)和链路层地址(即MAC地址),因此需要在它们之间进行转换。对于互联网来说,这是地址解析协议(ARP) [RFC 826]的工作。
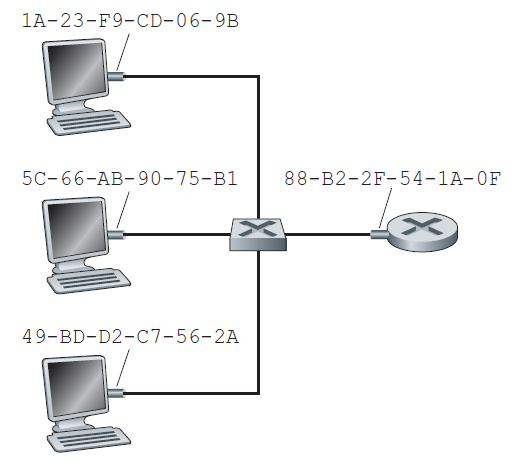
要理解对ARP等协议的需求,请考虑图6.17所示的网络。在这个简单的例子中,每个主机和路由器都有一个单独的IP地址和MAC地址。像往常一样,IP地址以点分十进制表示,MAC地址以十六进制表示。出于讨论的目的,我们将在本节中假设交换机广播所有帧;也就是说,当交换机接收到一个接口上的帧时,它就会把这个帧转发到所有其他接口上。在下一节中,我们将更准确地解释交换机的工作原理。
实践原则: 保持层的独立性
除了网络层地址之外,主机和路由器接口还拥有MAC地址的原因有很多。首先,局域网是为任意的网络层协议设计的,而不仅仅是为IP和互联网设计的。如果分配给适配器的是IP地址而不是中立的MAC地址,那么适配器就不容易支持其他网络层协议(例如,IPX或DECnet)。第二,如果适配器要使用网络层地址而不是MAC地址,网络层地址就必须存储在适配器RAM中,并在每次适配器移动(或启动)时重新配置。另一种选择是在适配器中不使用任何地址,并让每个适配器将它接收到的每一帧的数据(通常是IP数据报)向上传递给协议栈。然后网络层可以检查匹配的网络层地址。这个选项的一个问题是,在局域网上发送的每一帧都会中断主机,包括发送给同一广播局域网上其他主机的帧。总之,为了使层在网络体系结构中成为很大程度上独立的构建块,不同的层需要有自己的寻址方案。我们现在已经看到了三种类型的地址:应用层的主机名、网络层的IP地址和链路层的MAC地址。
现在假设IP地址为222.222.222.220的主机想要向主机222.222.222.222发送一个IP数据报。在本例中,按照4.3.3节的寻址意义,源和目标都在同一个子网中。要发送一个数据报,源不仅要给其适配器IP数据报,还要给它目标地址222.222.222.222的MAC地址。然后,发送适配器将构造一个包含目的地MAC地址的链路层帧,并将该帧发送到局域网。
在本节中讨论的重要问题是,发送主机如何确定IP地址为222.222.222.222的目标主机的MAC地址?您可能已经猜到了,它使用的是ARP。发送主机中的ARP模块以同一局域网中的任意IP地址作为输入,并返回相应的MAC地址。在本例中,发送主机222.222.222.220为其ARP模块提供了IP地址222.222.222.222,ARP模块返回对应的MAC地址49-BD-D2-C7-56-2A。
我们看到ARP将IP地址解析为MAC地址。在许多方面,它类似于DNS(第2.5节研究过),它将主机名解析为IP地址。然而,这两种解析器之间的一个重要区别是,DNS为Internet上任何地方的主机解析主机名,而ARP仅为同一子网中的主机和路由器接口解析IP地址。如果加利福尼亚的一个节点试图使用ARP来解析密西西比的一个节点的IP地址,ARP将返回一个错误。
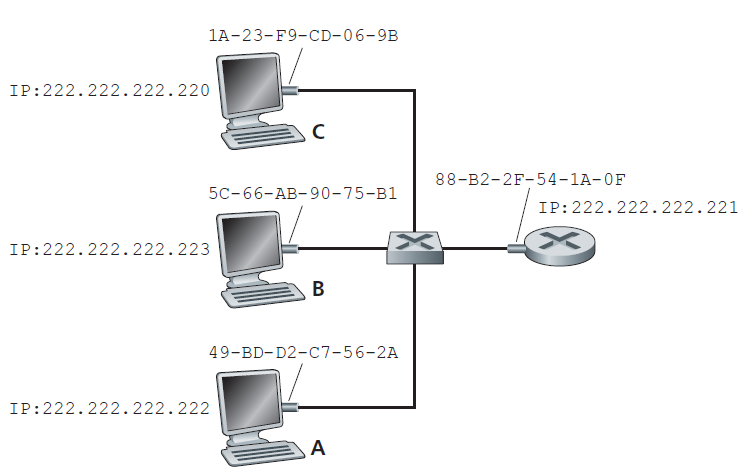
222.222.222.220中可能的ARP表:
| IP地址 | MAC地址 | TTL |
|---|---|---|
| 222.222.222.221 | 88-B2-2F-54-1A-0F | 13:45:00 |
| 222.222.222.223 | 5C-66-AB-90-75-B1 | 13:52:00 |
既然我们已经解释了ARP的功能,让我们看看它是如何工作的。每台主机和路由器的内存中都有一张 ARP表 ,该表包含了IP地址到MAC地址的映射关系。图6.18显示了主机222.222.222.220中的ARP表可能是什么样子的。ARP表中还包含一个TTL (time-to-live)值,用来表示每个映射从表中删除的时间。注意,一个表不一定包含子网中每个主机和路由器的表项;有些可能从未被输入到表中,有些可能已经过期。表项的过期时间一般为放进ARP表后20分钟。
现在假设主机222.222.222.220想要发送一个IP地址为该子网上另一个主机或路由器的数据报。发送主机需要根据IP地址获取目的地址的MAC地址。如果发送端ARP表中有目的节点的表项,则此任务很简单。但是,如果ARP表目前没有目的地的表项怎么办?特别地,假设222.222.222.220想要向222.222.222.222发送一个数据报。此时,发送端使用ARP协议来解析地址。首先,发送方构造一个特殊的数据包,称为 ARP数据包 。ARP数据包包含多个字段,包括发送IP地址、接收IP地址、MAC地址。ARP查询数据包和响应数据包的格式相同。ARP查询数据包的目的是查询子网内所有其他的主机和路由器,以确定正在解析的IP地址对应的MAC地址。
回到我们的例子,222.222.222.220将一个ARP查询数据包传递给适配器,并指示适配器应该将该数据包发送到MAC广播地址,即FF-FF-FF-FF-FF-FF-FF。适配器将ARP数据包封装在链路层帧中,以广播地址作为帧的目标地址,将帧发送到子网中。回想一下我们的身份证号码/邮政地址的类比,一个ARP查询就相当于一个人在某个公司(比如AnyCorp)拥挤的隔间中大喊:邮政地址为Cubicle 13, Room 112, AnyCorp, Palo Alto, California的谁身份证号码是多少?包含ARP查询的帧被子网上的所有其他适配器接收,并且(由于广播地址)每个适配器将帧内的ARP数据包传递给它的ARP模块。每个ARP模块都检查自己的IP地址是否与ARP数据包中的目标IP地址匹配。如果匹配,则返回给查询主机一个包含所需映射的响应ARP数据包。查询主机222.222.222.220可以更新自己的ARP表并发送自己的IP数据报,数据报封装在链路层帧中,目标MAC为前面ARP查询的主机或路由器的MAC。
关于ARP协议,有一些有趣的事情需要注意。首先,查询ARP数据包是在广播帧内发送的,而响应ARP数据包是在标准帧内发送的。在阅读之前,你应该思考一下为什么会这样。其次,ARP是即插即用的;也就是说,ARP表是自动生成的——不需要由系统管理员配置。如果主机与子网断开连接,它的表项最终会从子网中的其他ARP表中删除。
学生们经常想知道ARP是链路层协议还是网络层协议。正如我们所看到的,ARP包被封装在链路层帧中,因此在架构上位于链路层之上。然而,ARP数据包中有包含链路层地址的字段,因此可以说是链路层协议,但它也包含网络层地址,因此也可以说是网络层协议。最后,ARP可能被认为是跨越链路层和网络层边界的最佳协议,它不适合我们在第一章中研究的简单的分层协议栈。这就是现实世界协议的复杂性。
从子网发送数据报
现在应该清楚了当一台主机想要向同一子网上的另一台主机发送数据报时,ARP是如何操作的了。但是现在让我们看看更复杂的情况:子网上的主机想要向子网外的主机发送网络层数据报(也就是说,穿过路由器到另一个子网上)。让我们在图6.19的环境中讨论这个问题,图中显示了一个简单的网络,由一个路由器连接的两个子网组成。
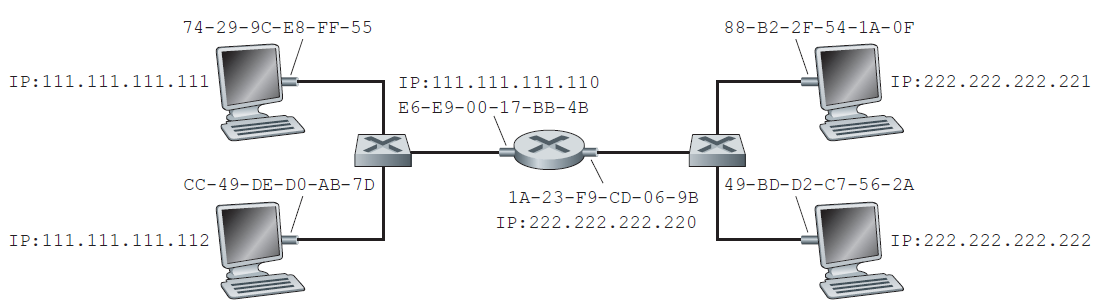
关于图6.19,有几个有趣的地方需要注意。每个主机只有一个IP地址和一个适配器。但是,正如第四章所讨论的,路由器的每个接口都有一个IP地址。对于每个路由器接口,也有一个ARP模块(在路由器中)和一个适配器。因为图6.19中的路由器有两个接口,所以它有两个IP地址、两个ARP模块和两个适配器。当然,网络中的每个适配器都有自己的MAC地址。
还要注意,子网1的网络地址为111.111.111/24,子网2的网络地址为222.222.222/24。因此,所有连接到子网1的接口都具有111.111.111.xxx形式的地址和所有连接到子网2的接口的地址形式为222.222.222.xxx。
现在让我们研究一下子网1上的主机如何向子网2上的主机发送数据报。例如,主机111.111.111.111要向主机222.222.222.222发送IP数据报。发送主机像往常一样将数据报传递给它的适配器。但是发送主机也必须向它的适配器指明一个适当的目标MAC地址。适配器应该使用什么MAC地址?人们可能会猜测,适当的MAC地址是主机222.222.222.222的适配器的MAC地址,即49-BD-D2-C7-56-2A。然而,这个猜测是错误的!如果发送适配器使用这个MAC地址,那么子网1上的任何适配器都不会费心把IP数据报传递到它的网络层,因为帧的目标地址与子网1上任何适配器的MAC地址都不匹配。数据报会死掉,然后进入数据报天堂。
如果我们仔细查看图6.19,我们会看到为了让数据报从111.111.111.111发送到子网2上的主机,数据报必须首先发送到路由器接口111.111.111.110,这是到达最终目的地路径上的第一跳路由器的IP地址。因此,帧的恰当MAC地址是路由器接口111.111.111.110的适配器地址,即E6-E9-00-17-BB-4B。发送主机如何获取111.111.111.110的MAC地址?当然是通过ARP!一旦发送适配器有了这个MAC地址,它就创建一个帧(包含地址为222.222.222.222的数据报),并将该帧发送到子网1。子网1上的路由器适配器看到链路层帧的地址是给它的,因此将帧传递给路由器的网络层。万岁,IP数据报已经成功地从源主机移动到路由器!但我们还没有结束。我们还得把数据报从路由器移到目的地。路由器现在必须确定数据报要转发的正确接口。正如第四章所讨论的,这是通过查询路由器中的转发表来完成的。转发表告诉路由器,数据报将通过路由器接口222.222.222.220转发。然后这个接口将数据报传递给它的适配器,适配器将数据报封装在一个新的帧中,并将帧发送到子网2。这一次,帧的目标MAC地址确实是最终目标的MAC地址。路由器如何获得这个目标MAC地址?当然是ARP!
用于以太网的ARP在RFC 826中定义。在TCP/IP教程RFC 1180中对ARP有一个很好的介绍。我们将在作业中更详细地探讨ARP。
6.4.2以太网
以太网几乎已经占领了有线局域网市场。在20世纪80年代和90年代初,以太网面临着来自其他局域网技术的许多挑战,包括令牌环、FDDI、ATM等。这些技术在几年里成功地占领了局域网市场的一部分。但自从20世纪70年代中期发明以来,以太网一直在不断发展壮大,并一直保持着它的主导地位。今天,以太网是目前最流行的有线局域网技术,而且在可预见的未来很可能仍然如此。有人可能会说以太网之于局域网就像因特网之于全球网络一样。
以太网的成功有很多原因。首先,以太网是第一个被广泛部署的高速局域网。由于部署较早,网络管理员对以太网非常熟悉——它的神奇和怪癖——当其他局域网技术出现时,他们不愿意切换到其他技术。其次,令牌环、FDDI和ATM比以太网更复杂、更昂贵,这进一步阻碍了网络管理员进行切换。第三,切换到另一种局域网技术(如FDDI或ATM)最令人信服的原因通常是更高的数据速率的新技术;然而,以太网总是奋起反击,生产出相同或更高数据速率的版本。交换式以太网也在20世纪90年代初被引入,这进一步提高了它的有效数据速率。最后,由于以太网非常流行,以太网硬件(特别是适配器和交换机)已经成为一种商品,而且非常便宜。
最初的以太局域网是在20世纪70年代中期由鲍勃·Metcalfe(Bob Metcalfe)和大卫·博格斯(David Boggs)发明的。原来的以太网局域网使用同轴总线来互连节点。以太网的总线拓扑实际上在整个20世纪80年代一直持续到90年代中期。具有总线拓扑结构的以太网是一个广播局域网——所有传输的帧都传输到连接到总线的所有适配器,并由其处理。回想一下,我们在第6.3.2节介绍了具有二进制指数回退的以太网CSMA/CD多路接入协议。
到20世纪90年代末,大多数公司和大学已经用基于集线器的星型拓扑(hub-based star topology)结构的以太网取代了局域网。在这种安装中,主机(和路由器)用双绞线直接连接到集线器。 集线器(hub) 是一种物理层设备,它作用于单独的比特而不是帧。当比特(代表0或1)从一个接口到达时,集线器简单地重建比特,增强其能量强度,并将比特传输到所有其他接口。因此,具有基于集线器的星型拓扑结构的以太网也是一个广播局域网,每当集线器从它的一个接口接收到一个比特时,它就在它的所有其他接口上发送一个副本。特别是,如果一个集线器同时接收来自两个不同接口的帧,就会发生碰撞,创建帧的节点必须重新传输。
在21世纪初,以太网经历了另一次重大的进化变化。以太网装置继续使用星型拓扑结构,但中心的集线器被 交换机 取代。我们将在本章后面深入研究交换式以太网。现在,我们只提到一个交换机不仅是无碰撞的,而且是一个真正的存储转发数据包交换机;但与路由器不同的是,路由器操作到第3层,而交换机只操作到第2层。

以太网帧结构
通过研究以太网框架,我们可以了解很多关于以太网的知识,如图6.20所示。为了让以太网帧的讨论更有实际意义,让我们考虑将IP数据报从一个主机发送到另一个主机,这两个主机都在同一个以太网局域网(例如,图6.17中的以太网局域网)(虽然我们的以太网帧的负载是IP数据报,但我们注意到以太网帧也可以携带其他网络层的数据包)。让发送适配器A的MAC地址为AA-AA-AA-AA-AA-AA,接收适配器B的MAC地址为BB-BB-BB-BB-BB-BB-BB。发送适配器将IP数据报封装在以太网帧中,并将帧传递给物理层。接收适配器接收来自物理层的帧,提取IP数据报,并将IP数据报传递给网络层。在这个环境中,现在让我们研究以太网框架的六个字段,如图6.20所示。
- 数据字段(46到1500字节) 该字段携带IP数据报。以太网的最大传输单元(MTU)为1500字节。这意味着如果IP数据报超过1500字节,那么主机必须对数据报进行分片(fragment),如4.3.2节所讨论的那样。数据字段的最小大小是46字节。这意味着如果IP数据报小于46字节,必须填充数据字段到46字节。当使用填充时,传递到网络层的数据既包含填充,又包含IP数据报。网络层使用IP数据报头中的长度字段来删除填充。
- 目标地址(6字节) 该字段包含目标适配器的MAC地址BB-BB-BB-BB-BB-BB。当适配器B收到目的地址为BB-BB-BB-BB-BB-BB或MAC广播地址的以太网帧时,它将帧的数据字段内容传递给网络层;如果接收到带有其他MAC地址的帧,则丢弃该帧。
- 源地址(6字节) 该字段包含将帧传输到局域网的适配器的MAC地址,本例中为AA-AA-AA-AA-AA-AA。
- 类型字段(2字节) 类型字段允许以太网多路复用网络层协议。为了理解这一点,我们需要记住,除了IP之外,主机还可以使用其他网络层协议。事实上,一个给定的主机可能支持多个网络层协议,对不同的应用程序使用不同的协议。因此,当以太网帧到达适配器B时,适配器B需要知道它应该将数据字段的内容传递给哪个网络层协议(即解复用)。IP和其他网络层协议(例如,Novell IPX或AppleTalk)都有自己的标准化类型号。此外,ARP协议(在上一节中讨论过)有自己的类型号,如果到达的帧包含一个ARP数据包(即,有一个0806十六进制的类型字段),ARP数据包将被解复用直到ARP协议。注意,类型字段类似于网络层数据报和传输层段中的端口号字段;所有这些字段都用于将一层的协议粘合到上面一层的协议。
- 循环冗余校验(CRC,4字节) 正如在6.2.3节中讨论的,CRC字段的目的是允许接收适配器B检测帧中的比特错误。
- 前导(Preamble,8字节) 以太网帧以一个8字节的前导字段开始。前导的前7个字节的值为10101010;最后一个字节为10101011。序言的前7个字节用于唤醒接收适配器,并将它们的时钟与发送者的时钟同步。为什么时钟会不同步?请记住,适配器A若想以速率为10Mbps、100Mbps或1Gbps传输帧,将取决于以太网LAN的类型。然而,因为没有什么是绝对完美的,适配器A不会完全以目标速率传输帧;总有一些偏离目标速率的偏移,这种偏移是局域网上的其他适配器无法预知的。接收适配器可以通过简单地锁定前导前7个字节中的比特来锁定适配器A的时钟。前导第8字节的最后2比特(连续的两个1)提醒适配器B,重要的东西即将到来。
所有的以太网技术都为网络层提供无连接服务。也就是说,当适配器A向适配器B发送数据报时,适配器A不需要先与适配器B握手,就可以将数据报封装在以太网帧中发送到局域网。这种第二层无连接服务类似于IP的第3层数据报服务和UDP的第4层无连接服务。
以太网技术为网络层提供了不可靠的服务。具体来说,当适配器B从适配器A接收到一个帧,它运行CRC校验帧,但当帧通过CRC校验时,不会发送一个确认;当帧CRC校验失败时,也不发送一个否定确认,而是简单地丢弃该帧。因此,适配器A不知道它传输的帧是否到达适配器B并通过CRC校验。这种(在链路层)可靠传输的缺乏有助于使以太网变得简单和廉价。但这也意味着传递到网络层的数据报流可能会有间隙(gaps)。
案例之——Bob Metcalfe和以太网
20世纪70年代初,作为哈佛大学的博士生,Bob Metcalfe在麻省理工学院(MIT)研究ARPAnet。在研究过程中,他还接触到了Abramson关于ALOHA和随机接入协议的研究。在完成博士学位之后,在Xerox Palo Alto研究中心开始工作之前,他拜访了Abramson和他在夏威夷大学的同事们三个月,亲身体验了ALOHAnet。在Xerox Palo Alto研究中心,Metcalfe接触到了Alto电脑,后者在很多方面都是上世纪80年代个人电脑的先驱。Metcalfe认为有必要以一种廉价的方式将这些计算机联网。他掌握了ARPAnet、ALOHAnet和随机接入协议的知识,Metcalfe和他的同事David Boggs一起发明了以太网。
Metcalfe和Boggs最初的以太网运行速度为2.94 Mbps,连接多达256台主机,最多间隔1英里。Metcalfe和Boggs成功地让Xerox Palo Alto研究中心的大多数研究人员通过他们的Alto电脑进行交流。随后,Metcalfe在Xerox, Digital和Intel之间建立了联盟,将以太网确立为10Mbps以太网标准,并得到了IEEE的批准。Xerox对将以太网商业化并没有太大兴趣。1979年,Metcalfe成立了自己的公司3Com,开发和商业化网络技术,包括以太网技术。尤其值得一提的是,3Com公司在20世纪80年代初为大受欢迎的IBM个人电脑开发并销售了以太网卡。
如果由于丢弃的以太网帧而产生间隙,主机B上的应用程序是否也能看到间隙?正如我们在第三章所学到的,这取决于应用程序是使用UDP还是TCP。如果应用程序使用UDP,那么主机B中的应用程序确实会看到数据中的差距。另一方面,如果应用程序正在使用TCP,则主机B中的TCP将不会承认丢弃的帧中包含的数据,从而导致主机A中的TCP重新传输。注意,当TCP重新传输数据时,数据最终将返回到它被丢弃的以太网适配器。因此,从这个意义上说,以太网确实重新传输数据,尽管以太网不知道它是在传输一个带有全新数据的全新数据报,还是一个包含已经至少传输过一次的数据报。
以太网技术
在我们上面的讨论中,我们把以太网当作一个单一的协议标准来看待。但事实上,Ethernet有许多不同的风格,有些令人困惑的首字母缩写,例如:10BASE-T, 10BASE-2, 100BASE-T, 1000BASE-LX,10GBASE-T和40GBASE-T。多年来,IEEE 802.3 CSMA/CD(以太网)工作组[IEEE 802.3 2020]对这些技术和许多其他以太网技术进行了标准化。虽然这些首字母缩写可能看起来令人困惑,但实际上这里有相当大的秩序。首字母缩略词的第一部分指的是标准的速度:10、100、1000或10G,分别对应10M、100M、1G、10G和40G(每秒)的以太网。BASE指基带(baseband)以太网,即物理媒体只承载以太网流量;几乎所有802.3标准都是用于基带以太网的。首字母缩略词的最后一部分指的是物理媒体本身;以太网既是链路层规格又是物理层规格,它通过各种物理介质传输,包括同轴电缆、铜线和光纤。T一般指双绞线铜线。
从历史上看,以太网最初被设想为一段同轴电缆。早期的10BASE-2和10BASE-5标准规定在两种同轴电缆上使用10Mbps以太网,每种电缆的长度限制在500米以内。使用 中继器(repeater) 可以更长——一种物理层设备,它在输入端接收信号,并在输出端重新生成信号。同轴电缆很符合作为以太网的广播媒介——以太网的CDMA/CD协议很好地解决了多路接入问题。节点只需连接到电缆上,瞧,我们就有了一个局域网。
多年来,以太网经历了一系列的演变,今天的以太网与最初使用同轴电缆的总线拓扑设计有很大的不同。在今天的大多数安装中,节点通过双绞线或光纤电缆制成的点对点段连接到交换机,如图6.15 6.17所示。
在20世纪90年代中期,以太网被标准化为100Mbps,比10Mbps以太网快10倍。保留了原有的以太网MAC协议和帧格式,但为铜线(100BASE-T)和光纤(100BASE-FX, 100BASE-SX, 100BASE-BX)定义了更高速度的物理层。图6.21显示了这些不同的标准以及常见的以太网MAC协议和帧格式。100Mbps以太网在双绞线上被限制在100米的距离内,以及通过光纤传输到几公里外,使得不同建筑物中的以太网交换机可以连接起来。
千兆以太网是非常成功的10Mbps和100Mbps以太网标准的扩展。提供40000 Mbps的原始数据速率,40G以太网保持与庞大的已安装的以太网设备完全兼容。千兆以太网的标准,即IEEE 802.3z,是这样做的:
- 采用标准以太网帧格式(图6.20),向后兼容10BASE-T和100BASE-T技术。这使得千兆以太网与现有安装的以太网设备很容易集成。
- 允许点对点链路以及共享的广播信道。点对点链路使用交换机,而广播信道使用集线器,如前所述。在千兆以太网术语中,集线器被称为缓冲分发器(buffered distributors)。
- 使用CSMA/CD共享广播信道。为了获得可接受的效率,节点之间的最大距离必须受到严格限制。
- 允许在点对点信道的两个方向上以40Gbps的全双工操作。
最初通过光纤运行,千兆以太网现在能够运行5类UTP电缆(用于1000BASE-T和10GBASE-T)。
让我们通过提出一个可能已经开始困扰您的问题来结束对以太网技术的讨论。在总线拓扑和基于集线器的星型拓扑时代,以太网显然是广播链路(如章节6.3所定义),当节点同时传输时,帧碰撞就会发生。为了处理这些碰撞,以太网标准包括了CSMA/CD协议,这对于跨越小地理区域的有线广播局域网特别有效。但是,如果今天以太网的普遍使用是基于交换机的星型拓扑结构,使用存储转发数据包交换,那么真的还有必要使用以太网MAC协议吗?我们很快就会看到,一个交换机协调它的传输,在任何时候都不会在同一个接口上转发超过一个帧。此外,现代交换机是全双工的,因此交换机和节点可以在同一时间互相发送帧,而不受干扰。换句话说,在一个基于交换机的以太网局域网中不存在碰撞,因此不需要MAC协议!
正如我们所看到的,今天的以太网与40多年前Metcalfe和Boggs设想的最初的以太网有很大的不同,速度提高了三个数量级,以太网帧可以通过各种媒介传输,交换式以太网已经成为主流,现在甚至连MAC协议都常常是不必要的!这一切真的还是以太网吗?根据定义,答案当然是肯定的。然而,值得注意的是,通过所有这些变化,以太网的帧格式确实有一个恒久不变的特点,30年来从未改变——也许这就是以太网标准唯一真实而永恒的核心。
6.4.3链路层交换机
到目前为止,我们一直有意对交换机的实际功能和工作原理含糊其辞。交换机的作用是接收传入的链路层帧并将它们转发到传出的链路上;我们将在本节中详细研究这个转发功能。我们将看到交换机本身对子网中的主机和路由器是 透明的 ;也就是说,一台主机/路由器将一帧地址发送给另一台主机/路由器(而不是将该帧地址发送给交换机),并愉快地将该帧发送到局域网,而没有意识到交换机将接收并转发该帧。帧到达任意一个交换机输出接口的速率可能暂时超过该接口的链路容量。为了解决这个问题,交换机输出接口有缓冲区,就像路由器输出接口有数据报缓冲区一样。现在让我们仔细看看交换机是如何工作的。
转发和过滤
过滤 是决定一个帧是否应该被转发到某个接口或应该被丢弃的交换机功能。 转发 是交换机的一个功能,它决定帧应该指向哪个接口,然后将帧移动到这些接口上。交换机过滤和转发是通过 交换表(switch table) 完成的。switch表包含了局域网中的主机和路由器的一些(不一定是全部)表项。交换表中表项包含(1)MAC地址,(2)指向该MAC地址的交换机接口,(3)该表项在表中被放置的时间。图6.15中最上面的交换机的交换表示例如图6.22所示。在第四章。事实上,在第4.4节对广义转发的讨论中,我们了解到许多现代数据包交换机可以配置为基于第二层目标MAC地址(即作为第二层交换机)或基于第三层目标IP地址(即作为第三层路由器)进行转发。尽管如此,我们将做出重要的区分,即基于MAC地址而不是IP地址转发数据包。我们还将看到传统的(即,在非SDN环境中)交换表的构造方式与路由器转发表的构造方式非常不同。
图6.15中最上面的交换机的交换表的一部分:
| 地址 | 接口 | 时间 |
|---|---|---|
| 62-FE-F7-11-89-A3 | 1 | 9:32 |
| 7C-BA-B2-B4-91-10 | 3 | 9:36 |
| ... | ... | ... |
为了理解交换机过滤和转发的原理,假设一个目标地址为DD-DD-DD-DD-DD-DD的帧在x接口到达交换机,交换机用MAC地址DD-DD-DD-DD-DD-DD-DD作为索引。有三种可能的情况:
- 表中没有关于DD-DD-DD-DD-DD-DD的表项。在这种情况下,交换机转发帧的副本到除接口x以外的所有接口的输出缓冲区。换句话说,如果没有目标地址的表项,交换机广播帧。
- 该表中有一个表项,将DD-DD-DD-DD-DD-DD 与接口x关联起来,此时,该帧来自一个包含适配器DD-DD-DD-DD-DD-DD的LAN段。如果交换机不需要将该帧转发到其他接口,则丢弃该帧,实现过滤功能。
- 该表中有一个表项,将DD-DD-DD-DD-DD-DD与接口y(≠x)关联起来。此时,需要将帧转发到LAN段所属的接口y。交换机通过将帧放在y接口前面的输出缓冲区中来实现转发功能。
让我们浏览一下图6.15中最上面的交换机和图6.22中其交换表的这些规则。假设一个目标地址为62-FE-F7-11-89-A3的帧从接口1到达交换机。交换机检查它的表,并看到目的地在连接到接口1(即电气工程)的LAN段上。这意味着帧已经在包含目的地的LAN段上广播。因此,交换机过滤(即丢弃)帧。现在假设有一个相同目标地址的帧从接口2到达。交换机再次检查它的表,发现目标端在接口1的方向;因此,它将帧转发到接口1前面的输出缓冲区。从这个例子中可以清楚地看出,只要交换表是完整和准确的,交换机就不需要广播就可以向目的地转发帧。
从这个意义上说,交换机比集线器更聪明。但是这个交换表首先是如何配置的呢?是否存在与网络层路由协议等价的链路层协议?或者工作过度的管理员必须手动配置交换表?
自学
交换机有一个奇妙的特性(特别是对于已经超负荷工作的网络管理员),它的表是自动、动态和自主地构建的——不需要网络管理员或配置协议的任何干预。换句话说,交换机是 自学的(self-learning) 。该功能实现如下:
- 交换表最初是空的。
- 对于从接口接收到的每一帧,交换机的表(1)保存帧源地址字段的MAC地址,(2)保存帧到达的接口,(3)保存当前时间。这样,交换机就在自己的表中记录了发送方所在的LAN段。如果局域网中的每台主机最终都发送一帧,那么每台主机最终都会被记录在表中。
- 如果在一段时间( 老化时间 ,aging time)后没有收到相同源地址的帧,交换机将删除表中相应的地址。这样,如果一台PC被另一台PC(使用不同的适配器)替换,原PC的MAC地址将最终从交换表中清除。
让我们浏览一下图6.15中最上面的交换机的自学属性,以及图6.22中对应的交换表。假设在9:39时,从接口2来了一个源地址为01-12-23-34-45-56的帧。假设这个地址不在交换表中。然后交换机将一个新条目添加到表中,如图6.23所示。
交换机学习地址为01-12-23-34-45-56的适配器的位置:
| 地址 | 接口 | 时间 |
|---|---|---|
| 01-12-23-34-45-56 | 2 | 9:39 |
| 62-FE-F7-11-89-A3 | 1 | 9:32 |
| 7C-BA-B2-B4-91-10 | 3 | 9:36 |
| ... | ... | ... |
继续这个例子,假设这个交换机的老化时间是60分钟,并且源地址为62-FE-F7-11-89-A3的帧在9:32到10:32之间到达交换机。然后在10:32的时候,交换机从它的表中删除这个地址。
交换机是 即插即用的设备 ,因为它们不需要网络管理员或用户的干预。希望安装交换机的网络管理员只需要将LAN段连接到交换机接口。管理员不需要在安装时配置交换表,或者当一台主机从一个LAN段中被移除时。交换机也是全双工的,这意味着任何交换机接口可以同时发送和接收。
链路层交换的属性
在描述了链路层交换机的基本操作之后,现在让我们考虑它们的特征和属性。我们可以确定使用交换机而不是广播链路(如总线或基于集线器的星型拓扑)的几个优点:
- 消除碰撞 在一个由交换机(没有集线器)构建的局域网中,不会因为碰撞而浪费带宽!交换机缓冲帧,并且在任何时候在一个段上不会传输超过一个帧。与路由器一样,交换机的最大总吞吐量是所有交换机接口速率的总和。因此,与广播链路的局域网相比,交换机提供了显著的性能改进。
- 异构的链路 由于交换机将一个链路与另一个链路隔离,局域网中的不同链路可以以不同的速度运行,并且可以在不同的介质上运行。例如,图6.15中最上面的交换机可能有三条1 Gbps的1000BASE-T铜链路、两条100 Mbps的100BASE-FX光纤链路和一条100BASE-T铜链路。因此,交换机是混合旧设备与新设备的理想选择。
- 管理 除了提供增强的安全性(请参阅侧栏关注安全性)外,交换机还简化了网络管理。例如,如果一个适配器发生故障并持续发送以太网帧(称为jabbering适配器),交换机可以检测到问题并在内部断开故障适配器。有了这个功能,网络管理员不需要起床和开车回去工作,以纠正问题。类似地,切断的电缆只会断开使用切断的电缆连接到交换机的主机。在同轴电缆时代,许多网络管理员要花上好几个小时在线路上行走(或者更准确地说,在地板上爬行),才能找到导致整个网络瘫痪的电缆断路。交换机还收集关于带宽使用情况、碰撞率和流量类型的统计信息,并使这些信息对网络管理员可用。这些信息可以用于调试和纠正问题,并计划局域网未来应该如何发展。研究人员正在探索在原型部署的以太网局域网中添加更多的管理功能[Casado 2007;Koponen 2011]。
聚焦安全之——嗅探一个交换机LAN:交换机中毒
当主机连接到交换机时,它通常只接收为它准备的帧。例如,考虑图6.17中的交换式局域网。当主机A向主机B发送一帧时,如果在交换表中有主机B的表项,那么交换机只会将该帧转发给主机B。如果主机C正在运行嗅探器,主机C将无法嗅探这个A-to-B帧。因此,在交换机局域网环境中(与802.11局域网或基于集线器的以太网局域网等广播链路环境相比),攻击者更难嗅探出帧。但是,因为交换机广播的帧的目标地址不在交换表中,所以C的嗅探器仍然可以嗅探一些不是为C准备的帧。此外,嗅探器还可以嗅探所有带有广播目标地址FF–FF–FF–FF–FF–FF的以太网广播帧。一种众所周知的针对交换机的攻击称为 交换机中毒 ,它是向交换机发送大量带有许多不同虚假源MAC地址的数据包,从而用虚假表项填充交换表,使合法主机的MAC地址无法拥有任何空间。这导致交换机广播大部分帧,然后可以被嗅探器拾取[Skoudis 2006]。由于这种攻击多半涉及到老练的攻击者,集线器和无线局域网将比交换机更容易被嗅探。
交换机与路由器对比
正如我们在第4章所学到的,路由器是使用网络层地址转发数据包的存储-转发数据包交换机。虽然交换机也是存储和转发数据包的交换机,但它与路由器的根本区别在于它使用MAC地址转发数据包。路由器是第三层数据包交换机,交换机是第二层数据包交换机。但是,回想一下,我们在4.4节中已经了解到,使用match + action 的现代交换机可以用来根据帧的目标MAC地址转发第二层帧,以及使用数据报的目标IP地址的第3层数据报。实际上,我们看到使用OpenFlow标准的交换机可以基于十一种不同的帧、数据报和传输层头字段中的任何一种执行通用的数据包转发。
尽管交换机和路由器在本质上是不同的,但网络管理员在安装互连设备时经常必须在它们之间做出选择。例如,对于图6.15中的网络,网络管理员可以很容易地使用路由器而不是交换机来连接部门局域网、服务器和互联网网关路由器。事实上,路由器可以允许部门间的通信,而不会产生冲突。既然交换机和路由器都是互连设备的候选者,那么这两种方法的优点和缺点是什么?
首先探讨交换机的利弊。如上所述,交换机是即插即用的,这是世界上所有超负荷工作的网络管理员所珍视的特性。交换机还可以有相对较高的过滤和转发速率——如图6.24所示,交换机只能处理到第2层的帧,而路由器可以处理到第3层的数据报。另一方面,为了防止广播帧的循环,将交换式网络的活动拓扑限制在生成树上(spanning tree)。此外,一个大型的交换式网络将需要主机和路由器上的大型ARP表,并将产生大量的ARP流量和处理。此外,交换机很容易受到广播风暴的影响——如果一台主机出了故障,不停地传输以太网广播帧流,交换机就会转发所有这些帧,导致整个网络崩溃。
现在探讨一下路由器的利弊。由于网络寻址通常是分层的(而不是平面的,就像MAC寻址一样),即使网络中有冗余路径,数据包通常也不会在路由器上循环。(然而,当路由表配置错误时,数据包可能会循环;但正如我们在第4章中学到的,IP使用一个特殊的数据报头字段来限制循环。)这样,数据包就不局限于生成树,可以使用源到目标之间的最佳路径。由于路由器不受生成树的限制,它们可以让互联网构建一个丰富的拓扑结构,例如,包括欧洲和北美之间的多条活动链路。路由器的另一个特性是,它们提供防火墙保护,防止第二层广播风暴。不过,路由器最大的缺点可能是它们不是即插即用的——它们和连接到它们的主机需要配置它们的IP地址。此外,路由器的每个数据包处理时间通常比交换机要长,因为它们必须向上处理到第3层字段。最后,单词router有两种不同的发音方式,要么是rootor,要么是rowter,人们浪费大量时间争论正确的发音[Perlman 1999]。
鉴于交换机和路由器都有各自的优点和缺点(如表6.1所示),机构网络(例如,大学校园网或企业校园网)什么时候应该使用交换机,什么时候应该使用路由器?通常,由几百台主机组成的小型网络有几个LAN段。交换机足以满足这些小型网络的需要,因为它们可以本地化流量并增加总体吞吐量,而不需要配置任何IP地址。但是由数千台主机组成的大型网络通常包括网络中的路由器(除了交换机)。路由器提供了更强大的流量隔离,控制广播风暴,并在网络中的主机之间使用更智能的路由。
| 集线器 | 路由器 | 交换机 | |
|---|---|---|---|
| 流量隔离 | No | Yes | Yes |
| 即插即用 | Yes | No | Yes |
| 最优路由 | No | Yes | No |
表 6.1
有关交换式网络与路由式网络优劣的更多讨论,以及如何扩展交换式LAN技术以容纳比当今以太网多两个数量级的主机的讨论,请参阅[Meyers 2004;Kim 2008]。
6.4.4 虚拟局域网(VLAN)
在我们前面对图6.15的讨论中,我们注意到现代机构局域网通常是分层配置的,每个工作组(部门)都有自己的交换式局域网,通过交换式局域网连接到其他组的交换式局域网。虽然这种配置在理想世界中运行良好,但现实世界往往与理想相差甚远。在图6.15中的配置中可以发现三个缺点:
- 缺乏流量隔离 虽然该层次结构将组流量集中在单个交换机内,但广播流量(例如,携带ARP和DHCP消息的帧或未被自习交换机学习到目的地的帧)仍然必须穿越整个机构网络。限制这种广播流量的范围将会提高局域网的性能。也许更重要的是,出于安全/隐私的原因,限制局域网广播流量也是可取的。例如,如果一个组包含公司的执行管理团队,而另一个组包含运行Wireshark数据包嗅探器的心怀不满的员工,网络管理员很可能希望执行流量永远不会到达员工的主机。这种类型的隔离可以通过将图6.15中的中心交换机替换为路由器来实现。我们将很快看到,这种隔离也可以通过交换式(第2层)解决方案实现。
- 交换机使用效率低 如果该机构不是3组,而是10组,那么就需要10个一级交换机。如果每个小组都很小,比如少于10人,那么一个96端口交换机就可能足够容纳每个人,但单个交换机不能提供流量隔离。
- 管理用户 如果员工在组间移动,则需要更改物理连线,将员工连接到图6.15中不同的交换机上。属于不同组的员工让问题变得更加棘手。
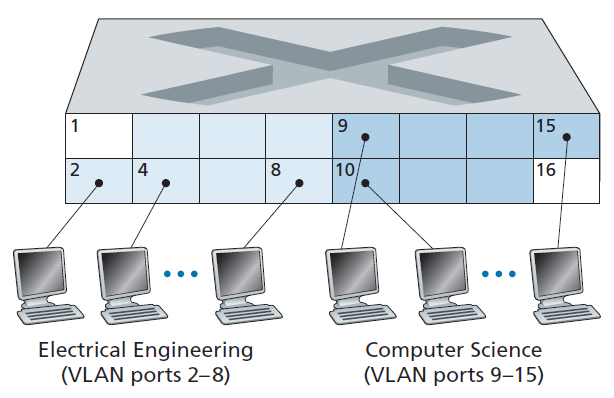
幸运的是,这些困难都可以通过支持 虚拟局域网 (VLAN)的交换机来解决。顾名思义,支持VLAN的交换机允许在单个物理局域网基础设施上定义多个虚拟局域网。VLAN内的主机互相通信,就像它们(而不是其他主机)连接到交换机一样。在基于端口的VLAN中,交换机的端口(接口)被网络管理员划分为多个组。每个组组成一个VLAN,每个VLAN内的端口组成一个广播域(即一个端口的广播流量只能到达组内的其他端口)。图6.25展示了单台16端口的交换机。端口2 ~ 8属于EE VLAN,端口9 ~ 15属于CS VLAN(端口1和端口16未分配)。这个VLAN解决了上面提到的所有困难——EE和CS VLAN帧相互隔离,图6.15中的两个交换机被单个交换机取代,如果交换机端口8的用户加入了CS部门,网络操作员只需重新配置VLAN软件,使端口8现在与CS VLAN相关联。可以很容易地想象VLAN交换机是如何配置和操作的——网络管理器使用交换机管理软件声明一个端口属于一个给定的VLAN(未声明的端口属于一个默认VLAN),在交换机中维护一个端口到VLAN的映射表;交换机硬件只在属于同一VLAN的端口之间下发帧。
但是,通过完全隔离两个VLAN,我们引入了一个新的困难!如何将EE部门的流量传送给CS部门?一种处理方法是将VLAN交换机端口(例如图6.25中的端口1)连接到外部路由器,并将该端口配置为同时属于EE和CS VLAN。在这种情况下,即使EE和CS部门共享相同的物理交换机,逻辑配置看起来就好像EE和CS部门有通过路由器连接的独立交换机。从EE到CS部门的IP数据报会先通过EE VLAN到达路由器,再由路由器通过CS VLAN转发回CS主机。幸运的是,交换机供应商通过构建一个包含VLAN交换机和路由器的单一设备,使网络管理人员很容易进行这样的配置,因此不需要单独的外部路由器。本章末尾的一个作业问题更详细地探讨了这个场景。
回到图6.15,现在我们假设不是有一个单独的计算机工程部门,一些EE和CS教员被安置在一个单独的大楼里,(当然!)他们需要网络访问,(当然!)他们希望成为他们部门VLAN的一部分。图6.26显示了第二个8端口交换机,其中交换机端口根据需要被定义为属于EE或CS VLAN。但这两个交换机应该如何相互连接呢?一个简单的解决方案是在每个交换机上定义一个属于CS VLAN的端口(EE VLAN也是类似的),并将这些端口相互连接,如图6.26(a)所示。然而,这种解决方案无法扩展,因为N个VLAN需要在每个交换机上使用N个端口来互连两个交换机。
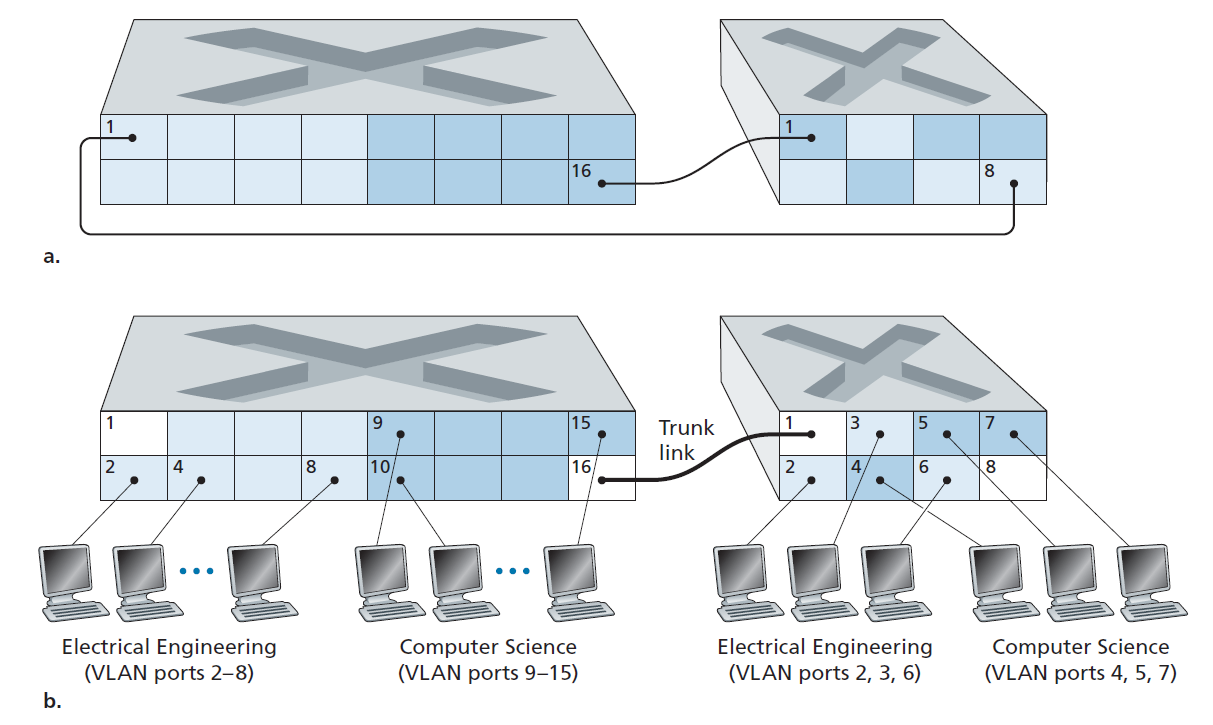
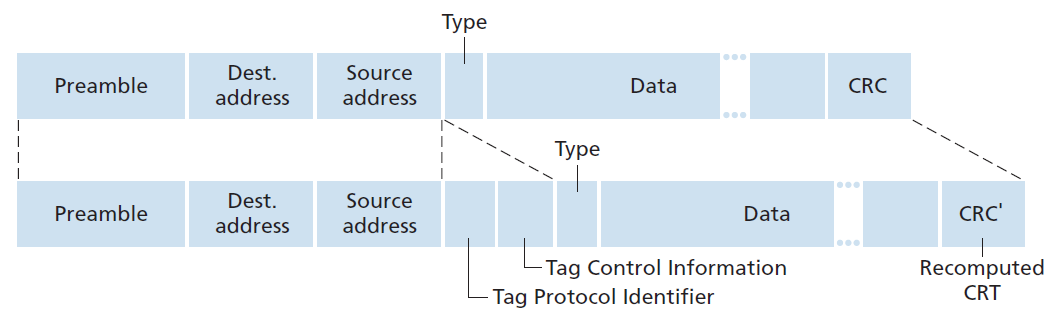
VLAN交换机互连的一种更具有伸缩性的方法称为 VLAN中继(VLAN trunking) 。如图6.26(b)所示,VLAN中继方式是将交换机上的一个特殊端口(左侧交换机的16号端口和右侧交换机的1号端口)配置为中继端口,用于连接两台VLAN交换机。中继类型的端口属于所有VLAN,发送到任意一个VLAN的帧都会通过中继链路转发到另一台交换机。但这又引出了另一个问题:交换机如何知道到达中继端口的帧属于某个特定的VLAN?IEEE定义了一种扩展的以太网帧格式802.1Q,用于帧通过VLAN 中继。如图6.27所示,802.1Q帧由标准以太网帧组成,在帧头中添加一个四字节的 VLAN标记 ,该标记携带帧所属VLAN的标识。VLAN 标记由VLAN 中继发送侧的交换机添加到帧中,并由接收侧的交换机解析并移除。VLAN标记本身由一个2字节的TPID (tag Protocol Identifier)字段(固定的16进制值为81-00)、一个2字节的tag Control Information字段(包含一个12位的VLAN标识符字段)和一个3位的优先级字段(有意类似于IP数据报TOS字段)组成。
在本讨论中,我们只简要地讨论了VLAN,并重点讨论了基于端口的VLAN。我们还应该提到,可以用几种其他方式定义VLAN。在基于MAC的VLAN中,网络管理员指定属于每个VLAN的MAC地址集;当一个设备连接到一个端口时,该端口会根据设备的MAC地址连接到相应的VLAN中。VLAN也可以根据网络层协议(如IPv4、IPv6或Appletalk)和其他标准定义。VLAN也有可能跨IP路由器扩展,允许局域网的岛屿连接在一起,形成一个可以跨越全球的单一VLAN [Yu 2011]。详见802.1Q标准[IEEE 802.1Q 2005]。
链路虚拟化:将网络作为链路层
由于本章涉及到链路层协议,鉴于我们现在已经接近本章的结尾,让我们反思一下我们对链路这个术语的理解是如何演变的。在本章开始时,我们将链路视为连接两个通信主机的物理连线。在研究多路接入协议时,我们看到多个主机可以通过共享的电线(wire)连接,连接主机的“电线”可以是无线电频谱或其他媒介。这使得我们更抽象地将链路看作通道,而不是导线。在我们对以太网LAN(图6.15)的研究中,我们看到互连介质实际上可以是一个相当复杂的交换基础设施。然而,在整个演变过程中,主机自己坚持认为,互联介质只是连接两个或多个主机的链路层通道。例如,我们看到,以太网主机可以完全不知道它是通过一个较短的LAN段(图6.17)连接到其他LAN主机,还是通过一个地理上分散的交换式LAN(图6.15)或通过一个VLAN(图6.26)连接到其他LAN主机。
在两台主机之间的拨号调制解调器连接的情况下,连接两台主机的链路实际上是电话网络,这是一个逻辑上独立的全球电信网络,它有自己的交换机、链路和用于数据传输和信令的协议栈。然而,从因特网链路层的观点来看,通过电话网的拨号连接被视为一根简单的电线。从这个意义上说,因特网对电话网络进行了虚拟化,把电话网络看作是提供两个因特网主机之间链路层连接的链路层技术。你可能会回想起我们在第二章中对覆盖网络(overlay network)的讨论,覆盖网络同样将互联网视为提供覆盖节点之间连接的一种手段,试图以互联网覆盖电话网络的方式覆盖互联网。
在本节中,我们将讨论多协议标签交换(MPLS,Multiprotocol Label Switching)网络。与线路交换的电话网络不同,MPLS是数据包交换式的,虚拟电路网络本身。它有自己的数据包格式和转发行为。因此,从教学的角度来看,对MPLS的讨论适合于网络层或链路层的研究。然而,从因特网的观点来看,我们可以把MPLS看作一种链路层技术,就像电话网和交换以太网一样,用来互连IP设备。因此,我们将在讨论链路层时考虑MPLS。帧中继和ATM网络也可以用来互连IP设备,尽管它们代表了一种稍微老一些(但仍在部署)的技术,这里不做介绍;详情请参阅可读性很强的书[Goralski 1999]。我们对MPLS的讨论必然会很简短,因为整本书都可以(也已经)在这些网络上写成。我们推荐[Davie 2000]了解MPLS的详细信息。在这里,我们将主要关注MPLS服务器如何与IP设备互连,尽管我们也将更深入地研究底层技术。
6.5.1 MPLS
多协议标签交换(MPLS)是在20世纪90年代中后期的一系列行业努力中发展起来的,它采用了虚拟电路网络中的一个关键概念:固定长度标签,以提高IP路由器的转发速度。这样做的目的不是为了放弃基于目的地的IP数据报转发基础设施,而是通过有选择地标记数据报,并允许路由器在可能的情况下基于固定长度的标签(而不是目标IP地址)转发数据报,来增强该基础设施。重要的是,这些技术与IP一起工作,使用IP寻址和路由。IETF在MPLS协议[RFC 3031, RFC 3032]中统一了这些努力,有效地将VC技术混合到路由数据报网络中。
让我们从考虑由支持MPLS的路由器处理的链路层帧的格式开始我们对MPLS的研究。图6.28显示了在支持MPLS的设备之间传输的链路层帧在第2层(如以太网)头和第3层(如IP)头之间添加了一个较小的MPLS头。RFC 3032定义了这种链路的MPLS头格式;在ATM和帧中继网络以及其他RFC中也定义了头。MPLS头中的字段包括标签、保留3位用于实验、一个单独的S位(用于表示一系列堆叠的MPLS头的结束(这是一个高级的主题,我们在这里不讨论)和一个生存时间字段。
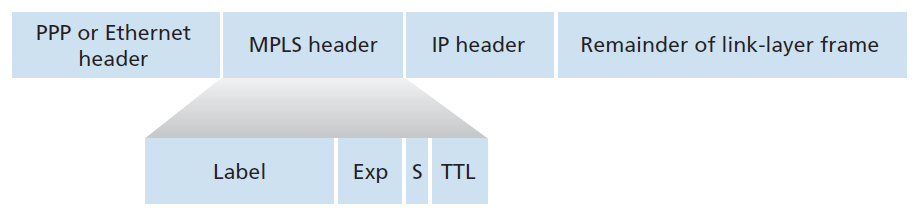
从图6.28中可以立即看出,一个MPLS增强的帧只能在具有MPLS能力的路由器之间发送(因为一个没有MPLS能力的路由器在它期望找到IP头的地方发现MPLS头时,会非常困惑!)支持MPLS的路由器通常被称为 标签交换路由器(label-switched router) ,因为它通过在转发表中查找MPLS标签来转发MPLS帧,然后立即将数据报传递给相应的输出接口。这样,具有MPLS功能的路由器就不需要提取目标IP地址,而是在转发表中查找最长前缀匹配。但是路由器如何知道它的邻居是否确实具有MPLS能力,以及如何知道与给定IP目的地关联的标签?要回答这些问题,我们需要了解一组支持MPLS的路由器之间的交互。
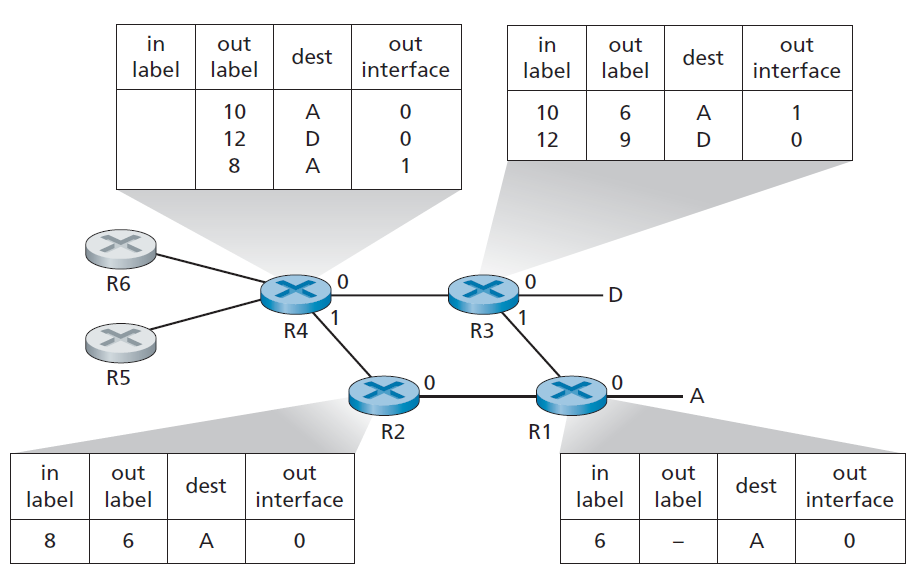
在图6.29的示例中,路由器R1到R4都支持MPLS。R5和R6是标准的IP路由器。R1已经通告R2和R3,它(R1)可以路由到目标地址A,并且收到的MPLS标签为6的帧将被转发到目标地址A。路由器R3已经通知R4,它可以路由到目标地址A和目标地址D,收到的MPLS标签分别为10和12的帧将被切换到这些目的地。路由器R2也已经通知路由器R4,它(R2)可以到达目标地址A,接收到的MPLS标签为8的帧将被交换到目标地址A。需要注意的是,路由器R4现在有两条MPLS路径可以到达A:接口0的MPLS标签为10,接口1的MPLS标签为8。图6.29所描绘的大致情况是,IP设备R5、R6、A和D通过MPLS基础设施(支持MPLS的路由器R1、R2、R3和R4)连接在一起,就像交换式局域网或ATM网络连接IP设备一样。就像交换式局域网或ATM网络一样,MPLScapable路由器R1到R4这样做时不需要接触数据包的IP头。
在上面的讨论中,我们没有指定用于在支持MPLS的路由器之间分发标签的具体协议,因为这种信令的细节远远超出了本书的范围。然而,我们注意到IETF工作组在MPLS方面已经在[RFC 3468]中指定了RSVP协议的扩展,即RSVP-TE[RFC 3209],将是其在MPLS信令方面工作的重点。我们也没有讨论MPLS实际上是如何计算具有MPLS能力的路由器之间的数据包路径的,也没有讨论它是如何收集链路状态信息(例如,没有被MPLS保留的链路带宽数量)来用于这些路径计算的。现有的链路状态路由算法(如OSPF)已经被扩展到支持MPLS的路由器。有趣的是,实际的路径计算算法并不是标准化的,而且目前是特定于供应商的。
到目前为止,我们对MPLS的讨论重点都集中在MPLS是基于标签进行交换的,而不需要考虑数据包的IP地址。然而,MPLS的真正优势以及目前人们对MPLS感兴趣的原因并不在于其交换速度的潜在提高,而在于MPLS带来的新的流量管理能力。如上所述,R4有两条到A的MPLS路径。如果转发是在IP层上基于IP地址进行的,那么我们在第五章中研究的IP路由协议将只指定一条到A的开销最低的路径。因此,MPLS提供了沿着标准IP路由协议无法实现的路由转发数据包的能力。这是使用MPLS的一种简单的 流量工程(traffic engineering) 形式 [RFC 3346;RFC 3272;RFC 2702;Xiao 2000],网络运营商可以覆盖普通的IP路由,迫使一些流量沿一条路径前往给定的目的地,而其他流量沿另一条路径前往相同的目的地(无论是出于策略、性能还是其他原因)。
也可以将MPLS用于许多其他目的。它可以用于执行MPLS转发路径的快速恢复,例如,在响应链路故障时,通过预先计算的故障转移路径重新路由流量[Kar 2000;Huang 2002;RFC 3469)。最后,我们注意到MPLS可以并且已经被用来实现所谓的 虚拟私有网络(VPN virtual private networks) 。在为客户实现VPN的过程中,ISP通过自身的MPLS网络将客户的各种网络连接在一起。MPLS可以将用户VPN使用的资源和地址与跨ISP网络的其他用户的资源和地址隔离开来;详见[DeClercq 2002]。
我们对MPLS的讨论很简短,我们鼓励您查阅我们提到的参考资料。我们注意到,在我们在第5章中研究的软件定义网络发展之前,MPLS就已经崭露头角,而且MPLS的许多流量工程能力也可以通过SDN和我们在第4章中研究的广义转发范式实现。只有未来才能告诉我们,MPLS和SDN是否会继续共存,或者更新的技术(如SDN)是否会最终取代MPLS。
数据中心网络
像谷歌、微软、亚马逊和阿里巴巴这样的互联网公司已经建立了庞大的数据中心,每个中心容纳了数万到数十万台主机。正如在第1.2节的侧栏中简要讨论的那样,数据中心不仅连接到Internet,而且在内部还包括复杂的计算机网络,称为 数据中心网络 ,它们相互连接内部主机。在本节中,我们将简要介绍用于云应用程序的数据中心组网。
一般来说,数据中心有三个用途。首先,它们向用户提供诸如网页、搜索结果、电子邮件或流媒体视频等内容。其次,它们充当特定数据处理任务的大规模并行计算基础设施,例如搜索引擎的分布式索引计算。第三,他们为其他公司提供 云计算 。事实上,当今计算领域的一个主要趋势是,公司使用亚马逊网络服务(Amazon Web Services)、微软Azure和阿里云(Alibaba cloud)等云服务提供商来处理他们的所有IT需求。
6.6.1数据中心架构
数据中心的设计被严格保密,因为它们常常为领先的云计算公司提供关键的竞争优势。大型数据中心的成本是巨大的,在2009年,一个10万主机的数据中心每月的成本超过1200万美元[Greenberg 2009a]。在这些成本中,大约45%可以归因于主机本身(每3到4年需要更换一次);25%用于基础设施建设,包括变压器、不间断电源(UPS,uninterruptable power supplies)系统、用于长期停电的发电机和冷却系统;电费的15%用于能耗(power draw);15%用于网络,包括网络设备(交换机、路由器和负载均衡器)、外部链路和传输流量成本。(在这些百分比中,设备成本是摊销的,因此一次性购买和持续支出(如电力)适用一个通用的成本指标。)虽然网络不是最大的成本,但网络创新是降低整体成本和最大化性能的关键[Greenberg 2009a]。
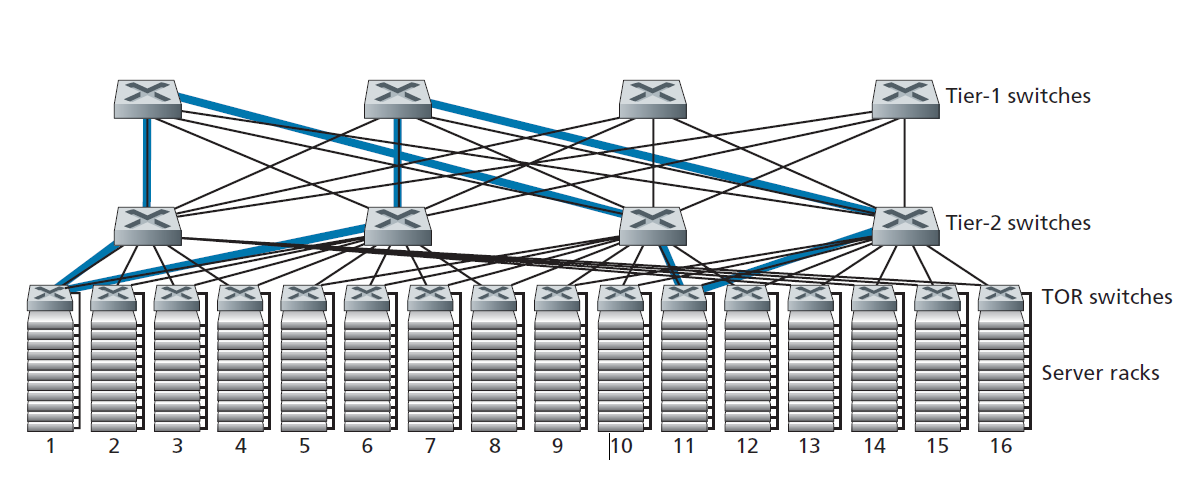
数据中心的工蜂就是主机。数据中心中的主机(称为 刀片 ,类似于披萨盒)通常是商品主机,包括CPU、内存和磁盘存储。主机堆叠在机架中,每个机架通常有20到40片刀片。在每个机架的顶部,有一个交换机,被恰当地命名为 机架顶部(TOR,Top of Rack)交换机 ,它将机架中的主机与其他主机以及数据中心中的其他交换机连接起来。具体来说,机架中的每台主机都有一个连接到其TOR交换机的网络接口,每台TOR交换机都有额外的端口可以连接到其他交换机。如今,主机通常有40 Gbps或100 Gbps以太网连接到TOR交换机[FB 2019; Greenberg 2015; Roy 2015; Singh 2015]。每个主机还被分配自己的data-center-internal IP地址。
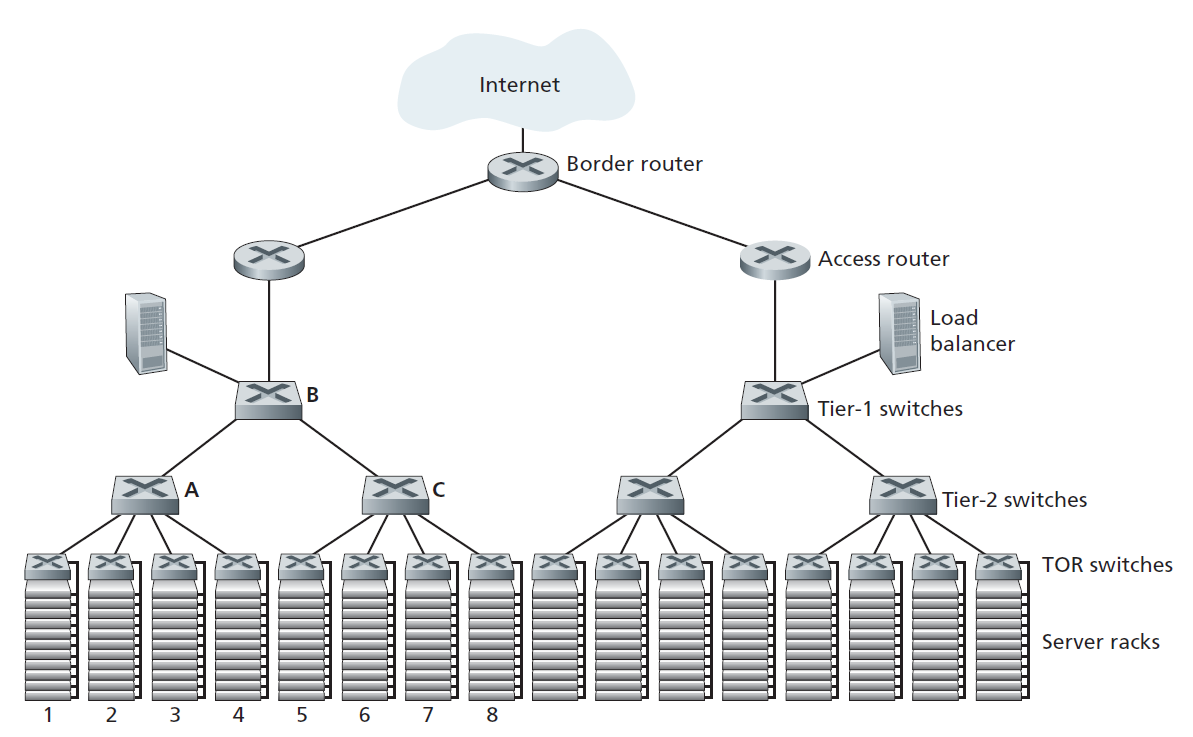
数据中心网络支持两种流量:外部客户端和内部主机之间的流量和内部主机之间的流量。为了处理外部客户端和内部主机之间的流量,数据中心网络包括一个或多个 边界路由器 ,将数据中心网络连接到公共Internet。因此,数据中心网络将机架相互连接,并将机架连接到边界路由器。以数据中心组网为例,如图6.30所示。 数据中心网络设计 ,是一种设计互联网络的艺术,它设计的是将各机架之间以及与边界路由器连接起来的协议。近年来,数据中心网络设计已成为计算机网络研究的一个重要分支。(请参阅本节的参考资料。)
负载均衡
云数据中心(如谷歌、Microsoft、Amazon、阿里巴巴等运营的云数据中心)可以同时提供搜索、电子邮件、视频等应用。为了支持来自外部客户端的请求,每个应用程序都与一个公开的IP地址相关联,客户端向该IP地址发送请求,并从该IP地址接收响应。在数据中心内部,外部请求首先被定向到负载均衡器,其工作是,根据主机当前的负载均衡主机之间的负载将请求分发到主机[Patel 2013;2016]。大型数据中心通常有几个负载均衡器,每个负载均衡器专门用于一组特定的云应用程序。这样的负载均衡器有时被称为第4层交换机,因为它根据数据包中的目标端口号(第4层)和目标IP地址做出决定。当接收到对特定应用程序的请求时,负载均衡器将其转发给处理该应用程序的主机之一。(主机可以调用其他主机的服务来帮助处理请求。)负载均衡器不仅平衡了不同主机之间的工作负载,而且还提供了类似于NAT的功能,将公开的外部IP地址转换为相应主机的内部IP地址,然后将反向传输的数据包转换回客户端。这样可以避免客户端直接联系主机,从而隐藏了内部网络结构,避免客户端直接与主机交互,从而达到安全的目的。
分层结构
对于只有几千台主机的小型数据中心来说,一个由边界路由器、负载均衡器和几十个机架组成的简单网络可能就足够了,这些机架都由一个以太网交换机互连。但是要扩展到数万到数十万台主机,数据中心通常使用路由器和交换机的层次结构,如图6.30所示。在层次结构的顶部,边界路由器连接到接入路由器(图6.30中只显示了两个,但可能有更多)。在每个接入路由器下面,有三层交换机。每个接入路由器连接一个顶层交换机,每个顶层交换机连接多个二层交换机和负载均衡器。每个第二层交换机依次通过机架TOR交换机(第三层交换机)连接到多个机架。所有链路通常都使用以太网作为链路层和物理层协议,并混合使用铜线和光纤电缆。通过这种分层设计,可以将一个数据中心扩展到数十万台主机。
由于云应用程序提供商持续提供高可用性应用程序至关重要,因此数据中心的设计中还包括冗余网络设备和冗余链路(图6.30中没有显示)。例如,每个TOR交换机可以连接到两个二层交换机,每个接入路由器、一层交换机和二层交换机都可以复制和集成到设计中[Cisco 2012;Greenberg 2009 b]。在图6.30的分层设计中,可以看到每个接入路由器下面的主机组成了一个单独的子网。为了本地化ARP广播流量,每个子网被进一步划分为更小的VLAN子网,每个子网包含几百台主机[Greenberg 2009a]。
尽管刚刚描述的传统层次结构解决了规模问题,但它受到主机到主机的有限容量的影响[Greenberg 2009b]。要理解这个限制,请再次考虑图6.30,假设每个主机都用10Gbps链路连接到它的TOR交换机,交换机之间的链路为100Gbps以太网链路。同一机架中的两台主机总是可以以10Gbps的速率进行通信,这只受主机网络接口控制器速率的限制。但是,如果数据中心网络中同时有许多流,那么位于不同机架的两台主机之间的最大速率可能要小得多。为了深入了解这个问题,考虑一个由不同机架中40对主机间40个同时发生的流组成的流量模式。假设图6.30中1号机架的10台主机每台都向5号机架对应的主机发送一个流。类似地,机架2和机架6中的主机对之间有10个同时发生的流,机架3和机架7之间有10个同时发生的流,机架4和机架8之间有10个同时发生的流。如果每个流平均地与穿过该链路的其他流共享一条链路的容量,那么穿过100Gbps的A -to- B链路(以及100Gbps的B-to-C链路)的40个流将只收到100Gbps / 40 = 2.5 Gbps,这明显低于10Gbps的网络接口速率。对于需要传输到更高层次的主机之间的流,问题变得更加尖锐。
对于这个问题有几种可能的解决方案:
- 解决这个限制的一个可能的解决方案是部署更高速率的交换机和路由器。但这将大大增加数据中心的成本,因为具有高端口速度的交换机和路由器非常昂贵。
- 这个问题的第二种解决方案是尽可能地将相关的服务和数据集中在一起(例如,在同一个机架或在附近的机架中)[Roy 2015;Singh 2015],以最大限度地减少通过二层或一层交换机的机架间通信。但这只能到此为止,因为数据中心的关键需求是计算和服务放置的灵活性[Greenberg 2009b;Farrington 2010]。例如,一个大规模的Internet搜索引擎可能在分布在多个机架上的数千台主机上运行,在所有主机对之间需要很大的带宽。类似地,云计算服务(如Amazon Web服务或Microsoft Azure)可能希望将包含客户服务的多个虚拟机放在具有最大容量的物理主机上,而不考虑它们在数据中心的位置。如果这些物理主机分布在多个机架上,如上所述的网络瓶颈可能会导致较差的性能。
- 解决方案的最后一部分是增加TOR交换机和二层交换机之间以及二层交换机和一层交换机之间的连通性。例如,如图6.31所示,每个TOR交换机可以连接到两个二层交换机,然后在机架之间提供多个链路和交换机不相交的路径。在图6.31中,第一个二层交换机和第二个二层交换机之间有4条不同的路径,一起提供了前两个二层交换机之间400 Gbps的总容量。增加层之间的连接程度有两个显著的好处:增加交换机之间的容量和可靠性(因为路径多样性)。在Facebook的数据中心[FB 2014;FB 2019],每个TOR连接到4个不同的二级交换机,每个二级交换机连接到4个不同的一级交换机。
数据中心网络中各层之间的连接性增加的一个直接后果是多路径路由可以成为这些网络中的一等公民。默认情况下,流为多路径流。实现多路径路由的一个非常简单的方案是等价多路径(Equal Cost Multi Path, ECMP) [RFC 2992],它沿着源和目标之间的交换机执行随机的下一跳选择。使用细粒度负载均衡的先进方案也被提出[Alizadeh 2014;Noormohammadpour 2018]。虽然这些方案在流级别执行多路径路由,但也有设计在多路径之间的流中路由单个数据包[He 2015;Raiciu 2010]。
6.6.2 数据中心组网趋势
数据中心网络正在快速发展,降低开销、虚拟化、物理约束、模块化和定制化是数据中心网络发展的趋势。
降低开销
为了降低数据中心的开销,同时提高其延迟和吞吐量性能,以及易于扩展和部署,互联网云巨头不断部署新的数据中心网络设计。尽管其中一些设计是专有的,但其他设计(如[FB 2019])是明确开放的或在开放文献中描述的(如[Greenberg 2009b;Singh 2015])。因此可以确定许多重要的趋势。
图6.31说明了数据中心网络的一个最重要的趋势——出现了层次化的、分层的网络连接数据中心主机。这个层次结构在概念上与我们在4.2.2节中学习的单个(非常非常!)大型交叉交换机的目的是相同的,它允许数据中心中的任何主机与任何其他主机通信。但正如我们所见,这种分层互联网络比概念上的交叉交换机有更多优势,包括从源到目标有多条路径,容量(由于多路径路由)和可靠性(由于任意两台主机之间有多条交换机和链路不相交的路径)有所增加。
数据中心互联网络由大量的小型交换机组成。例如,在谷歌的Jupiter数据中心结构中,一种配置在ToR交换机和它下面的服务器之间有48条链路,连接多达8个二层交换机;一个二层交换机连接到256个ToR交换机,16个一层交换机[Singh 2015]。在Facebook的数据中心架构中,每个ToR交换机最多连接4个不同的二层交换机(每个交换机在不同的“spline plane”中),每个二层交换机在其spline plane中最多连接48个一层交换机中的4个;有四个spline plane。一层和二层交换机分别连接到[FB 2019]更大、更具伸缩性的二层或ToR交换机。对于一些最大的数据中心运营商来说,这些交换机是用有用的、现成的、商用的硅材料在内部建造的[Greenberg 2009b; Roy 2015; Singh 2015];而不是从交换机供应商那里购买。
如图6.31所示,并在上述讨论的数据中心体系结构中实现的多交换机层(分层,多级)互连网络被称为Clos网络,以Charles Clos命名,他在电话交换环境中研究了这种网络[Clos 1953]。从那时起,一种丰富的Clos网络理论被开发出来,发现在数据中心网络和多处理器互连网络中有额外的应用。
SDN中心化控制和管理
由于数据中心是由单一组织管理的,因此许多最大的数据中心运营商,包括谷歌、微软和Facebook,都很自然地接受了类似SDN的逻辑上中心化控制的概念。它们的架构也反映了数据平面(由相对简单的商用交换机组成)和基于软件的控制平面的明确分离,正如我们在5.5节中看到的那样。由于他们的数据中心规模巨大,自动化配置和操作状态管理,正如我们在第5.7节中遇到的,也是至关重要的。
虚拟化
虚拟化一直是云计算和数据中心网络发展的主要驱动力。虚拟机(VM)将运行应用程序的软件与物理硬件解耦。这种解耦还允许在可能位于不同机架上的物理服务器之间无缝迁移VM。标准以太网和IP协议在支持VM移动的同时保持跨服务器的活跃网络连接方面有局限性。由于所有数据中心网络都由单个管理机构管理,因此一个优雅的解决方案是将整个数据中心网络视为一个单一的、扁平的第二层网络。回想一下,在典型的以太网网络中,ARP协议维护IP地址和接口MAC地址的绑定关系。为了模拟所有主机连接到单个交换机的效果,ARP机制被修改为使用DNS风格的查询系统,而不是广播,且表项维护分配给虚拟机的IP地址的映射关系,以及虚拟机当前在数据中心网络中连接的物理交换机。实现这一基本设计的可扩展方案已在[Mysore 2009;Greenberg 2009b]中,并已成功部署到现代数据中心。
物理约束
与广域网不同的是,数据中心网络不仅具有非常高的容量(40Gbps和100Gbps链路现在很常见),而且具有极低的延迟(微秒)。因此,缓冲区大小很小,而拥塞控制协议(如TCP及其变体)在数据中心中不能很好地扩展。在数据中心,拥塞控制协议必须快速反应并在极低丢包的环境下运行,因为丢包恢复和超时会导致效率极低。解决这个问题的几种方法已经被提出并部署,从数据中心特定的TCP变体[Alizadeh 2010]到在标准以太网上实现远程直接内存访问(RDMA,Remote Direct Memory Access)技术[Zhu 2015;Moshref 2016;Guo 2016]。调度理论也被应用于开发将流量调度与速率控制解耦的机制,使非常简单的拥塞控制协议得以实现,同时保持链路的高利用率[Alizadeh 2013; Hong 2012]。
硬件模块化和定制
另一个主要趋势是采用基于航运集装箱(shipping container–based)的模块化数据中心(MDC) [YouTube 2009;Waldrop 2007]。在MDC中,工厂在一个标准的12米运输集装箱中构建一个小型数据中心,并将集装箱运送到数据中心位置。每个集装箱有多达几千台主机,堆放在几十个架子上,这些架子紧密地挤在一起。在数据中心位置,多个集装箱相互连接,也可以通过Internet连接。一旦在数据中心部署了预制集装箱,通常很难进行维修。因此,每个集装箱都被设计成可以降低性能:当组件(服务器和交换机)随着时间的推移发生故障时,集装箱继续运行,但性能下降。当许多组件发生故障且性能下降到阈值以下时,整个集装箱将被移除并替换为一个新的集装箱。
用集装箱构建数据中心带来了新的网络挑战。对于MDC,有两种类型的网络:每个集装箱内的集装箱内部网络和连接每个集装箱的核心网络[Guo 2009;Farrington 2010]。在每个集装箱内,在多达几千台主机的规模上,可以使用廉价的商用千兆以太网交换机建立一个完全连接的网络。然而,核心网络的设计仍然是一个具有挑战性的问题,它连接数百到数千个集装箱,同时为典型的工作负载提供跨集装箱的高主机到主机带宽。在[Farrington 2010]中描述了一种用于互联集装箱的混合电/光交换机架构。
另一个重要的趋势是,大型云提供商越来越多地构建或定制其数据中心中的所有东西,包括网络适配器、交换机路由器、TOR、软件和网络协议[Greenberg 2015;Singh 2015]。由亚马逊(Amazon)开创的另一个趋势是通过可用性区域来提高可靠性,即在附近不同的建筑中复制不同的数据中心。通过将建筑物设置在附近(相距几公里),事务性数据可以在同一可用性区域内跨数据中心同步,同时提供容错功能[Amazon 2014]。更多的数据中心设计创新可能会继续出现。
回顾:网络页面请求
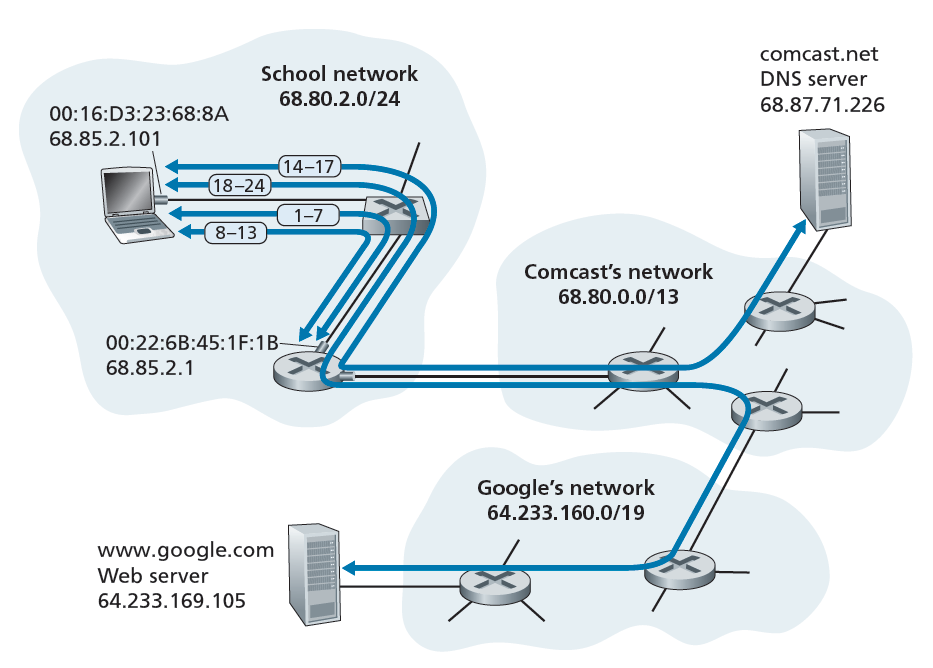
既然我们已经在本章中介绍了链路层,并在前面的章节中介绍了网络层、传输层和应用层,那么我们的协议栈之旅就完成了!在这本书的最开始(1.1节),我们写了这本书的大部分是关于计算机网络协议的,在前五章,我们已经肯定地看到这确实是这样的情况!在进入本书第二部分的主题章节之前,我们想通过对我们到目前为止所学到的协议进行综合的、整体的观察来结束我们的协议栈之旅。有一种方法可以了解全局,即确定在满足最简单的请求(下载Web页面)时所涉及的许多(很多!)协议。图6.32演示了我们的设置:学生Bob将笔记本电脑连接到学校的以太网交换机,并下载了一个Web页面(例如www.google.com的主页)。正如我们现在所知道的,要满足这个看似简单的请求,需要进行很多工作。本章末尾的Wireshark实验室更详细地分析了包含许多在类似场景中涉及的数据包的跟踪文件。
6.7.1 开始:DHCP、UDP、IP和以太网
假设Bob启动他的笔记本电脑,然后将它连接到连接到学校以太网交换机的以太网线上,该以太网交换机又连接到学校的路由器,如图6.32所示。学校的路由器连接到ISP(如comcast.net)。在本例中,comcast.net为学校提供DNS服务;因此,DNS服务器驻留在Comcast网络而不是学校网络。我们将假设DHCP服务器在路由器内运行,这是常见的情况。
当Bob第一次将他的笔记本电脑连接到网络时,如果没有IP地址,他就不能做任何事情(例如下载网页)。因此,Bob的笔记本电脑所采取的第一个与网络相关的操作是运行DHCP协议,从本地DHCP服务器获取IP地址以及其他信息:
- Bob笔记本电脑上的操作系统创建了一个DHCP请求消息(章节4.3.3),并将该消息放在一个UDP段(章节3.3)中,目标端口67 (DHCP服务器)和源端口68 (DHCP客户端)。然后UDP段被放置在一个IP数据报(章节4.3.1)中,带有广播IP目标地址(255.255.255.255)和源IP地址0.0.0.0,因为Bob的笔记本电脑还没有IP地址。
- 然后,包含DHCP请求消息的IP数据报被放置在以太网帧中(章节6.4.2)。以太网帧的目标MAC地址为FF:FF:FF:FF:FF:FF,这样帧将被广播到连接到交换机的所有设备(希望包括DHCP服务器);帧的源MAC地址是Bob的笔记本电脑的MAC地址,00:16:D3:23:68:8A。
- 包含DHCP请求的广播以太网帧是Bob的笔记本电脑向以太网交换机发送的第一帧。交换机将传入的帧广播到所有传出的端口,包括连接到路由器的端口。
- 路由器在其MAC地址为00:22:6B:45:1F:1B的接口上接收到包含DHCP请求的广播以太网帧,并从该以太网帧中提取IP数据报。数据报的广播IP目标地址表示该IP数据报需要在该节点上被上层协议处理,因此数据报的负载(UDP段)被解复用(章节3.2),直到UDP, DHCP请求数据包从UDP段中提取出来。DHCP服务器现在有了DHCP请求消息。
- 让我们假设运行在路由器内的DHCP服务器可以在CIDR(章节4.3.3)块 68.85.2.0/24中分配IP地址。在这个例子中,学校中使用的所有IP地址都在Comcast的地址块中。假设DHCP服务器分配给Bob的笔记本电脑地址为68.85.2.101。DHCP服务器创建一个DHCP ACK消息(章节4.3.3),其中包含此IP地址、DNS服务器的IP地址(68.87.71.226)、默认网关路由器的IP地址(68.85.2.1)和子网块(68.85.2.0/24)(相当于网络掩码)。DHCP消息被放置在UDP段中,UDP段被放置在IP数据报中,IP数据报被放置在以太网帧中。以太网帧包含路由器到家庭网络接口的源MAC地址(00:22:6B:45:1F:1B)和Bob笔记本电脑的目标MAC地址(00:16:D3:23:68:8A)。
- 包含DHCP ACK的以太网帧由路由器(单播)发送到交换机。因为交换机是自学的(Section 6.4.3),并且之前从Bob的笔记本电脑收到了一个以太网帧(包含DHCP请求),所以交换机知道只将地址为00:16:D3:23:68:8A的帧转发到Bob的笔记本电脑的输出端口。
- Bob的笔记本电脑收到包含DHCP ACK的以太网帧后,从以太网帧中提取IP数据报,从IP数据报中提取UDP段,再从UDP段中提取DHCP ACK消息。然后Bob的DHCP client记录自己的IP地址和DNS server的IP地址。它还将默认网关的地址安装到它的IP转发表中(章节4.1)。Bob的笔记本电脑将把目标地址在其子网68.85.2.0/24以外的所有数据报发送到默认网关。至此,Bob的笔记本电脑已经初始化了它的网络组件,并准备开始处理Web页面获取。(请注意,在第四章中介绍的四个DHCP步骤中,只有最后两个步骤是必要的。)
6.7.2 DNS和ARP
当Bob在他的Web浏览器中输入www.google.com的URL时,他开始了一长串的事件,最终将导致他的Web浏览器显示谷歌的主页。Bob的Web浏览器通过创建一个TCP套接字(第2.7节)开始这个进程,该套接字将被用来向www.google.com发送HTTP请求(第2.2节)。为了创建套接字,Bob的笔记本电脑需要知道www.google.com的IP地址。我们在第2.5节中了解到,DNS协议用于提供名称到IP地址转换服务。
- Bob的笔记本电脑上的操作系统因此创建了一个DNS查询消息(第2.5.3节),将字符串www.google.com放入DNS消息的question部分。然后将此DNS消息放置在目标端口为53 (DNS服务器)的UDP段中。然后将UDP段放入IP数据报中,目标地址为68.87.71.226(步骤5中DHCP ACK返回的DNS服务器地址),源地址为68.85.2.101。
- 然后Bob的笔记本电脑将包含DNS查询消息的数据报放置在以太网帧中。这个帧将被发送到Bob学校网络的网关路由器。但是,即使Bob的笔记本电脑通过上述第5步中的DHCP ACK消息知道学校网关路由器(68.85.2.1)的IP地址,它也不知道网关路由器的MAC地址。为了获得网关路由器的MAC地址,Bob的笔记本电脑将需要使用ARP协议(章节6.4.1)。
- Bob的笔记本电脑创建了一个目标IP地址为68.85.2.1(默认网关)的ARP查询消息,将ARP消息放置在一个广播目标地址为(FF:FF:FF:FF:FF:FF:FF)的以太网帧中,并将该以太网帧发送给交换机,交换机将该以太网帧发送给所有连接的设备,包括网关路由器。
- 网关路由器在到学校网络的接口上收到包含ARP查询消息的帧,发现ARP消息中的目标IP地址为68.85.2.1,与自己的接口IP地址匹配。这样,网关路由器就准备了一个ARP应答,表明自己的MAC地址为00:22:6B:45:1F:1B,对应于IP地址68.85.2.1。它将ARP应答消息放置在目标地址为00:16:D3:23:68:8A (Bob的笔记本电脑)的以太网帧中,并将帧发送给交换机,交换机再将帧发送给Bob的笔记本电脑。
- Bob的笔记本收到包含ARP应答消息的帧后,从ARP应答消息中提取出网关路由器的MAC地址(00:22:6B:45:1F:1B)。
- Bob的笔记本电脑现在(终于!)可以为包含网关路由器MAC地址的DNS查询的以太网帧指定地址。需要注意的是,此帧中的IP数据报的IP目标地址为68.87.71.226 (DNS服务器),而此帧的目标地址为00:22:6B:45:1F:1B(网关路由器)。Bob的笔记本电脑将此帧发送给交换机,交换机再将此帧发送给网关路由器。
6.7.3 域内路由到DNS服务器
- 网关路由器接收帧并提取包含DNS查询的IP数据报。路由器查找该数据报的目标地址(68.87.71.226),并从转发表中确定该数据报应该发送到图6.32中Comcast网络中最左边的路由器。IP数据报被放置在连接学校路由器和Comcast路由器最左边的链路的链路层帧中,并通过该链路发送。
- 在Comcast网络中,最左边的路由器收到帧后,提取出IP数据报,检查数据报的目标地址(68.87.71.226),然后从由Comcast的域内协议(RIP、OSPF或IS-IS,章节5.3)或Internet的域间协议BGP(章节5.4)填写的转发表中,确定将该数据报转发给到DNS服务器的传出接口。
- 最终,包含DNS查询的IP数据报到达DNS服务器。DNS服务器提取DNS查询消息,在其DNS数据库(章节2.5)中查找“www.google.com”这个名称,然后找到包含“www.google.com”的IP地址(64.233.169.105)的DNS资源记录。(假设当前缓存在DNS服务器中)。回想一下,这些缓存的数据来自google.com的权威DNS服务器(章节2.5.2)。DNS服务器形成一个包含这个主机名到IP地址映射的DNS应答消息,并将DNS应答消息放置在一个UDP段中,这个段位于一个IP数据报中,地址为Bob的笔记本电脑(68.85.2.101)。该数据报将通过Comcast网络发送回学校的路由器,再从那里通过以太网交换机发送到Bob的笔记本电脑。
- Bob的笔记本电脑从DNS消息中提取服务器www.google.com的IP地址。最后,经过大量工作,Bob的笔记本电脑现在可以与www.google.com服务器联系了。
6.7.4 Web客户端-服务器交互:TCP和HTTP
- 既然Bob的笔记本电脑有www.google.com的IP地址,它就可以创建TCP套接字(节2.7),用于将HTTP GET消息(节2.2.3)发送到www.google.com。当Bob创建TCP套接字时,Bob笔记本电脑中的TCP必须首先与www.google.com中的TCP执行三次握手(章节3.5.6)。Bob的笔记本电脑因此首先创建一个目标端口为80(用于HTTP)的TCP SYN段,将TCP段放入一个目标IP地址为64.233.169.105 (www.google.com)的IP数据报中,将数据报放入一个目标MAC地址为00:22:6B:45:1F:1B(网关路由器)的帧中,并将该帧发送给交换机。
- 学校网络、Comcast网络和谷歌网络中的路由器使用每个路由器中的转发表将包含TCP SYN的数据报转发到www.google.com,如上步骤14和16所示。回想一下,在Comcast和谷歌网络之间的域间链路上,控制数据包转发的路由器转发表项是由BGP协议决定的(第5章)。
- 最终,包含TCP SYN的数据报到达www.google.com。TCP SYN消息从数据报中提取,并解复用到与端口80关联的欢迎套接字。为谷歌HTTP服务器和Bob的笔记本电脑之间的TCP连接创建了一个连接套接字(章节2.7)。生成一个TCP SYNACK(章节3.5.6)段,放置在指向Bob笔记本电脑的数据报中,最后放置在一个适合于连接www.google.com到其第一跳路由器的链路的链路层帧中。
- 包含TCP SYNACK段的数据报通过谷歌、Comcast和学校网络转发,最终到达Bob笔记本电脑中的以太网控制器。数据报在操作系统中被解复用到步骤18中创建的TCP套接字,该套接字进入连接状态。
- Bob的笔记本电脑上的套接字现在(终于!)准备向www.google.com发送字节,Bob的浏览器创建HTTP GET消息(第2.2.3节),其中包含要获取的URL。然后将HTTP GET消息写入套接字,GET消息成为TCP段的有效负载。TCP段放在一个数据报中,并按照上面的步骤18和20发送和交付到www.google.com。
- www.google.com上的HTTP服务器从TCP套接字读取HTTP GET消息,创建HTTP响应消息(章节2.2),将请求的Web页面内容放在HTTP响应消息的主体中,并将消息发送到TCP套接字。
- 包含HTTP应答消息的数据报通过谷歌、Comcast和学校网络转发,并到达Bob的笔记本电脑。Bob的Web浏览器程序从套接字读取HTTP响应,从HTTP响应主体提取Web页面的html,最后(终于!)显示Web页面!
我们上面的场景涵盖了大量的网络基础!如果您已经理解了上述示例的大部分或全部内容,那么从您第一次阅读第1.1节以来,您也已经学习了很多基础知识,在1.1节中,我们编写了本书的大部分内容,都是关于计算机网络协议的,您可能想知道协议到底是什么!虽然上面的例子看起来很详细,但我们已经忽略了许多可能的附加协议(例如,在学校的网关路由器上运行的NAT、无线接入到学校网络、接入学校网络的安全协议或加密段或数据报、网络管理协议),以及人们在公共互联网中可能遇到的考虑事项(Web缓存、DNS层次结构)。我们将在本书的第二部分中讨论这些主题的一些内容。
最后,我们注意到我们上面的例子是一个完整的、整体的,但也是非常具体的,我们在本书第一部分中研究的许多协议的视图。这个例子更关注如何做而不是为什么。要获得关于网络协议总体设计的更广泛、更具有反思性的观点,您可能需要重新阅读4.5节中的Internet架构原则及其参考文献。
总结
在本章中,我们研究了链路层——它的服务、其操作的基础原则,以及在实现链路层服务时使用这些原则的许多重要的特定协议。
我们看到链路层的基本服务是将网络层数据报从一个节点(主机、交换机、路由器、WiFi接入点)移动到相邻的节点。我们看到,所有的链路层协议都是这样操作的:先将网络层数据报封装在链路层帧中,然后再通过链路将帧传输到相邻的节点。然而,除了这个常见的帧功能之外,我们还了解到不同的链路层协议提供非常不同的链路接入、交付和传输服务。这些差异的部分原因是链路层协议必须在各种各样的链路类型上运行。一个简单的点对点链路有一个单一的发送者和接收者通过一条线路进行通信。多个接入链路在多个发送方和接收方之间共享;因此,多路接入信道的链路层协议有一个协调链路接入的协议(它的多路接入协议)。在MPLS组网中,连接两个相邻节点(例如,在IP意义上相邻的两台IP路由器)的链路——感觉它们是指向某个目的地的下一跳IP路由器)实际上可能本身就是一个网络。从某种意义上说,把一个网络看作一个链路的想法似乎并不奇怪。例如,将家庭调制解调器/计算机连接到远程调制解调器/路由器的电话链路,实际上是一条通过复杂的电话网络的路径。
在链路层通信的基础原理中,我们研究了错误检测和纠正技术、多路接入协议、链路层寻址、虚拟化(VLAN),以及扩展的交换式局域网和数据中心网络的构建。目前链路层的重点主要集中在这些交换式网络上。在错误检测/纠正的情况下,我们研究了如何在帧头中添加额外的位,以检测和在某些情况下纠正在链路上传输时可能发生的位翻转错误。我们讨论了简单的奇偶校验和校验和(checksumming)方案,以及更健壮的循环冗余校验。然后我们转向了多路接入协议的主题。我们确定并研究了三种广泛的方法来协调对广播信道的接入:信道分区方法(TDM, FDM),随机接入方法(ALOHA协议和CSMA协议),以及轮流接入方法(轮询和令牌传递)。我们研究了有线接入网,发现它使用了许多这些多种接入方式。我们看到,让多个节点共享一个广播信道的后果是需要在链路层提供节点地址。我们了解到链路层地址与网络层地址有很大的不同,在互联网上,一个特殊的协议(ARP——地址解析协议)用于在这两种寻址形式之间进行转换,并详细研究了非常成功的以太网协议。然后,我们研究了共享广播信道的节点如何形成局域网,以及如何将多个局域网连接在一起形成更大的局域网——所有这些都不需要网络层路由的干预来互连这些本地节点。我们还了解了如何在单个物理LAN基础设施上创建多个虚拟LAN。
在结束对链路层的研究时,我们着重介绍了MPLS网络在连接IP路由器时如何提供链路层服务,并概述了当今海量数据中心的网络设计。我们通过确定获取一个简单Web页面所需的许多协议来结束本章(实际上也是前五章)。覆盖了链路层之后,我们沿着协议栈的旅程现在结束了!当然,物理层位于链路层之下,但是!物理层的细节可能最好留给另一门课程(例如,在通信理论,而不是计算机网络)。然而,我们已经在本章和第一章(我们在1.2节讨论物理媒体)中触及了物理层的几个方面。我们将在下一章研究无线链路特性时再次考虑物理层。
虽然我们对协议栈的研究已经结束,但我们对计算机网络的研究还没有结束。在接下来的三章中,我们将介绍无线网络、网络安全和多媒体网络。这四个主题不适合放在任何一个层中;实际上,每个主题都横切了许多层。因此,理解这些主题(在某些网络文本中被称为高级主题)需要在协议栈的所有层中打下坚实的基础——我们对链路层的研究现在已经完成了这个基础!