第五章 网络层:控制平面
第五章 网络层:控制平面
在本章中,我们将通过覆盖网络层的控制平面组件来完成网络层的旅程——这个全网络(network-wide)逻辑不仅控制数据报如何沿着从源主机到目标主机的端到端路径进行路由,还包括如何配置和管理网络层组件和服务。在第5.2节中,我们将讨论计算图(graph)中最小开销路径的传统路由算法;这些算法是两种广泛部署的互联网路由协议的基础:OSPF和BGP,我们将分别在第5.3节和5.4节中介绍。正如我们将看到的,OSPF是一个在单个ISP网络中运行的路由协议。BGP是一种路由协议,用于连接Internet中的所有网络;因此,BGP通常被称为将互联网连接在一起的粘合剂。传统上,控制平面路由协议与数据平面转发功能一起在路由器中整体实现。正如我们在第4章的介绍中所了解到的,软件定义网络(SDN)在数据和控制平面之间进行了明确的分离,在一个独立的控制器服务中实现控制平面的功能,该服务与它控制的路由器的转发组件是不同的,而且是远程的。我们将在第5.5节中介绍SDN控制器。
在第5.6和5.7节中,我们将介绍管理IP网络的一些基本原理:ICMP(the Internet Control Message Protocol)和SNMP(the Simple Network Management Protocol)。
5.1 介绍
让我们通过回顾图4.2和4.3来快速设置我们学习网络控制平面的环境。在这里,我们看到转发表(基于目的地的转发)和流表(广义转发)是连接网络层的数据和控制平面的主要元素。我们了解到,这些表指定了路由器的本地数据平面转发行为。我们看到,在广义转发的情况下,所采取的操作不仅包括将数据包转发到路由器的输出端口,还包括丢弃数据包、复制数据包和/或重写第2层、第3层或第4层数据包头字段。
在本章中,我们将学习如何计算、维护和安装那些转发表和流表。在第4.1节对网络层的介绍中,我们了解到有两种可能的实现方法。
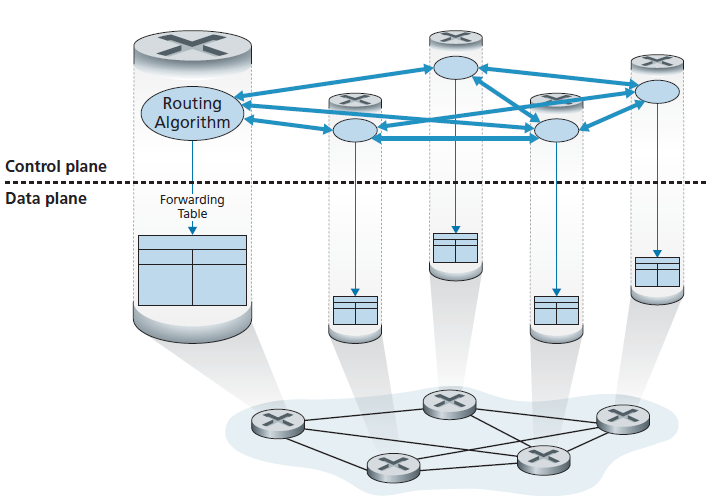
- Per-router control 图5.1阐明了路由算法在每个路由器中运行的情况;每台路由器都包含转发和路由功能。每台路由器都有一个路由组件,该组件与其他路由器的路由组件通信,计算其转发表的值。这种逐--路由器控制的方法在互联网上已经使用了几十年。我们将在章节5.3和5.4中学习的OSPF和BGP协议就是基于这种逐-路由器的控制方法。
- Logically centralized control 图5.2阐明了一个逻辑上中心化的控制器计算和分配每台路由器使用的转发表的情况。正如我们在第4.4节和4.5节中看到的,广义的match-plus-action抽象允许路由器执行传统的IP转发以及一组丰富的其他功能(负载共享、防火墙和NAT),这些功能以前都是在单独的中间件中实现的。
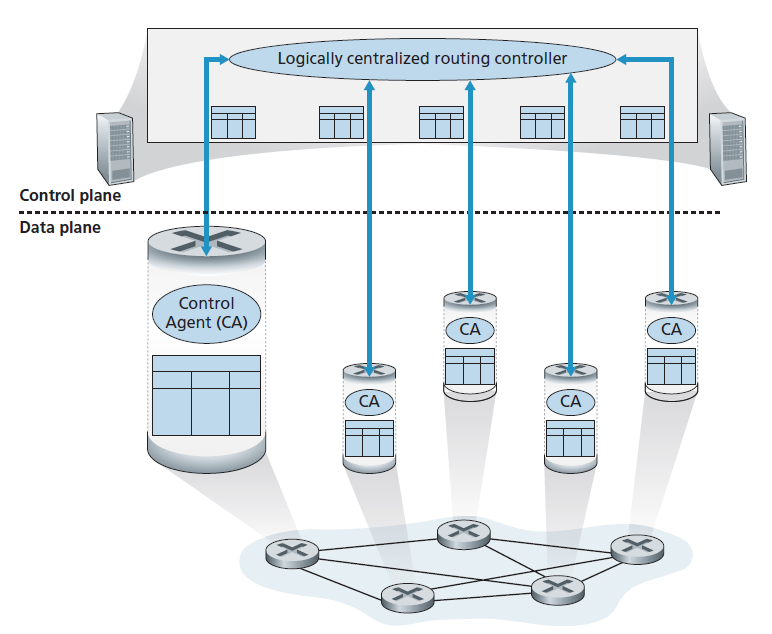
控制器通过定义良好的协议与每个路由器中的控制代理(CA)交互,以配置和管理路由器的流表。通常,CA具有最低限度的功能;它的工作是与控制器通信,并执行控制器的命令。与图5.1中的路由算法不同,CA之间不直接交互,也不主动参与转发表的计算。这是逐-路由器控制和逻辑上中心化的控制之间的一个关键区别。
通过逻辑上中心化的控制[Levin 2012],我们的意思是路由控制服务就像它是一个单一的中心服务点被访问,即使服务可能因容错和性能可伸缩性的原因通过多个服务器实现。正如我们将在5.5节中看到的,SDN采用了逻辑上中心化的控制器的概念——一种在生产部署中得到了越来越多的应用的方法。谷歌使用SDN来控制其内部B4全球广域网中的路由器,该网络连接其数据中心[Jain 2013]。SWAN [Hong 2013],来自Microsoft Research,使用逻辑上中心化的控制器来管理广域网和数据中心网络之间的路由和转发。主要的ISP部署,包括COMCAST的ActiveCore和德国电信的Access 4.0正在积极地将SDN整合到他们的网络中。正如我们将在第8章中看到的,SDN控制也是4G/5G蜂窝网络的中心。[AT&T 2019]指出,SDN不是一个愿景、目标或承诺。这是现实。到明年年底,我们75%的网络功能将完全虚拟化和软件控制。中国电信和中国联通都在数据中心内部和数据中心之间使用SDN [Li 2015]。
5.2 路由算法
在本节中,我们将学习路由算法,其目标是通过路由器网络确定从发送方到接收方的良好路径(good paths)。一般来说,“好的”路径是开销最低的路径。然而,我们将在实践中看到,现实世界的关注如政策问题(例如,属于组织Y的路由器x,不应该转发来自组织Z的网络的任何数据包)也会发挥作用。我们注意到,无论网络控制平面是采用逐-路由器控制方式还是逻辑上中心化的控制方式,都必须始终有一个定义良好的路由器序列,以便数据包从发送主机传输到接收主机。因此,计算这些路径的路由算法是非常重要的,也是最重要的10个网络概念之一。
图是用来描述路由问题的。回忆一下, 图 G = (N, E)是节点N的集合(set)和边E的集合(collection),其中每条边是来自N的一对节点。在网络层路由的环境中,图中的节点代表路由器——作出数据包转发决策的点——连接这些节点的边代表这些路由器之间的物理链路。这样一个计算机网络的图抽象如图5.3所示。在研究BGP域间路由协议时,我们会发现节点代表网络,连接两个节点的边代表两个网络之间的方向连通性(即对等网络)。查看一些代表真实网络地图的图,见[CAIDA 2020];关于不同的基于图的模型如何很好地建模互联网的讨论,参见[Zegura 1997, Faloutsos 1999, Li 2004]。
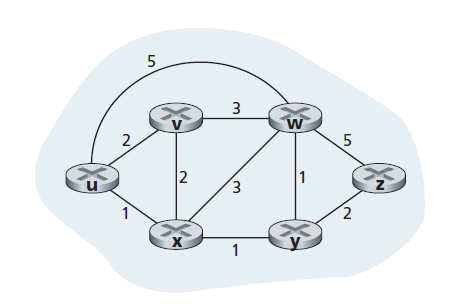
如图5.3所示,一条边也有一个值表示它的开销(cost)。通常,边的开销可以反映相应链路的物理长度(例如,跨洋链路的开销可能高于短途陆地链路)、链路速度或与链路相关的货币开销。就我们的目的而言,我们将简单地把边开销作为一个给定的值,而不用担心如何确定它们。对于E中的任意边(x, y),我们记c(x, y)为节点x和节点y之间的边的开销。如果(x, y)对不属于E,则设c(x, y) = ∞。此外,在我们的讨论中,我们只考虑无向图(即边没有方向的图),因此,边(x, y)与边(y, x)相同,且c(x, y) = c(y, x);然而,我们将要研究的算法可以很容易地扩展到在每个方向上具有不同开销的有向链路的情况。另外,如果(x, y)属于E,则节点y是节点x的 邻居 。
假设在图抽象中,开销被分配给各个边,那么路由算法的一个自然目标就是确定源和目的地之间开销最小的路径。为了更准确地说明这个问题,回想一下,一个路径在一个图G = (N, E)中是一系列的节点(x1, x2 , ..., xp ),这样每一个节点对(x1, x2), (x2,x3)、...、 (xp-1, xp)是E中的边。路径(x1, x2, ..., xp)的开销是所有边开销总和,即c (x1, x2), c(x2,x3)、...、 c(xp-1, xp)。给定任意两个节点x和y,两个节点之间通常有许多路径,每条路径都有开销。其中一条或多条路径是开销最低的路径。因此,开销最低的问题很清楚:在源和目标之间找到一条开销最低的路径。例如,在图5.3中,从源节点u到目标节点w的最小开销路径为(u, x, y, w),开销为3。注意,如果图中所有的边都有相同的开销,那么最小开销的路径也是最短的路径(也就是说,源和目标之间的链路数量最小的路径)。
作为一个简单的练习,请尝试在图5.3中找到从节点u到z的最小开销路径,并思考一下如何计算该路径。如果你和大多数人一样,你会通过查看图5.3找到从u到z的路径,追踪一些从u到z的路径,并以某种方式让自己相信你选择的路径在所有可能路径中开销最小。(你检查了u和z之间所有的17条可能路径了吗?可能不是!)这样的计算是一个中心化的路由算法的例子——路由算法在一个地方运行,你的大脑,有完整的网络信息。一般来说,我们分类路由算法的一种方法是根据它们是中心化的还是非中心化的。
一个 中心化的路由算法 使用完整的、全局的网络信息计算出源和目的地之间的最小开销路径。也就是说,该算法将所有节点之间的连通性和所有链路开销作为输入。这就要求算法在实际执行计算之前以某种方式获取这些信息。计算本身可以在一个站点运行(例如,如图5.2所示的逻辑上中心化的控制器),也可以在每个路由器的路由组件中复制(例如,如图5.1所示)。然而,这里的关键特征是,该算法具有关于连接和链路开销的完整信息。具有全局状态信息的算法通常被称为 链路状态(LS,link-state)算法 ,因为该算法必须知道网络中每条链路的开销。我们将在第5.2.1节研究LS算法。
在一个 非中心化的路由算法 中,最小开销路径的计算是由路由器以迭代、分布式的方式进行的。没有一个节点有关于所有网络链路开销的完整信息。相反,每个节点一开始只知道自己直接连接的链路的开销。然后,通过迭代计算进程与相邻节点交换信息,节点逐渐计算出到达一个或一组目的地的最小开销路径。下面我们将在第5.2.2节中研究的非中心化的路由算法称为 距离向量 (DV,distance-vector)算法,因为每个节点维护一个网络中所有其他节点的开销(距离)的估算值的向量。这种在相邻路由器之间进行交互式消息交换的非中心化的算法可能更适合于路由器间直接交互的控制平面,如图5.1所示。
第二种分类路由算法的广泛方法是根据它们是静态的还是动态的。在 静态路由算法 中,路由变化非常缓慢,通常是人为干预的结果(例如,人工编辑链路开销)。 动态路由算法 会随着网络流量或拓扑结构的变化而改变路由路径。动态算法可以周期性地运行,也可以直接响应拓扑结构或链路开销的变化。虽然动态算法对网络变化更敏感,但它们也更容易受到路由环路(routing loops)和路由振荡(route oscillation)等问题的影响。
第三种分类路由算法的方法是根据它们是负载敏感还是负载不敏感。在 负载敏感算法 中,链路开销会动态变化,以反映底层链路当前的拥塞水平。如果当前拥塞的链路有较高的开销,路由算法将倾向于选择绕过这种拥塞的链路的路由。虽然早期的ARPAnet路由算法是负载敏感的[McQuillan 1980],但遇到了许多困难[Huitema 1998]。目前的互联网路由算法(如RIP、OSPF和BGP)是负载不敏感的,因为一条链路的开销并不能明确反映其当前(或最近过去)的拥塞水平。
5.2.1 LS路由算法
回忆一下,在链路状态算法中,网络拓扑和所有链路开销都是已知的,也就是说,可以作为LS算法的输入。在实践中,这是通过让每个节点向网络中的所有其他节点广播链路状态数据包来实现的,每个链路状态数据包包含其所附链路的身份和开销。在实践中(例如,使用Internet的OSPF路由协议,在第5.3节中讨论),这通常是通过 链路状态广播 (link-state broadcast)算法来实现的[Perlman 1999]。节点广播的结果是,所有节点都拥有相同和完整的网络视图。然后,每个节点可以运行LS算法,并与其他节点一样计算出最小开销路径集。
下面我们介绍的链路状态路由算法称为Dijkstra算法,以其发明者的名字命名。一个密切相关的算法是Prim算法;图算法的一般讨论见[Cormen 2001]。Dijkstra算法计算从一个节点(源节点,我们称其为u)到网络中所有其他节点的最小开销路径。Dijkstra算法是迭代的且具有这样的属性:在算法第k次迭代后,k个目标节点知晓最小开销路径,在所有目标节点的最小开销路径中,这k条路径有k个最小开销。让我们定义以下符号:
- D(v):此算法迭代时源节点到目标节点v的最小开销路径的开销。
- p(v):当前从源节点到节点v的最小开销路径上的前一个节点(v的邻居)。
- N':节点的子集,如果从源节点到节点v的最小开销路径已知,则v在N'中。
中心化的路由算法由一个初始化步骤和一个循环组成。循环执行的次数等于网络中节点的数量。在终止时,算法将计算出从源节点u到网络中每一个其他节点的最短路径。
源节点u的链路状态(LS)算法
1 初始化:
2 N' = {u}
3 对所有的节点p
4 如果p是u的邻居
5 则 D(p) = c(u,p)
6 否则 D(p) = ∞
7
8 循环:
9 找到不在N'中的q使D(q)最小
10 添加 q 到 N'
11 为q的每一个不在N'中的邻居r更新D(r):
12 D(r) = min(D(r), D(q)+ c(q,r) )
// r的新开销是旧的r开销或D(q)+ c(q,r)
14 直到 N' = N例如,让我们考虑图5.3中的网络,并计算从u到所有可能目的地的最小开销路径。表5.1给出了算法计算的表格总结,表格中的每一行给出了迭代结束时算法变量的值。让我们仔细考虑一下最初的几个步骤。
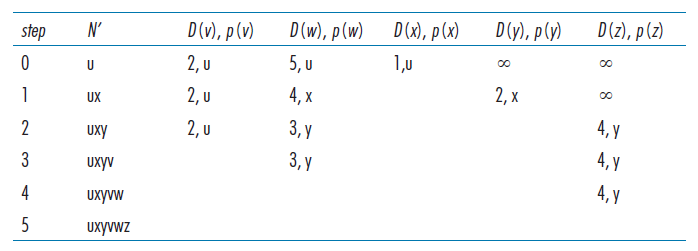
- 在初始化步骤中,当前已知的从u到其直接相连的邻居v、x和w的最小开销路径的开销分别被初始化为2、1和5。特别注意, 将w开销设置为5(即使我们很快就会看到,开销更低的路径确实存在)因为这是从u到w的直接(单跳)链路的开销。y和z的开销将是无穷,因为他们不直接连接到u。
- 在第一次迭代中,我们寻找那些尚未加入集合N'的节点,并找到在前一次迭代结束时开销最小的节点。该节点为x,开销为1,因此x被加入集合N'。然后执行LS算法的第12行,对所有节点r更新D(r),结果如表5.1中的第二行(步骤1)所示。到v的路径的开销不变。通过x到w(初始化结束时为5)的路径的开销为4。因此,这个低开销的路径被选择,p(w)被设置为x。类似地,到y(通过x)的开销被计算为2,并相应地更新表。
- 在第二次迭代中,发现节点v和y是开销最小的路径(2),我们打破僵局将y添加到N'中,所以N'现在包含u,x,y。其余节点不在N'中,即v,w,z。将通过LS算法的12行更新。产生的结果在表5.1第三行中。
- 继续...
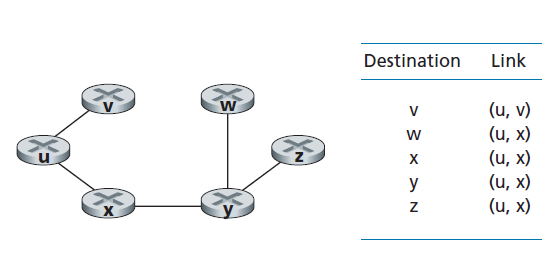
当LS算法终止时,对于每个节点,它的前一个节点(即p(v))沿着从源节点开始的最小开销路径移动。对于每个p(v),我们也有其p(v),因此,以这种方式,我们可以构建从源到所有目的地的整个路径。在一个节点中的转发表,如节点u,可以从这些信息中构建:对于每个目的地,存储从u到该目的地的最小开销路径上的下一跳节点。图5.4显示了图5.3中网络在u中得到的最小开销路径和转发表。
这个算法的计算复杂度是多少?也就是说,给定n个节点(不计算源节点),在最坏的情况下,要找到从源到所有目的地的最小开销路径,必须进行多少次计算?在第一次迭代中,我们需要搜索n个节点,以确定具有最小开销且不在N'中的节点,q。在第二次迭代中,我们需要检查n - 1个节点来确定最小开销;在第三次迭代中检查n - 2个节点,以此类推。总的来说,我们需要在所有迭代中搜索的节点总数是n(n + 1)/2,因此,前面的LS算法实现的最坏情况复杂度为n²:O(n²)(该算法的一个更复杂的实现,使用一种称为堆的数据结构,可以用对数时间而不是线性(linear)时间找到第9行中的最小值,从而降低了复杂度。)
在完成我们对LS算法的讨论之前,让我们考虑一种可能出现的异常。图5.5显示了一个简单的网络拓扑,其中链路开销等于链路上的负载,例如,反映了将会经历的延迟。在这个例子中,链路开销是不对称的;也就是说,仅当链路(u,v)上两个方向承载的负载相等时c(u,v)才等于c(v,u)。在这个例子中,节点z起始是一个单位的流量去往w,节点x起始也是一个单位的流量去往w和节点y注入一个数量为e的流量,也去往w。最初的路由是如图5.5所示,链路开销对应承载的流量。
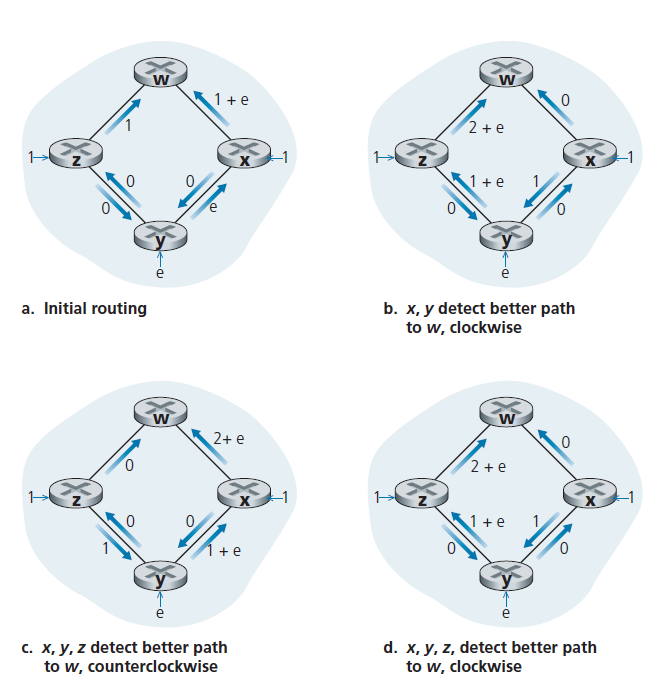
当LS算法再次运行时,节点y测定(基于图5.5 (a)链路开销),顺时针路径到w的开销为1,而逆时针路径到w(它一直使用)的开销为1 + e。因此现在y到w的最小开销路径是顺时针的。类似地,x测定了它到w的新的最小开销路径也是顺时针的,这导致了如图5.5(b)所示的开销。当接下来运行LS算法时,节点x、y和z都检测到一条到w的零开销路径,并且都将其流量路由到逆时针方向的路径上。下次运行LS算法时,x、y和z都将它们的流量顺时针路由。
如何防止这种振荡(这种振荡可能发生在任何算法中,不仅仅是LS算法,它使用拥塞或基于延迟的链路度量)?一种解决方案是强制链路开销不依赖于所承载的流量——一个不可接受的解决方案,因为路由的一个目标是避免高度拥塞(例如,高延迟)的链路。另一个解决方案是确保不是所有路由器都同时运行LS算法。这似乎是一个更合理的解决方案,因为我们希望即使路由器以相同的周期运行LS算法,算法在每个节点上的执行实例也不会相同。有趣的是,研究人员发现互联网中的路由器可以自我同步[Floyd Synchronization 1994]。也就是说,即使它们最初以相同的周期但在不同的时间点执行算法,算法执行实例最终可以在路由器上变成同步,并保持同步。避免这种自同步的一种方法是让每个路由器随机分配它发出链路通告(advertisement)的时间。
在研究了LS算法之后,让我们来考虑目前在实践中使用的另一种主要的路由算法——距离向量路由算法。
5.2.2 DV (Distance-Vector)路由算法
LS算法是一种利用全局信息的算法,而距离向量(DV)算法是迭代的、异步的和分布式的。它的分布方式是每个节点从它的一个或多个直接相连的邻居接收一些信息,进行计算,然后将计算结果分发给它的邻居。这个过程是迭代的,直到邻居之间不再交换信息为止。(有趣的是,这个算法也是自终止的——没有信号表明计算应该停止;或可能停止。)该算法是异步的,因为它不需要所有的节点彼此同步操作。我们将看到异步、迭代、自终止、分布式算法比中心化的算法有趣得多!
在我们呈现DV算法之前,讨论存在于最小开销路径间开销的关系非常有益。设dx(y)为节点x到节点y最小开销路径的开销,则最小开销与著名的Bellman-Ford方程相关,即:
dx(y) = minv{c(x, v) + dv( y)}, (5.1)
方程中的minv接管x的所有邻居。Bellman-Ford方程是相当直观的。实际上,从x到v之后,如果从v到y的路径开销最小,路径开销就是c(x, v) + dv(y),因为我们必须从某个邻居v开始,那么从x到y的最小开销就是接管的所有邻居v中c(x, v) + dv(y)的最小值。
但是,对于那些可能对该方程的有效性持怀疑态度的人,让我们检查图5.3中的源节点u和目标节点z。源节点u有三个邻居:节点v,节点x和节点w。在图中沿着不同的路径走,很容易发现dv(z) = 5, dx(z) = 3, dw(z) = 3。将这些值连同开销c(u, v) = 2, c(u, x) = 1, c(u, w) = 5代入方程5.1,得到du(z) = min{2 + 5, 5 + 3, 1 + 3} = 4,这显然是正确的,这正是Dijskstra算法在同一个网络中给我们的结果。这种快速的验证应该有助于消除您可能有的任何怀疑。
Bellman-Ford方程具有重要的实际意义:Bellman-Ford方程的解提供了节点x的转发表中的表项。为此,设v*为任何在公式5.1中达到最小值的相邻节点。然后,如果节点x想要以最小开销的路径向节点y发送数据包,则应该先将数据包转发给节点v*。因此,节点x的转发表将节点v*指定为最终目的地y的下一跳路由器。Bellman-Ford方程的另一个重要的实际贡献是,它提出了DV算法中将发生的邻居对邻居通信的形式。
其基本思想如下。每个始于Dx(y)的节点x,估算节点x到节点y最小开销路径的开销,对所有在N中的节点y,记 D x = [Dx(y): y in N]为节点x的距离向量,即从x到N中所有其他节点y估算的开销的向量。使用DV算法,每个节点x维护如下路由信息:
- 对于每个邻居v,从x到邻居v的开销是c(x,v)。
- 节点x的距离向量,即 D x = [Dx(y): y in N],包含节点x到N中所有目的地y的估算的开销。
- 其每个邻居的距离向量,即x的所有邻居v: D v = [Dv(y): y in N]。
在分布式异步算法中,每个节点会时不时地将其距离向量的副本发送给它的每个邻居。当节点x从它的任何邻居w接收到一个新的距离向量时,它保存w的距离向量,然后使用Bellman-Ford方程更新它自己的距离向量,如下所示:
Dx(y) = minv{c(x, v) + Dv(y)} 对于N中每个节点y
如果节点x的距离向量在这个更新步骤中发生了变化,节点x将向它的每个邻居发送更新后的距离向量,这些邻居可以依次更新它们自己的距离向量。令人惊奇的是,只要所有节点继续以异步方式交换它们的距离向量,每个开销估算Dx(y)收敛于dx(y),即从节点x到节点y的最小开销路径的实际开销[Bertsekas 1991]
DV算法
每个节点x:
1 初始化:
2 对所有在N的中目的地y:
3 Dx(y)= c(x,y)/*如果y不是邻居,则c(x,y)=∞*/
4 对每个邻居w:
5 Dw(y) = c(w,y) 对所有在N的中目的地y
6 对每个邻居w:
7 发送距离向量 Dx(加粗)= [Dx(y): y in N]到w
8
9 循环:
10 wait(直到看到邻居w的链路开销发生变化,或直到从邻居w收到一个距离向量)
11 对N中每一个y:
12 Dx(y) = minv{c(x,v) + Dv(y)}
13 if Dx(y)对任何目的地y发生了改变
14 发送距离向量Dx = [Dx(y): y in N]给所有邻居
15 forever在DV算法中,当节点x看到一个直接连接的链路上的开销发生变化,或者从某个邻居接收到一个距离向量更新时,它就更新它的距离向量估算。但要为给定的目标y更新自己的转发表,节点x需要知道的不是到y的最短路径距离,而是相邻节点v*(y),也就是到y的最短路径上的下一跳路由器。正如你所期望的,下一跳路由器v*(y)是DV算法第12行中达到最小值的邻居v。(如果有多个邻居v达到最小值,那么v*(y)可以是这些邻居中的任何一个。)因此,在第11 - 12行中,对于每个目标y,节点x也确定了v*(y),并更新了目标y的转发表。
回想一下,LS算法是一种中心化的算法,它要求每个节点在运行Dijkstra算法之前先获得一个完整的网络映射。DV算法是非中心化的,不使用这种全局信息。事实上,一个节点所拥有的唯一信息就是与它直接相连的邻居链路的开销,以及它从这些邻居接收到的信息。每个节点等待来自任何邻居的更新(第10行),在接收更新时计算其新的距离向量(第12行),并将其新的距离向量分配给它的邻居(第13至14行)。目前,在Internet的RIP和BGP、ISO IDRP、Novell IPX、原始的ARPAnet等路由协议中都使用了类似DV的算法。
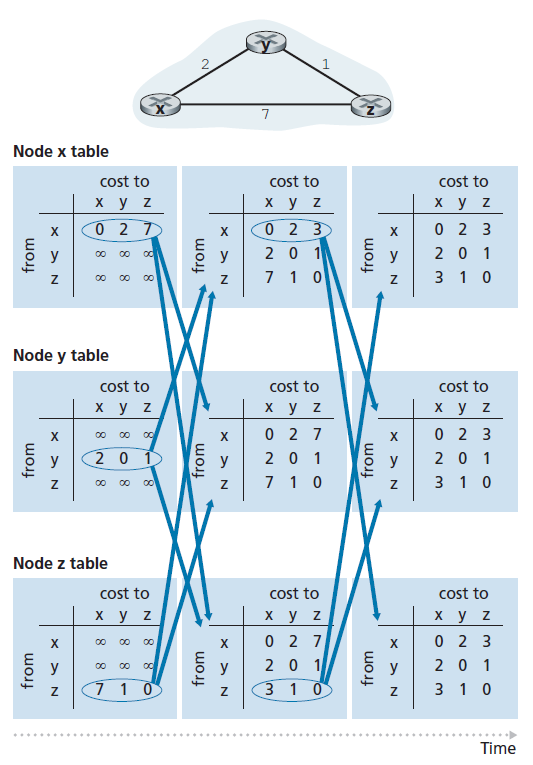
图5.6展示了DV算法对图顶部所示的简单三节点网络的操作。该算法的操作以同步方式进行说明,其中所有节点同时从其邻居接收距离向量,计算新的距离向量,并通知其邻居距离向量是否发生了变化。在研究了这个示例之后,您应该相信算法也以异步的方式正确地运行,节点计算和更新生成/接收随时发生。
图中最左边的一列为这三个节点中的每个节点显示了三个初始 路由表 。例如,左上角的表是节点x的初始路由表。在一个特定的路由表中,每一行都是一个特定的距离向量,每个节点的路由表包括它自己的距离向量和它的每个邻居的距离向量。因此,节点x初始路由表中的第一行是 D x = [Dx(x), Dx(y), Dx(z)] =[0,2,7]。该表中的第二行和第三行分别是最近从节点y和z接收到的距离向量。因为在初始化时,节点x没有从节点y或z接收到任何内容,所以第二行和第三行中的表项被初始化为无穷大。
初始化后,每个节点将其距离向量发送给它的两个邻居。图5.6中从表的第一列到表的第二列的箭头说明了这一点。例如,节点x向节点y和节点z发送距离向量 D x =[0,2,7],每个节点收到更新后,重新计算自己的距离向量。例如,节点x计算
Dx(x) = 0
Dx(y) = min{c(x,y) + Dy(y), c(x,z) + Dz(y)} = min{2 + 0, 7 + 1} = 2
Dx(z) = min{c(x,y) + Dy(z), c(x,z) + Dz(z)} = min{2 + 1, 7 + 0} = 3
因此,第二列显示了每个节点的新距离向量,以及从相邻节点接收到的距离向量。注意,例如,节点x对节点z的最小开销的估算,Dx(z),已经从7更改为3。也要注意,对于节点x, DV算法第12行相邻节点y达到最小值;因此,在算法的这一阶段,在节点x处v*(y) = y, v*(z) = y。
在节点重新计算它们的距离向量之后,它们再次将更新后的距离向量发送给它们的邻居(如果有变化的话)。图5.6中从表的第二列到表的第三列的箭头说明了这一点。注意,只有节点x和z发送更新:节点y的距离向量没有改变,所以节点y不发送更新。在接收到更新后,节点重新计算它们的距离向量并更新它们的路由表,如第三列所示。
从邻居接收更新的距离向量,重新计算路由表项,并通知邻居到达目的地的最小开销路径的开销发生了变化,这样的过程一直持续到没有更新消息发送为止。此时,由于没有发送更新消息,因此不会发生进一步的路由表计算,算法将进入静态状态;也就是说,所有的节点都将执行DV算法第10 - 11行中的等待。该算法保持在静态状态,直到链路开销发生变化,如下面所讨论的。
DV算法:链路开销变化和链路故障
当运行DV算法的节点检测到从自身到邻居的链路开销发生变化时(第10行),它更新它的距离向量(第11、12行),如果最小开销路径的开销发生变化,则用新距离向量通知它的邻居(第13、14行)。图5.7(a)说明了从y到x的链路开销从4变为1的情况。这里我们只关注y和z到目标x的距离表项。DV算法导致发生以下一系列事件:
- 在t0时刻,y检测到链路开销的变化(开销从4变成了1),更新它的距离向量,并通知它的邻居这个变化,因为它的距离向量已经改变了。
- 在t1时刻,z接收到y的更新并更新它的表。它计算到x的一个新的最小开销(它的开销从5降低到2),并将它的新距离向量发送给它的邻居。
- 在t2时刻,y收到z的更新,并更新它的距离表。y的最小开销不变,因此y不会向z发送任何消息。算法进入静止状态。
因此,DV算法只需要两次迭代就可以达到静止状态。关于x和y之间开销降低的好消息已经通过网络迅速传播开来。
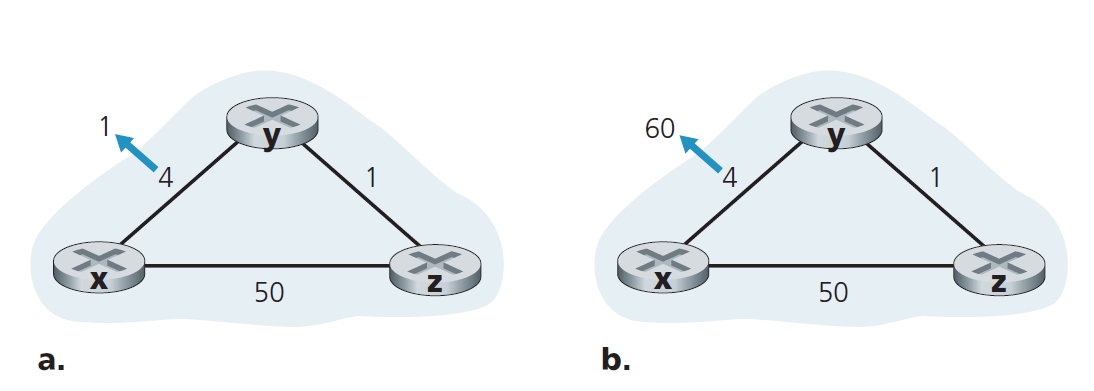
现在让我们考虑一下当链路开销增加时会发生什么。假设x和y之间的链路开销从4增加到60,如图5.7(b)所示。
- 链路开销变化前,Dy(x) = 4, Dy(z) = 1, Dz(y) = 1, Dz(x) = 5。在t0时刻,y检测到链路开销的变化(开销从4变到60)。Y计算到x的新最小开销路径的开销为
Dy(x) = min{c(y,x) + Dx(x), c(y,z) + Dz(x)} = min{60 + 0, 1 + 5} = 6
当然,从我们对网络的全局视角来看,我们可以看到这个通过z的新开销是 错误的 。但节点y的唯一信息是它到达x的直接开销是60, z最近告诉y,z到达x的开销是5(1+4)。所以为了到达x, y现在要经过z,完全期望z能够以5的开销到达x。t1时我们有一个 路由循环 (routing loop)——为了到达x, y路由过z,z又路由过y。这个路由循环就像一个黑洞——在t1时,一个发往x的数据包到达y或z,就会在这两个节点之间来回移动,直到永远(或直到转发表发生改变)。 - 由于节点y计算了到x的一个新的最小开销,它在t1时使用新距离向量通知z。
- 在t1之后的某个时刻,z接收到y新的距离向量,指示y到x的最小开销是6。z知道它可以以1的开销到达y,因此计算出x的最小开销Dz(x) = min{50 + 0,1 + 6} = 7。由于z到x的最小开销增加了,它随后在t2时用新距离向量通知y。
- 以类似的方式,在接收z的新距离向量后,y确定Dy(x) = 8,并将其距离矢量发送给z。然后z确定Dz(x) = 9并向y发送它的距离向量,以此类推。
这个过程要持续多久?您应该确信,循环将持续44次迭代(y和z之间的消息交换)——直到z最终计算出其通过y的路径的开销大于50。此时,z将(最终!)确定它到x的最小开销路径是通过它与x的直接连接,然后y将通过z路由到x。坏消息的结果是链路开销的增加确实走得很慢!如果链路开销c(y, x)从4变成了10,000而开销c(z, x)是9999,会发生什么?由于这种情况,我们看到的问题有时被称为数到无穷大(count-to-infinity)的问题。
DV算法:添加毒性逆转
可以使用一种称为 毒性逆转(poisoned reverse) 的技术来避免刚才描述的特定循环场景。这个想法很简单,如果z通过y到达目标x,那么z将通告给y它到x的距离是无穷大,也就是说,z将通告给y Dz(x) = ∞(尽管z知道Dz(x) = 5),z将继续向y撒谎只要路线通过y去往x。因为y相信z没有路去往x, y永远不会尝试通过z路由到x,只要z继续通过y路由到x(谎言就是如此)。
现在让我们看看毒性逆转如何解决我们在图5.5(b)中遇到的特定循环问题。由于毒性逆转,y的距离表指示Dz(x) = ∞。当(x, y)链路的开销在t0时刻从4变为60时,y更新它的表,并继续直接路由到x,尽管开销更高,为60,并告知z它到x的新开销,即Dy(x) = 60。在t1接收到更新后,z立即通过直接链路(z, x)路由到x,开销为50。因为这是到x的一条新的最小开销路径,且这条路径不再经过y, z现在告诉y在t2时Dz(x) = 50。在收到z的更新后,y用Dy(x) = 51更新它的距离表。同样,由于z现在在y到x的最小开销路径上,y在t3时刻通知z Dy(x) = ∞!尽管y知道Dy(x) = 51。
LS和DV路由算法对比
DV和LS算法对计算路由采取互补的方法。在DV算法中,每个节点只与它的直接连接的邻居对话,但它向网络中所有(它知道的)节点提供自己的最小开销估算。LS算法需要全局信息。因此,当在每个路由器上实现时,例如,如图4.2和5.1所示,每个节点将需要与所有其他节点通信(通过广播),但它只告诉它们其直接连接链路的开销。让我们通过快速比较LS和DV算法的一些属性来结束我们对它们的研究。回想一下,N是节点(路由器)的集合,E是边(链路)的集合。
- 消息复杂度 我们已经看到LS要求每个节点知道网络中每个链路的开销。这就需要发送O(|N| |E|)条消息。此外,每当链路开销发生变化时,新的链路开销必须被发送到所有节点。DV算法要求在每次迭代时,直接连接的邻居之间进行消息交换。我们已经看到,算法收敛所需的时间取决于许多因素。当链路开销发生变化时,只有当新的链路开销导致连接该链路的一个节点的最小开销路径发生变化时,DV算法才会传播改变的链路开销的结果。
- 收敛速度 我们已经看到LS的实现是O(|N|2)算法,需要O(|N| |E|))消息。DV算法收敛速度慢,在收敛过程中会出现路由环路。DV还存在从数到无穷问题。
- 稳健性 如果路由器发生故障、行为不正常或被破坏,会发生什么?在LS下,路由器可以广播一个不正确的附加链路的开销(但不能广播其他链路)。节点还可能损坏或丢弃作为LS广播的一部分接收到的任何数据包。但是LS节点只计算自己的转发表;其他节点也在为自己执行类似的计算。这意味着路径计算在LS下是分开的,提供了一定程度的稳健性。在DV下,节点可以向任意或所有目的地通告错误的最小开销路径。(事实上,在1997年,一家小型ISP的故障路由器提供了错误的路由信息,导致其他路由器以流量淹没故障路由器,并导致大部分互联网断开连接长达几个小时[Neumann 1997]。)更一般地,我们注意到,在每次迭代中,DV中一个节点的计算被传递给它的邻居,然后在下一次迭代中间接传递给它邻居的邻居。因此,在DV条件下,一个错误的节点计算可以扩散到整个网络。
最后,两种算法都不是明显的赢家;事实上,这两种算法都在互联网上使用。
5.3 Internet中的AS内路由:OSPF
到目前为止,在我们对路由算法的研究中,我们把网络简单地看作是相互连接的路由器的集合。一个路由器和另一个路由器没有区别,因为所有路由器都执行相同的路由算法来计算整个网络的路由路径。在实践中,该模型及其对所有执行相同路由算法的同构路由器集的看法过于简单,主要有两个原因:
- 规模 随着路由器数量的增加,涉及到通信、计算和存储路由信息的开销变得难以承受。今天的互联网由数亿台路由器组成。在每个路由器上存储可能目的地的路由信息显然需要大量的内存。在所有路由器之间广播连接性(connectivity)和链路成本更新所需的开销将是巨大的!在如此多的路由器之间迭代的距离矢量算法肯定不会收敛。显然,必须采取一些措施来降低像互联网这样庞大的网络中路由计算的复杂性。
- 行政自治权 如第1.3节所述,Internet是一个ISP的网络,每个ISP都由自己的路由器网络组成。ISP通常希望按照自己喜欢的方式操作网络(例如,在网络内运行它选择的任何路由算法),或者从外部隐藏其网络内部组织的某些方面。理想情况下,组织应该能够按照自己的意愿操作和管理其网络,同时仍然能够将其网络连接到其他外部网络。
这两个问题都可以通过将路由器组织成 自治系统 (AS autonomous systems)来解决,每个自治系统由一组处于相同管理控制下的路由器组成。通常,ISP中的路由器以及连接它们的链路组成了一个独立的AS。然而,有些ISP将自己的网络划分为多个自治系统。特别是,有些一级ISP将自己的整个网络划分为一个巨大的自治系统,而有些ISP则将自己的ISP划分为几十个相互连接的自治系统。自治系统由其全球唯一自治系统号(ASN autonomous system number)来标识[RFC 1930]。AS号和IP地址一样,由ICANN区域注册机构(ICANN 2020)分配。
在同一个AS内(intra-AS)的路由器都运行相同的路由算法,并且都有彼此的信息。在自治系统中运行的路由算法称为 内部自治系统路由协议 (intra-autonomous system routing protocol)。
开放最短路径优先(OSPF)
OSPF(Open Shortest Path First)路由和它的近亲IS-IS路由被广泛应用于Internet上的AS内路由。OSPF的开放表明路由协议规范是公开可用的(例如,与思科的EIGRP协议相反,该协议在作为思科专有协议大约20年后,直到最近才开放[Savage 2015])。OSPF的最新版本是版本2,在一个公共文档[RFC 2328]中定义。
OSPF是一种利用链路状态信息洪流和Dijkstra最小开销路径算法的链路状态协议。在OSPF协议中,每台路由器都构建了整个自治系统的完整拓扑图(即一个图)。然后,每个路由器在本地运行Dijkstra最短路径算法,以自己为根节点,确定到所有子网的最短路径树。各个链路的开销由网络管理员配置(请参阅侧栏,原则和实践:设置OSPF的权重)。管理员可以选择将所有链路开销设置为1,从而实现最小跳数路由,也可以选择将链路权重设置为与链路容量成反比,以阻止流量使用低带宽链路。OSPF不强制规定如何设置链路权重(这是网络管理员的工作),而是提供了一种为给定的链路权重集确定最小开销路径路由的机制(协议)。
设置OSPF链路权重
我们对链路状态路由的讨论隐式地假设链路权重已设置,运行OSPF等路由算法,流量根据LS算法计算的路由表流动。根据因果关系,给出总开销最小的路由路径中的链路权重(即权重在前)和结果(通过Dijkstra算法)。在这种观点中,链路权重反映了使用链路的开销(例如,如果链路权重与容量成反比,那么使用高容量的链路将具有更小的权重,因此从路由的角度来看更有吸引力),而Dijsktra的算法用于最小化总体开销。
在实践中,链路权重和路由路径之间的因果关系可能是反向的,网络运营商通过配置链路权重来获得路由路径,以达到一定的流量工程目标[Fortz 2000, Fortz 2002]。例如,假设网络运营商对在每个入口点进入网络和去往每个出口点的流量有一个估算。然后,运营商可能希望设置出入流(ingress-to-egress flows)的特定路由,使所有网络链路的最大利用率最小化。但是对于OSPF这样的路由算法,运营商调整流经网络的路由的主要控制“把柄”是链路权重。因此,为了达到最小化最大链路利用率的目标,算子必须找到达到该目标的链路权重集。这是一种因果关系的反转——需要路由的流已知,必须找到OSPF链路的权重,以便OSPF路由算法产生所需的路由的流。
使用OSPF协议,一台路由器将路由信息广播给自治系统中的所有其他路由器,而不仅仅是它的邻居路由器。路由器在链路状态发生变化时(如开销变化或up/down状态变化)就会广播链路状态信息。它还定期广播链路状态(至少每30分钟一次),即使链路状态没有改变。RFC 2328注意到链路状态通告的周期性更新为链路状态算法增加了稳健性。OSPF的通告包含在OSPF消息中,直接由IP携带,其上层协议号为89。因此,OSPF协议本身必须实现可靠消息传输、链路状态广播等功能。OSPF协议还会检查链路是否正常运行(通过发送HELLO消息给连接的邻居),并允许OSPF路由器获取邻居的全网链路状态数据库。
OSPF所体现的一些进步包括以下几点:
- 安全 OSPF路由器之间的交换(如链路状态更新)可以进行认证。通过身份验证,只有受信任的路由器才能参与自治系统内的OSPF协议,从而防止恶意入侵者(或网络学生带着他们的新知识出去玩)将不正确的信息注入到路由器表中。默认情况下,路由器之间的OSPF数据包是未经认证的,可以伪造。两种类型的认证可以配置为simple和MD5(参见第8章关于MD5和认证的一般性讨论)。对于简单的身份验证,在每个路由器上配置相同的密码。路由器在发送OSPF数据包时,会以明文形式包含密码。显然,简单的身份验证不是很安全。MD5认证基于所有路由器上配置的共享密钥。对于发送的每一个OSPF数据包,路由器都会计算带有密钥的OSPF数据包内容的MD5哈希值。(参见第8章对消息验证码的讨论。)然后路由器将得到的哈希值包含在OSPF数据包中。接收数据包的路由器使用预先配置的密钥计算数据包的MD5哈希值,并与数据包携带的哈希值进行比较,从而验证数据包的真实性。序列号也与MD5验证一起使用,以防止重放攻击(replay attacks)。
- 多个相同开销路径 当到达目标地址的多条路径开销相同时,OSPF允许使用多条路径(即当存在多条相同开销路径时,不需要选择一条路径承载所有流量)。
- 综合支持单播和组播路由 MOSPF (Multicast OSPF) [RFC 1584]对OSPF进行了简单的扩展,提供了组播路由功能。MOSPF使用已有的OSPF链路数据库,在已有的OSPF链路状态广播机制的基础上增加了一种新的链路状态广播机制。
- 在单个AS中支持层次结构 OSPF自治系统可以分层配置为区域。每个区域运行自己的OSPF链路状态路由算法,区域内的每个路由器都会将自己的链路状态广播给该区域内的所有其他路由器。在每个区域内,一个或多个区域边界路由器负责路由区域外的数据包。最后,在自治系统中只配置一个OSPF区域为骨干区域。骨干区域的主要作用是路由AS内其他区域之间的流量。骨干路由器总是包含AS中的所有区域边界路由器,也可以包含非边界路由器。AS内部的区域间路由是指将数据包先路由到区域边界路由器(即区域内路由),然后通过骨干路由到目标区域的区域边界路由器,再路由到最终目标区域。
OSPF是一个相对复杂的协议,我们在这里的介绍必须是简单的;[Huitema 1998;Moy 1998;RFC 2328]提供额外的细节。
5.4 ISP间路由:BGP
我们刚刚了解到OSPF是AS内路由协议的一个例子。当数据包在同一AS内的源地址和目标地址之间进行路由时,数据包遵循的路由完全由AS内路由协议决定。然而,要在多个AS之间路由一个数据包,比如从Timbuktu的智能手机到硅谷数据中心的服务器,我们需要一个 AS间路由协议(inter-autonomous systemrouting protocol) 。由于AS间路由协议涉及到多个AS之间的协调,因此,在通信的AS间必须运行相同的AS间路由协议。事实上,在Internet上,所有的AS都运行着相同的跨AS路由协议,称为 边界网关协议(Border Gateway protocol) ,更通俗的叫法是 BGP [RFC 4271;Stewart 1999]。
BGP可以说是所有互联网协议中最重要的(唯一的竞争者是我们在4.3节中研究的IP协议),因为它是将互联网上成千上万的ISP粘合在一起的协议。我们很快就会看到,BGP是一种分散的异步协议,采用了第5.2.2节中描述的距离矢量路由。虽然BGP是一个复杂且具有挑战性的协议,但要深入了解互联网,我们需要熟悉它的基础和操作。我们花在学习BGP上的时间是非常值得的。
5.4.1 BGP扮演的角色
为了理解BGP的职责,可以考虑一个AS和该AS中的任意一台路由器。回想一下,每个路由器都有一个转发表,它在将到达的数据包转发到路由器出站链路的过程中起着核心作用。如我们所知,对于位于同一AS内的目的地,路由器转发表中的条目由AS的AS内路由协议决定。但是在AS之外的目的地呢?这正是BGP的作用。
在BGP协议中,数据包不会被路由到特定的目标地址,而是路由到CIDRized(Classless Inter-Domain Routing 无类域间路由的)前缀,每个前缀代表一个子网或子网的集合。在BGP世界中,目标地址可以采用138.16.68/22的形式,在本例中包括1024个IP地址。因此,路由器转发表中会有(x, I)形式的条目,其中x是前缀(如138.16.68/22),I是路由器某个接口的接口号。
BGP作为一种跨AS的路由协议,为每个路由器提供了一种实现以下目标的途径:
- 从邻居AS获取前缀可达性信息 特别地,BGP允许每个子网向Internet的其他子网通告自己的存在。一个子网在尖叫,"我存在,我就在这里",BGP确保互联网上所有的路由器都知道这个子网。如果没有BGP,每个子网将是一个孤立的孤岛,对互联网的其他部分来说是未知的和不可到达的。
- 确定到这些前缀的“最佳”路由 路由器可能得知到一个特定前缀的两个或更多不同路由。为了确定最佳路由,路由器会在本地运行BGP选路过程(使用从邻居路由器获得的前缀可达性信息)。根据策略和可达性信息确定最佳路径。
现在让我们深入探讨BGP是如何执行这两项任务的。
5.4.2 通告BGP路由信息
考虑图5.8中所示的网络。我们可以看到,这个简单的网络有三个自治系统:AS1、AS2和AS3。其中AS3包含一个前缀为x的子网。对于每个AS来说,每个路由器要么是 网关路由器 ,要么是 内部路由器 。网关路由器(gateway router)是位于AS边缘的路由器,它与其他AS中的一台或多台路由器直接相连。内部路由器(internal router)只与本AS内的主机或路由器相连。例如,在AS1中,路由器1c是网关路由器;路由器1a、1b、1d为内部路由器。
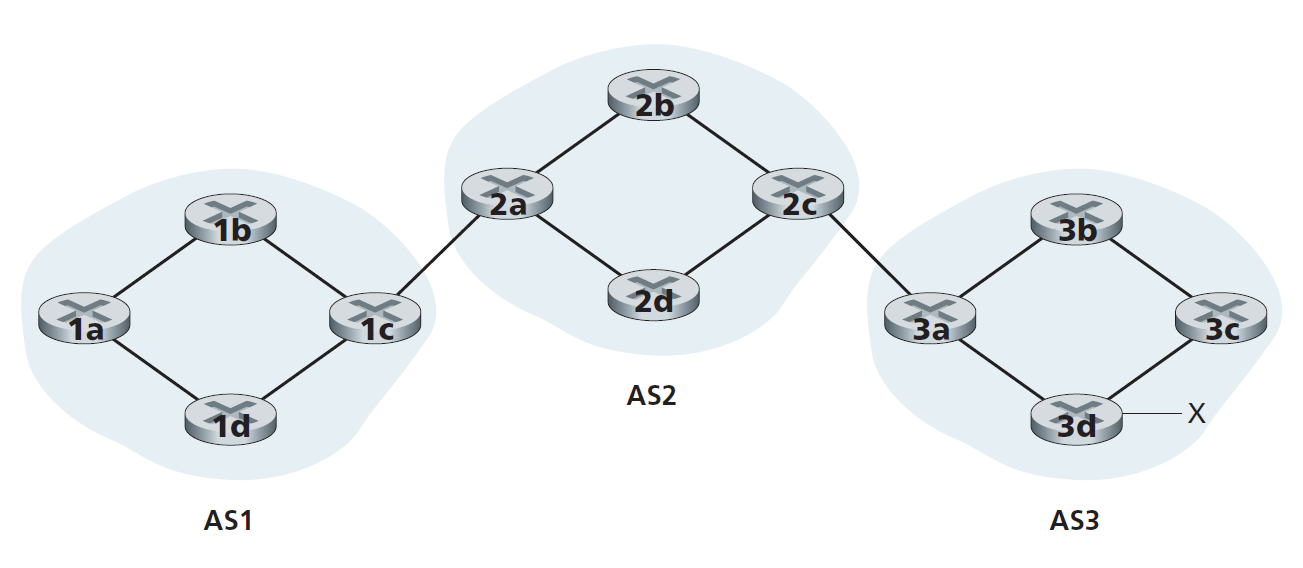
让我们考虑向图5.8所示的所有路由器通告(advertising)前缀x的可达性信息的任务。在高层次上,这是显而易见的。首先,AS3向AS2发送一个BGP消息,告知x存在并且在AS3中;让我们将此消息表示为“AS3 x”。然后AS2向AS1发送一条BGP消息,告诉AS1 x存在,并且可以先通过AS2,然后通过AS3到达x;让我们将该消息表示为'AS2 AS3 x'。通过这种方式,每个自治系统不仅会知道x的存在,还会知道自治系统通往x的路径。
虽然上一段关于通告BGP可达性信息的讨论应该能理解大致的意思,但它并不准确,因为自治系统实际上并不向彼此发送消息,而是由路由器发送消息。为了理解这一点,现在让我们重新检查图5.8中的示例。在BGP中,一对路由器使用端口179在半永久TCP连接上交换路由信息。每一个这样的TCP连接,以及通过该连接发送的所有BGP消息,被称为一个 BGP连接 。此外,跨两个AS的BGP连接称为 eBGP (external BGP)连接 ,同一AS内路由器之间的BGP会话称为 iBGP (internal BGP)连接 。BGP连接在图5.8中的应用示例如图5.9所示。通常每条链路有一条eBGP连接,直接连接不同AS中的网关路由器;因此,在图5.9中,网关路由器1c和2a之间存在一条eBGP连接,网关路由器2c和3a之间存在一条eBGP连接。
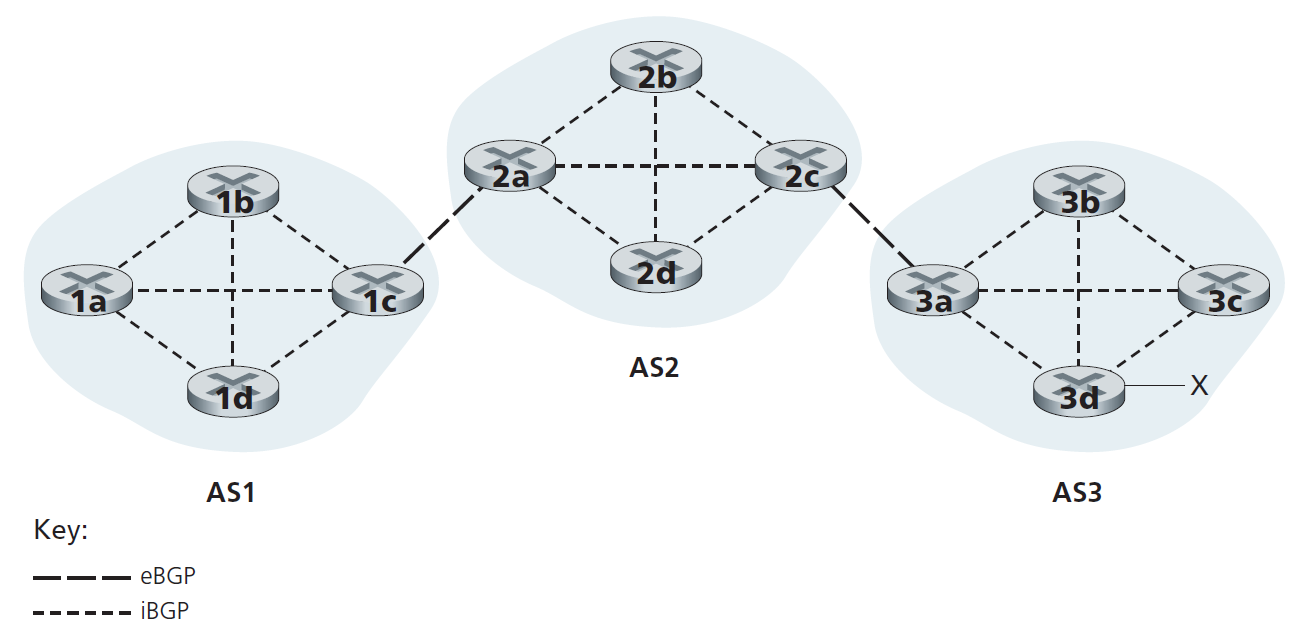
在每个AS内部的路由器之间也存在iBGP连接。图5.9展示了一个常见的配置,即为每个AS内部的每对路由器建立一个BGP连接,从而在每个AS内部建立一个网状的TCP连接。在图5.9中,eBGP连接用长破折号表示;iBGP连接用短破折号表示。注意iBGP连接并不总是与物理链路对应。
为了传播可达信息,使用了iBGP和eBGP两种会话。再次考虑将前缀x的可达性信息通告给AS1和AS2中的所有路由器。在此过程中,网关路由器3a首先向网关路由器2c发送一条eBGP消息"AS3 x"。然后,网关路由器2c向AS2内所有其他路由器(包括网关路由器2a)发送iBGP消息“AS3 x”。然后,网关路由器2a向网关路由器1c发送eBGP消息"AS2 AS3 x"。最后,网关路由器1c使用iBGP向AS1中的所有路由器发送消息“AS2 AS3 x”。这个过程完成后,AS1和AS2中的每个路由器都知道x的存在,也知道有一条到达x的AS路径。
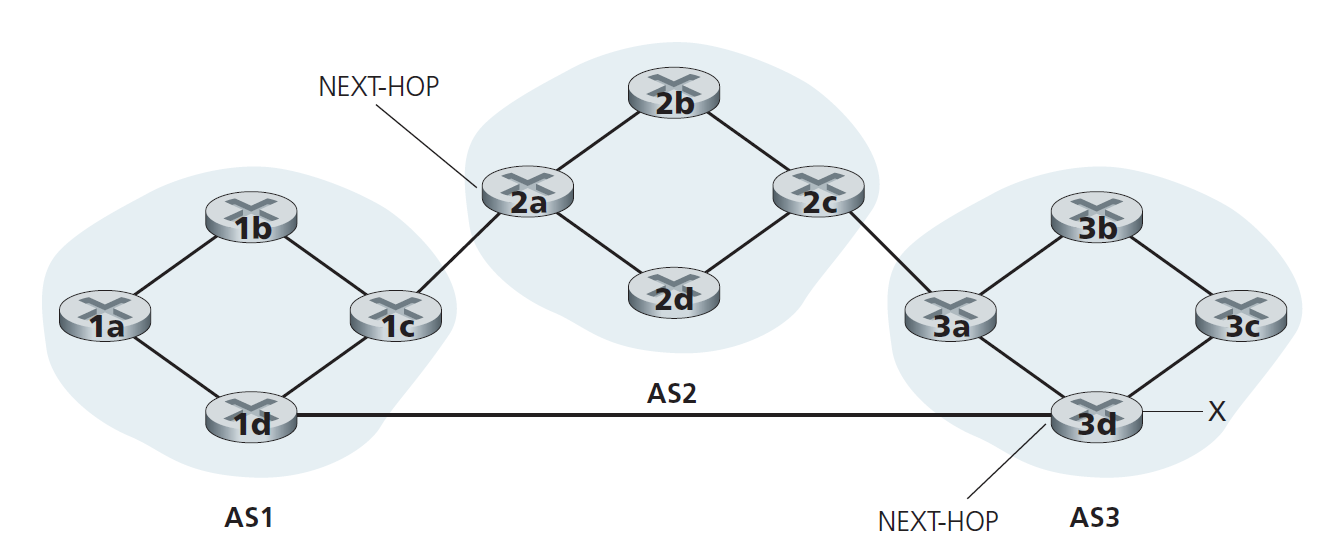
当然,在实际的网络中,从一个给定的路由器可能有许多不同的路径到给定的目的地,每通过一个不同AS的序列。例如,考虑网络在图5.10中,这是在图5.8中最初的网络,额外的物理链路和路由器1d、3d。在这种情况下,AS1到x有两条路径:通过路由器1c的“AS2 AS3 x”;和通过路由器1d的新路径“AS3 x"。
5.4.3确定最佳路由
正如我们刚刚了解到的,从一个给定的路由器到目标子网可能有许多路径。事实上,在互联网上,路由器经常收到几十种不同路径的可达性信息。路由器如何在这些路径中进行选择(然后相应地配置转发表)?
在解决这个关键问题之前,我们需要再介绍一点BGP术语。当路由器在BGP连接中通告一个前缀时,该前缀包含了多个 BGP属性(BGP attributes) 。在BGP术语中,前缀及其属性称为 路由(route) 。其中两个比较重要的属性是AS-PATH和NEXT-HOP。AS-PATH属性包含通告所经过的AS列表,正如我们在上面的例子中看到的。为了生成AS-PATH值,当一个前缀被传递给AS时,AS将自己的ASN添加到AS路径中现有的列表中。例如,在图5.10中,AS1到子网x有两条路由:一条使用AS-PATH ”AS2 AS3“;另一个使用AS-PATH "A3"。BGP路由器也使用AS-PATH属性来检测和防止循环通告;具体来说,如果路由器看到自己的AS包含在路径列表中,它就会拒绝这个通告。
NEXT-HOP属性提供了AS间和AS内路由协议之间的关键链路,它有一个微小但重要的用途。NEXT-HOP为从AS路径开始的路由器接口的IP地址。为了深入了解这个属性,让我们再次参考图5.10。如图5.10所示,AS1穿过AS2到x的路由“AS2 AS3 x”的下一跳属性为路由器2a左边接口的IP地址。当AS1到x的路由“AS3 x”绕过AS2时,其NEXT-HOP属性为路由器3d最左边接口的IP地址。总之,在这个简单的例子中,AS1中的每个路由器都知道两条到前缀x的BGP路由:
路由器2a最左边接口的IP地址;AS2 AS3; x
路由器3d最左边接口IP地址;AS3; x
在这里,每条BGP路由都被写成一个包含三个组成部分的列表:NEXT-HOP;AS-PATH;目的地前缀。在实践中,BGP路由会包含额外的属性,我们暂时不考虑这些属性。注意NEXT-HOP属性是不属于AS1的路由器的IP地址;但是,包含该IP地址的子网直接与AS1连接。
烫手山芋路由
我们现在终于可以精确地讨论BGP路由算法了。我们将从一个最简单的路由算法开始,即烫手山芋路由(hot potato routing)。
如图5.10所示,考虑网络中的路由器1b。如前所述,这台路由器将得到两种可能的到前缀x的BGP路由。在烫手山芋路由中,(从所有可能的路由中)选择的路由是到以该路由开始的NEXT-HOP路由器的开销最小的路由。在本例中,路由器1b会根据自己的AS内路由信息,找到到达NEXT-HOP路由器2a的开销最小的AS内路径,以及到达NEXT-HOP路由器3d的开销最小的AS内路径,然后选择开销最小的路径。例如,假设开销定义为穿越的链路数。那么路由器1b到路由器2a的最小开销为2,路由器1b到路由器3d的最小的开销是3,因此选择路由器2a。然后,路由器1b会查询自己的转发表(通过AS内算法配置),找到到达路由器2a的路径上开销最小的接口I。然后将(x, I)添加到转发表中。
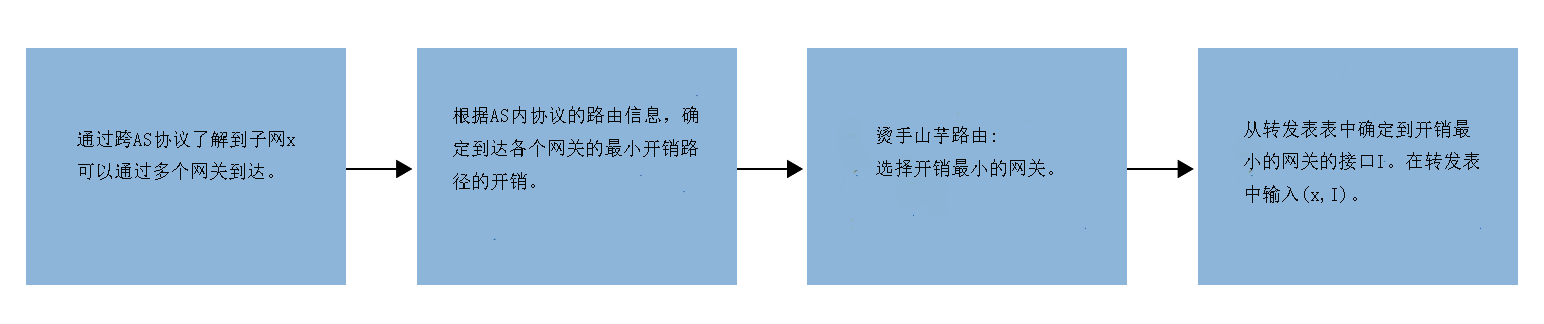
对于烫手山芋路由,在路由器转发表中添加AS外(outside-AS)前缀的操作步骤如图5.11所示。需要注意的是,在向转发表中添加AS外前缀时,需要同时使用AS间路由协议(BGP)和AS内路由协议(OSPF)。
烫手山芋路由的思想是让路由器1b以尽可能快的速度(更确切地说,以尽可能少的开销)将数据包从AS中取出,而不用担心从AS外到达目的地的剩余路径部分的开销。在hot potato routing这个名字中,一个数据包就类似于一个烫手山芋在你的手中燃烧。因为它很烫,你想尽快把它传递给另一个人(另一个AS)。因此,烫手山芋路由是一种自私算法——它试图减少自己AS内的开销,同时忽略其AS外的端到端开销。注意,对于烫手山芋路由,同一AS中的两台路由器可能会选择两条不同的AS路径到达同一个前缀。例如,我们刚刚看到路由器1b会通过AS2发送数据包到达x,而路由器1d会绕过AS2,直接向AS3发送数据包到达x。
路由选择算法
在实际应用中,BGP使用了一种比烫手山芋路由更复杂的算法,但同时又融合了烫手山芋路由。对于任何给定的目标前缀,BGP的选路算法输入的是路由器已经知晓并接受的到该前缀的所有路由的集合。如果只有一条这样的路由,那么BGP显然会选择这条路由。如果有两条或多条路由到达同一个前缀,则BGP会依次调用以下的消除规则,直到只剩下一条路由为止:
- 除了AS-PATH和NEXT-HOP属性外,路由还会被赋予一个 本地优先级(local preference) 值作为其属性。一条路由的本地优先级可以是路由器设置的,也可以是从同一AS内的其他路由器得到的。本地优先级属性的值是一种完全由AS网络管理员决定的策略。(我们将很快详细讨论BGP策略问题。)本地优先级最高的路由将被选中。
- 在剩余的路由中(都具有相同的本地优先级值),选择AS路径最短的路由。如果该规则是唯一的路由选择规则,那么BGP将使用DV算法来确定路径,其中距离向量使用AS的跳数而不是路由器的跳数。
- 对于其余路由(具有相同的本地最高优先级值和相同的AS路径长度),采用烫手山芋路由,即选择离NEXT-HOP路由器最近的路由。
- 如果仍然存在多条路由,路由器使用BGP标识符来选择路由[Stewart 1999]。
作为一个例子,让我们再次探讨图5.10中的路由器1b。回想一下,到前缀x的BGP路由只有两条,一条经过AS2,另一条绕过AS2。还记得,如果其使用烫手山芋路由,那么将通过AS2路由数据包到x前缀。但在上面的路线选择算法中,应用规则2之后,导致BGP选择绕过AS2的路线,因为该路由有更短的AS PATH。因此,我们看到,使用上述的路由选择算法,BGP不再是一个自私的算法——它首先寻找AS路径较短的路由(从而可能减少端到端延迟)。
如上所述,BGP是Internet内部AS间路由的事实标准。查看从一级ISP中提取的各种BGP路由表(大!)的内容,请参见http://www.routeviews.org。BGP路由表通常包含超过50万条路由(前缀和相应的属性)。关于BGP路由表的大小和特征的统计数据在[Huston 2019b]中有。
IP任播
BGP除了是Internet的AS间路由协议外,还经常用于实现IP任播(IP-anycast)服务[RFC 1546, RFC 7094],这是DNS中常用的路由协议。为了促进IP任播,考虑到在许多应用程序中,我们感兴趣的是(1)在许多分散在不同地理位置不同服务器上复制相同的内容,(2)让每个用户从最近的服务器访问内容。例如,CDN可以在不同国家的服务器上复制视频和其他对象。同样,DNS系统可以在全世界的DNS服务器上复制DNS记录。当用户希望访问这个复制的内容时,最好将用户指向拥有复制内容的最近的服务器。BGP的选路算法提供了一种简单而自然的选路机制。
为了使我们的讨论具体化,让我们描述一下CDN可能如何使用IP任播。如图5.12所示,在IP任播配置阶段,CDN公司为每个服务器分配相同的IP地址,并使用标准的BGP将该IP地址从每个服务器通告出去。当BGP路由器收到针对该IP地址的多条路由通告时,它会将这些通告视为到达同一物理位置的不同路径(实际上是到达不同物理位置的不同路径)。在配置路由表时,每台路由器都会在本地使用BGP选路算法来选择到达该IP地址的最佳路由(例如,根据AS跳数选择距离最近的路由)。例如,如果一个BGP路由(对应一个位置)离路由器只有一个AS跳,所有其他BGP路由(对应于其他位置)是两个或多个AS跳,那么BGP的路由器会选择一跳的位置路由数据包。在这个初始的BGP地址通告阶段之后,CDN就可以完成分发内容的主要工作了。当客户端请求视频时,CDN将地理上分散的服务器所使用的公共IP地址返回给客户端,无论客户端位于何处。当客户端向该IP地址发送请求时,Internet路由器根据BGP选路算法的定义,将请求数据包转发到距离“最近的”服务器。
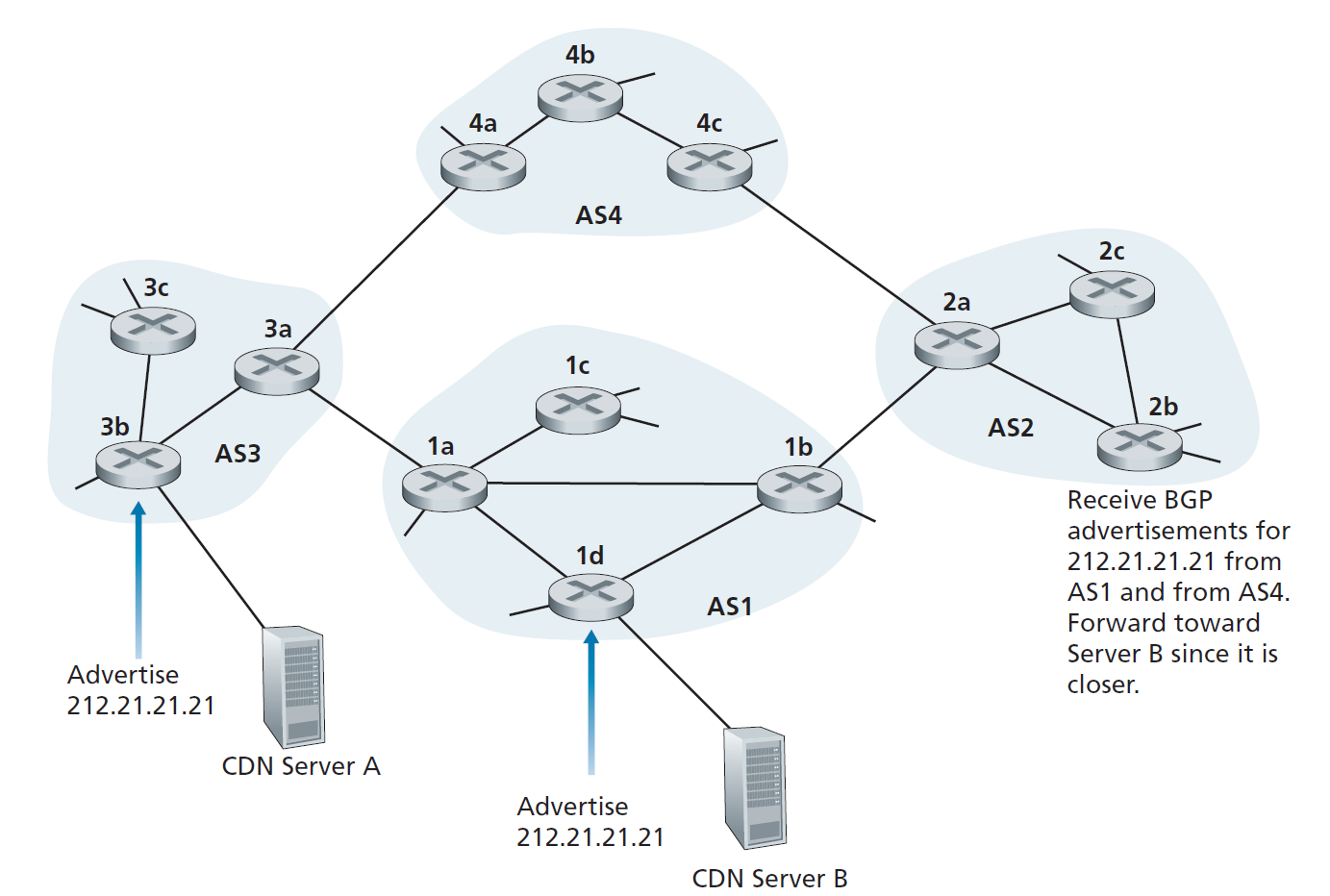
虽然上面的CDN示例很好地说明了如何使用IP任播,但在实践中,CDN通常不选择使用IP任播,因为BGP路由变化可能导致相同TCP连接的不同数据包到达Web服务器的不同实例。但是IP任播被DNS系统广泛地用于将DNS查询定向到最近的根DNS服务器。回顾2.4节,目前有13个根DNS服务器的IP地址。但与这些地址对应的是多个DNS根服务器,其中一些地址拥有100多个DNS根服务器,分布在世界各个角落。当一个DNS查询发送到这13个IP地址中的一个时,使用IP任播将查询路由到负责该地址的最近的DNS根服务器。[Li 2018]展示了最近的测量结果,说明了互联网任播、使用、性能和挑战。
5.4.5路由策略
当路由器选择到达目的地的路由时,AS路由策略可以优先于其他所有考虑因素,例如最短AS路径或烫手山芋路由。事实上,在路由选择算法中,路由首先根据local-preference属性进行选择,而local-preference属性的值由本地AS的策略确定。
下面我们通过一个简单的例子来说明BGP路由策略的一些基本概念。图5.13展示了6个相互连接的自治系统:A、B、C、W、X和Y。需要注意的是,A、B、C、W、X和Y是AS,而不是路由器。让我们假设自治系统W、X和Y是接入ISP, A、B和C是骨干供应商网络。我们还假设A、B和C直接相互发送流量,并向它们的客户网络提供完整的BGP信息。所有进入ISP接入网的流量必须以该网络为目的地,所有离开ISP接入网的流量必须来自该网络。W和Y显然是接入ISP。X是一个 多户接入ISP(multi-homed access ISP) ,因为它通过两个不同的提供者连接到网络的其他部分(这种情况在实践中越来越常见)。然而,像W和Y一样,X本身必须是所有离开/进入X的流量的源/目的地。但是,这种存根(stub)网络行为将如何实现和执行?如何阻止X转发B与C之间的流量?通过控制BGP路由的通告方式,可以很容易地实现这一点。特别地,如果X(向它的邻居B和C)通告它除了自己之外没有任何其他目的地的路径,它将充当一个接入ISP网络。也就是说,即使X知道一条路径,比如XCY,可以到达网络Y,它也不会把这条路径通告给B,因为B不知道X有一条到Y的路径,B不会通过X转发到Y(或C)的流量。这个简单的例子说明了如何使用选择性路由通告策略来实现客户/提供商的路由关系。
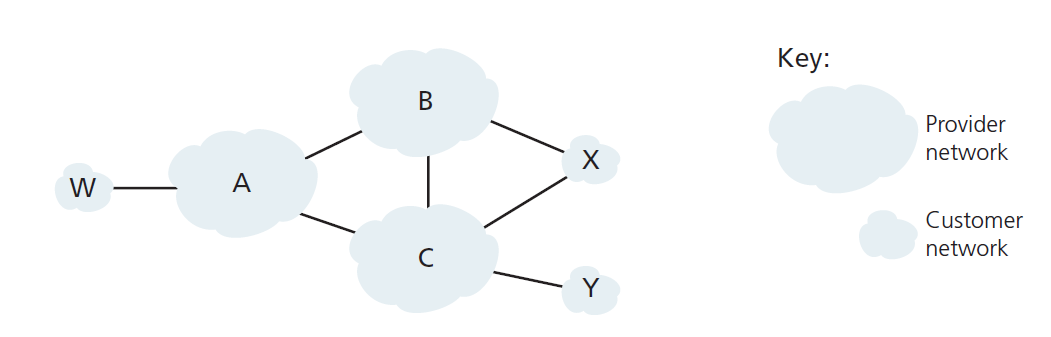
接下来,让我们关注提供商网络,例如AS B。假设B从A那里知道A有一条到W的路径AW, B就可以将该路由AW安装到它的路由信息库中。显然,B也想把路径BAW通告给它的客户X,这样X就知道它可以通过B路由到W,但是B应该把路径BAW宣传给C吗?如果它这样做了,那么C可以通过BAW将流量路由到W。如果A、B和C都是骨干供应商,B可能理所当然地认为它不应该承担A与C间的的流量中转(或开销), B认为那是A或C的工作。目前没有官方标准控制骨干ISP之间的路由。然而,商业ISP遵循的一条经验法则是,任何流经ISP骨干网的流量必须在该ISP的客户所在的网络中有一个源或一个目的地(或两者都有);否则,网络流量将免费搭乘ISP的网络。个人对等协议(用于解决上述问题)通常是在一对对ISP之间协商达成的,通常是保密的。[Huston 1999a;Huston 2012]对对等协议进行了有趣的讨论。有关路由策略如何反映ISP之间商业关系的详细描述,请参阅[Gao 2001;Dmitiropoulos 2007]。从ISP的角度讨论BGP路由策略,请参见[Caesar 2005b]。
为什么会有不同的AS间路由和AS内路由协议?
现在研究了部署在当今互联网的inter-AS和intra-AS路由协议的具体细节,让我们最后考虑最基本的问题:为什么使用不同的AS间和AS内路由协议?
这个问题的答案涉及到AS内和AS间路由目标差异的核心:
- 政策 在AS间,政策(policy)问题占主导地位。来自给定AS的流量不能通过另一个特定AS,这一点可能很重要。类似地,一个给定的AS可能想要控制它携带(carries)其他AS之间的过境流量。我们已经看到,BGP携带路径属性,并提供路由信息的受控分发,这样就可以做出基于政策的路由决策。在AS内,所有事物名义上都处于相同的管理控制之下,因此在AS内选择路由时,政策问题的重要性要小得多。
- Scale 路由算法及其数据结构的规模(scale)是跨AS路由的一个关键问题。在AS中,可伸缩性(scalability)不太重要。首先,如果一个ISP变得太大,总有可能把它分成两个AS,并在两个新的AS之间进行跨AS路由(回想一下,OSPF通过将一个AS划分为区域来建立这样的层次结构)。
- 性能 由于跨AS路由是基于政策的,因此所使用路由的质量(例如,性能)通常是次要考虑的问题(也就是说,满足某些策略标准的较长或较昂贵的路由很可能比较短但不满足该标准的路由更受重视)。事实上,我们看到在AS中,甚至没有开销的概念(除了AS跳数)与路由相关。然而,在单个AS中,这样的政策问题就不那么重要了,它允许路由更多地关注在路由上实现的性能水平。
至此,我们完成了对BGP的简要介绍。了解BGP非常重要,因为它在互联网中扮演着核心角色。我们鼓励你去看参考文献[Stewart 1999; Huston 2019a; Labovitz 1997; Halabi 2000; Huitema 1998; Gao 2001; Feamster 2004; Caesar 2005b; Li 2007]了解更多有关BGP的知识。
5.4.6 Putting the Pieces Together: Obtaining Internet Presence
虽然本小节不是关于BGP本身,但它汇集了我们迄今为止看到的许多协议和概念,包括IP地址、DNS和BGP。
假设您刚刚创建了一家小型公司,该公司拥有许多服务器,包括描述公司产品和服务的公共Web服务器、员工用于获取电子邮件消息的邮件服务器和DNS服务器。当然,您希望整个世界都能够访问您的网站,以便了解您令人兴奋的产品和服务。此外,您希望您的员工能够向世界各地的潜在客户发送和接收电子邮件。
要实现这些目标,首先需要获得Internet连接,这是通过与本地ISP签合同和连接来实现的。您的公司将有一个网关路由器,它将连接到您本地ISP的路由器。这种连接可以是DSL连接,通过现有的电话基础设施,到ISP路由器的租用线路,或在第一章中描述的许多其他接入解决方案之一。您的本地ISP也会为您提供一个IP地址范围,例如,一个由256个地址组成的/24地址范围。一旦你有你的物理连接和IP地址范围,你会分配一个IP地址(在你的地址范围)到您的Web服务器,一个到你的邮件服务器,一个到DNS服务器,一个到网关路由器,还有公司的其他网络服务器和网络设备等。
除了与ISP签订合同外,你还需要与互联网注册商签订合同,为你的公司获得一个域名,如第二章所述。例如,如果您的公司的名称是,例如,Xanadu Inc.,您自然会试图获得域名xanadu.com。您的公司还必须在DNS系统中存在。具体来说,因为外界会想要联系您的DNS服务器以获取您的服务器的IP地址,您还需要向您的注册商提供您的DNS服务器的IP地址。然后,你的注册商将在.com顶级域名服务器中输入你的DNS服务器(域名和相应的IP地址),如第二章所述。完成这一步后,任何知道您的域名(例如xanadu.com)的用户都可以通过DNS系统获得您的DNS服务器的IP地址。
为了让人们能够发现Web服务器的IP地址,您需要在DNS服务器中包含将Web服务器的主机名(例如www.xanadu.com)映射到其IP地址的条目。您将希望在公司的其他公开可用服务器(包括邮件服务器)上拥有类似的条目。通过这种方式,如果Alice想要浏览您的Web服务器,DNS系统将联系您的DNS服务器,找到您的Web服务器的IP地址,并将其交给Alice。然后,Alice可以直接与您的Web服务器建立TCP连接。
然而,还有另外一个必要且关键的步骤,以允许来自世界各地的人访问您的Web服务器。考虑一下,当知道Web服务器IP地址的Alice向该IP地址发送IP数据报(例如,TCP SYN段)时会发生什么。该数据报将通过Internet进行路由,访问许多不同应用服务器中的一系列路由器,最终到达您的Web服务器。当任何一台路由器收到数据报时,它会在转发表中查找一个条目,以确定它应该在哪个出口端口转发数据报。因此,每个路由器需要知道您公司的/24前缀(或某些聚合条目)的存在。路由器如何知道您公司的前缀?正如我们刚刚看到的,它从BGP中意识到了这一点!具体来说,当你的公司与本地ISP签订合同并得到一个前缀(即地址范围)时,你的本地ISP将使用BGP将你的前缀通告给它连接的ISP。然后,这些ISP又会使用BGP来传播通告。最终,所有的Internet路由器将知道您的前缀(或包含前缀的某些聚合),从而能够适当地转发发送到您的Web和邮件服务器的数据报。
5.5 SDN控制平面
在本节中,我们将深入探讨SDN控制平面——控制网络中启用SDN的设备之间的数据包转发的全网逻辑,以及这些设备及其服务的配置和管理。我们在这里的研究建立在4.4节中对广义SDN转发的讨论之上,所以在继续之前,你可能想要首先回顾这一节,以及本章的5.1节。在4.4节中,我们将再次采取SDN文献中使用的术语,指的是网络的转发设备数据包交换机(或交换机,加上“数据包”是为了方便理解),因为转发决策可以由网络层源/目标地址,链路层源/目标地址,以及传输层、网络层和链路层数据包头字段中的许多其他值决定。
可以确定SDN架构的四个关键特征[Kreutz 2015]:
- 基于流的转发 由SDN控制的交换机转发的数据包可以基于传输层、网络层或链路层头中的任意数量的头字段值。我们在4.4节中看到,OpenFlow1.0抽象允许基于11个不同的头字段值转发。这与我们在第5.2—5.4节中研究的基于路由器的传统转发方法形成了鲜明的对比,在该方法中,IP数据报的转发完全基于数据报的目标IP地址。回顾图5.2,数据包转发规则是在交换机的流表中指定的;SDN控制平面的工作是计算、管理和安装所有网络交换机中的流表条目。
- 数据平面与控制平面分离 图5.2和5.14清楚地显示了这种分离。数据平面由相对简单(但快速)的网络交换机组成,这些交换机在它们的流表中执行匹配加操作规则。控制平面由确定和管理交换机流表的服务器和软件组成。
- 网络控制功能:数据平面交换机的外部 SDN中的“S"是用于软件的,SDN控制平面在软件中实现也许并不奇怪。然而,与传统路由器不同的是,该软件运行在与网络交换机不同且距离较远的服务器上。如图5.14所示,控制平面本身由SDN控制器(或网络操作系统[Gude 2008])和一组网络控制应用程序组成。控制器维护精确的网络状态信息(例如,远程链路、交换机和主机的状态);向在控制平面中运行的网络控制应用程序提供此信息;并提供了这些应用程序可以监控、编程和控制底层网络设备的方法。虽然图5.14中的控制器显示为一个单独的中央服务器,但实际上控制器只是逻辑上集中的;它通常在多个服务器上实现,这些服务器提供协调的、可伸缩的性能和高可用性。
- 一个可编程网络 网络可以通过运行在控制平面上的网络控制应用程序进行编程。这些应用程序是SDN控制平面的大脑,通过SDN控制器提供的API来指定和控制网络设备中的数据平面。例如,一个路由网络控制应用程序可能决定源和目的地之间的端到端路径(例如,通过使用SDN控制器维护的节点状态和链路状态信息执行Dijkstra的算法)。另一个网络应用程序可能执行访问控制,也就是说,决定哪些数据包将在交换机上被阻塞,如4.4.3节中的第三个示例所示。另一个应用程序可能会以执行服务器负载均衡的方式(我们在第4.4.3节中考虑的第二个例子)来转发数据包。
从这个讨论中,我们可以看到SDN代表了一个重要的分解网络功能——数据平面交换机,SDN控制器和网络控制应用程序是独立的实体,每个可能由不同的供应商和组织提供。这与SDN之前的模式形成了对比,在SDN之前的模式中,交换机/路由器(连同其嵌入式控制平面软件和协议实现)是单片的,垂直集成的,由单个供应商销售。SDN网络功能的这种分离被比作早期从大型计算机(其中硬件、系统软件和应用程序由单一供应商提供)到个人计算机(具有独立的硬件、操作系统和应用程序)的进化。计算硬件、系统软件和应用程序的分离导致了一个丰富的、开放的生态系统,这三个领域的创新驱动了这个生态系统;SDN的一个希望是,它将继续推动和使这种丰富的创新成为可能。
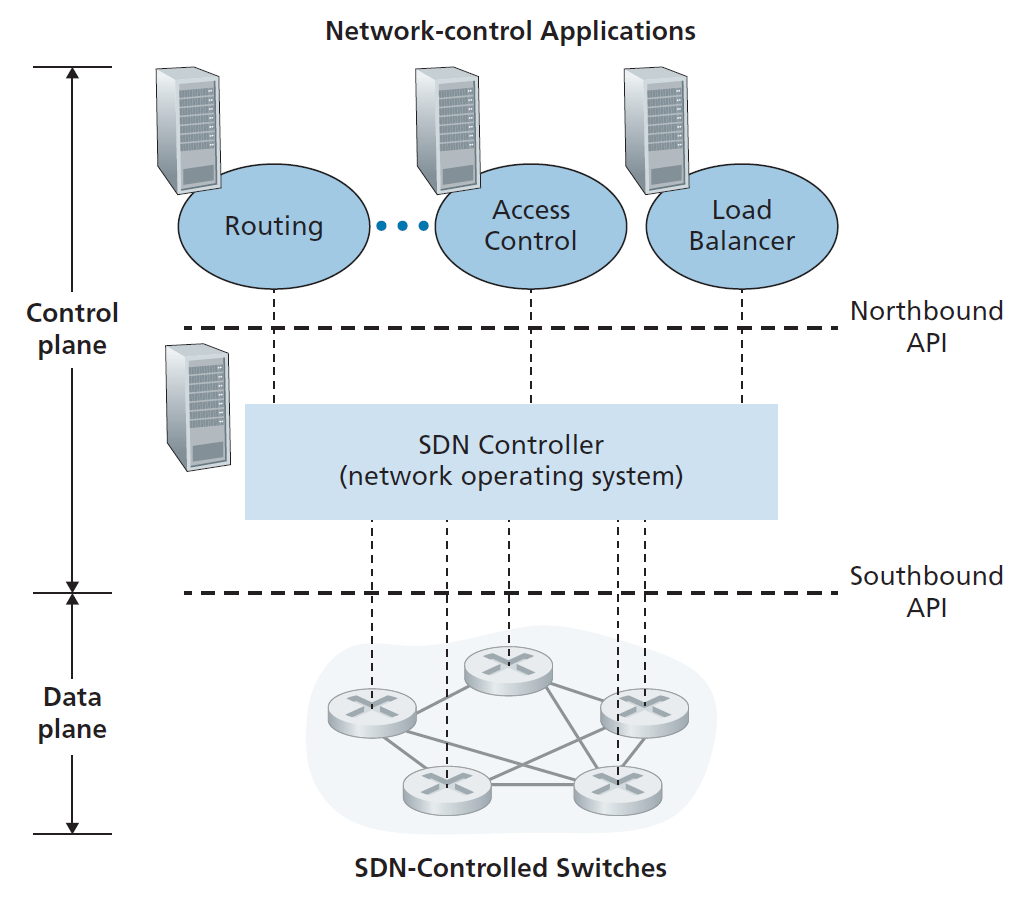
鉴于我们对图5.14的SDN架构的理解,许多问题自然会出现。流表实际是如何计算的,在哪里计算的?如何根据SDN控制设备的事件更新这些表(例如,附加的链路上升/下降)?如何协调多个交换机的流表条目,从而产生协调一致的全网功能(例如,从源到目的地转发数据包的端到端路径,或协调的分布式防火墙)?SDN控制平面的作用是提供这些功能,以及许多其他功能。
5.5.1 SDN控制平面:SDN控制器和SDN网控应用
通过考虑控制平面必须提供的通用功能,让我们从抽象的角度开始讨论SDN控制平面。正如我们将看到的,这种抽象的第一原则方法将引导我们形成一个反映SDN控制平面如何在实践中实现的总体架构。
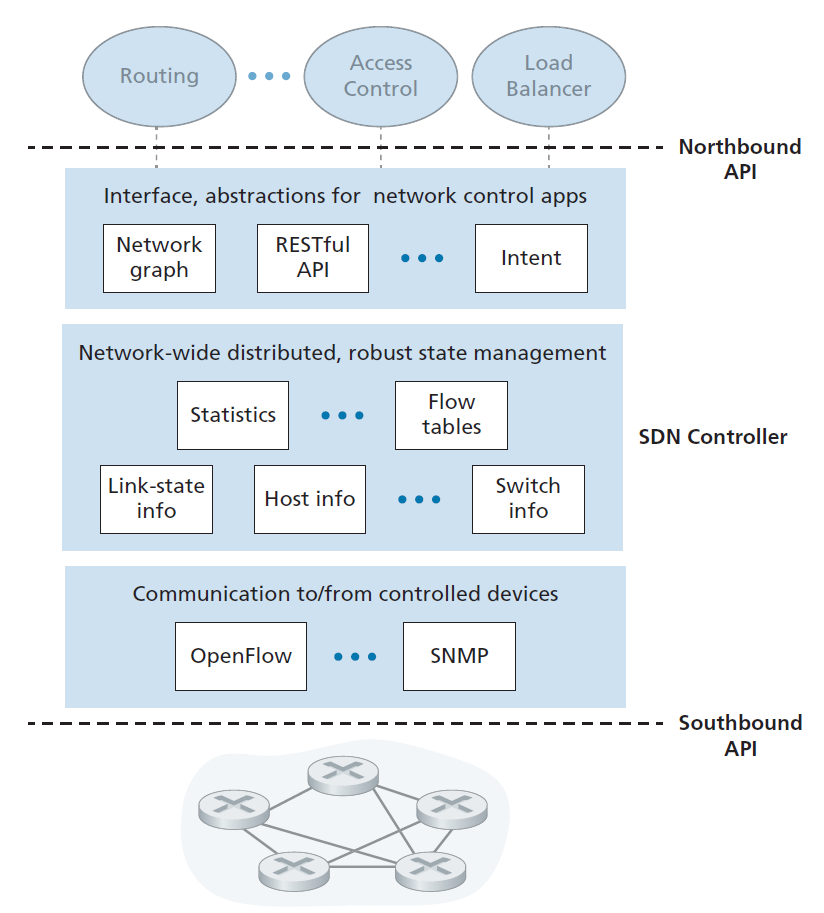
如上所述,SDN控制平面大致分为两个部分:SDN控制器和SDN网络控制应用程序。让我们先看看控制器。从最早的SDN控制器[Gude 2008]开始,已经开发了许多SDN控制器;参见[Kreutz 2015]的一份极为详尽的调查。图5.15提供了一个通用SDN控制器的更详细的视图。控制器的功能可以大致分为三层。让我们以一种不同寻常的自下而上的方式来探讨这些层:
- 通信层:SDN控制器与被控网络设备之间的通信 显然,如果SDN控制器要控制远端启用SDN的交换机、主机或其他设备的操作,就需要一个协议来在控制器和该设备之间传输信息。此外,设备必须能够将本地观察到的事件与控制器进行通信(例如,指示连接的链路已连接或断开的消息、设备刚刚加入网络的消息,或指示设备已连接并运行的心跳)。这些事件为SDN控制器提供了网络状态的最新视图。该协议构成控制器架构的最底层,如图5.15所示。控制器和被控制设备之间的通信通过所谓的控制器的南向"southbound”接口进行。在第5.5.2节中,我们将研究OpenFlow,它是一个提供这种通信功能的特定协议。OpenFlow在大多数(如果不是全部的话)SDN控制器中实现。
- 网络范围的状态管理层 终极控制决策由SDN控制平面——例如,配置流表中所有交换机来实现所需的底端转发,实现负载均衡,或者实现一个特定的防火墙功能——将要求控制器拥有关于网络主机、链路、交换机和其他SDN控制设备状态的最新信息。交换机的流表包含计数器,其值也可用于网络控制应用程序;因此,这些值应该对应用程序可用。由于控制平面的最终目的是确定各种控制设备的流表,控制器也可能维护这些表的副本。这些信息都构成了SDN控制器维护的全网状态的例子。
- 连接网络控制应用层的接口 控制器通过北向"northbound"接口与网络控制应用程序交互。这个API允许网络控制应用程序在状态管理层中读/写网络状态和流表。应用程序可以注册以便在状态变化事件发生时得到通知,以便对SDN控制的设备发送的网络事件通知采取响应措施。可能会提供不同类型的API;我们将看到两个流行的SDN控制器使用REST [Fielding 2000]请求-响应接口与它们的应用程序通信。
我们已经多次注意到,SDN控制器可以被认为是逻辑上中心化的(logically centralized),也就是说,控制器可以从外部(例如,从SDN控制的设备和外部网络控制应用程序的角度)看作一个单一的、单片的服务。但是,这些服务和用于保存状态信息的数据库实际上是由一组分布式服务器实现的,以实现容错、高可用性或性能方面的原因。随着控制器功能由一组服务器实现,必须考虑控制器内部操作的语义(例如,维护事件的逻辑时间顺序、一致性、共识等)[Panda 2013]。这样的关注点在许多不同的分布式系统中是常见的;请参阅[Lamport 1989, Lampson 1996]以获得应对这些挑战的优雅解决方案。现代控制器,如Open- Daylight [OpenDaylight 2020]和ONOS [ONOS 2020],已经相当重视构建逻辑上中心化但物理上分布式的控制器平台,为受控设备和网络控制应用程序提供可伸缩的服务和高可用性。
图5.15中描述的架构非常类似于2008年[Gude 2008]最初提议的NOX控制器的架构,以及今天的OpenDaylight [OpenDaylight 2020]和ONOS [ONOS 2020] SDN控制器的架构(参见侧栏)。我们将在第5.5.3节中介绍一个控制器操作的示例。然而,首先让我们来看看OpenFlow协议,它是最早的,也是目前可以用于SDN控制器和受控设备之间通信的几种协议之一,它位于控制器的通信层。
5.5.2 OpenFlow协议
OpenFlow协议[OpenFlow 2009, ONF 2020]在SDN控制器和SDN控制的交换机或其他实现OpenFlow API的设备之间运行,我们之前在4.4节中研究过。OpenFlow协议在TCP上运行,默认端口号为6653。
在从控制器流向被控制交换机的重要消息中,有以下几种:
- 配置 该消息允许控制器查询和设置交换机的配置参数。
- 修改状态 该消息用于添加/删除或修改交换机流表中的条目,以及设置交换机端口属性。
- 读取状态 该消息被控制器用来从交换机的流表和端口收集统计信息和计数器值。
- 发送数据包 该消息被控制器用来从被控制交换机的指定端口发送特定的数据包。消息本身在其有效负载中包含要发送的数据包。
以下是从SDN控制的交换机流向控制器的消息:
- Flow-Removed 该消息通知控制器流表条目已被删除,例如由于超时或接收到modify-state消息。
- Port-status 该消息被交换机用来通知控制器端口状态的变化。
- Packet-in 回想4.4节,一个到达交换机端口且不匹配任何流表条目的数据包被发送给控制器进行额外的处理。匹配的数据包也可以发送给控制器,作为对匹配的操作。packet-in消息用于将这些数据包发送给控制器。
更多的OpenFlow消息在[OpenFlow 2009, ONF 2020]中定义。
谷歌的软件定义全球网络
回想一下2.6节中的案例研究,谷歌部署了一个专用的广域网(WAN),它将其数据中心和服务器集群(在IXP和ISP中)互连起来。这个名为B4的网络拥有一个谷歌设计的基于OpenFlow的SDN控制平面。谷歌的网络能够在长期运行中以接近70%的利用率驱动WAN链路(比典型的链路利用率增加2到3倍),并根据应用程序优先级和现有的流需求在多条路径上分割应用程序流[Jain 2013]。
谷歌B4网络特别适合于SDN网络:(i)谷歌控制从IXP和ISP的边缘服务器到网络核心路由器的所有设备;(ii)带宽最密集的应用程序是在资源拥塞时在站点之间进行大规模的数据复制,以便在资源拥塞时将数据复制到高优先级的交互应用程序;(iii)只有几十个数据中心连接,集中控制是可行的。
谷歌的B4网络使用自定义构建的交换机,每个交换机都实现了OpenFlow的一个稍微扩展的版本,带有一个本地开放流代理(OFA,Open Flow Agent),在灵魂上与我们在图5.2中遇到的控制代理类似。每个OFA依次连接到网络控制服务器(NCS,network control server)中的一个开放流控制器(OFC,Open Flow Controller),使用一个独立的带外(out of band)网络,不同于数据中心之间传输数据的网络。因此,OFC为网络控制中心提供了与其控制交换机进行通信的服务,在灵魂上类似于图5.15所示的SDN架构的最低层。在B4中,OFC还执行状态管理功能,将节点和链路状态保存在网络信息库(Network Information Base, NIB)中。谷歌的OFC实现基于ONIX SDN控制器[Koponen 2010]。BGP(数据中心间路由协议)和IS-IS (OSPF(数据中心内路由协议)的近亲。Paxos [Chandra 2007]用于执行NCS组件的热副本,以防止故障。
流量工程网络控制应用程序在逻辑上位于网络控制服务器集之上,它与这些服务器交互,为应用程序流组提供全局的、全网范围的带宽供应。通过B4, SDN向全球网络提供商的运营网络迈出了重要的一步。[Jain 2013;Hong 2018]以获取B4的详细描述。
5.5.3数据平面与控制平面交互:一个案例
为了巩固我们对SDN控制的交换机和SDN控制器之间交互的理解,让我们探讨如图5.16所示的例子,其中Dijkstra算法(我们在5.2节中研究过)用于确定最短路径路由。图5.16中的SDN场景与第5.2.1节和5.3节之前的每个路由器控制场景有两个重要的区别,其中Dijkstra算法在每个路由器中实现,链路状态更新在所有网络路由器中扩散:
- Dijkstra算法作为一个独立的应用程序在数据包交换机之外执行。
- 数据包交换机向SDN控制器发送链路更新,而不是互相发送。
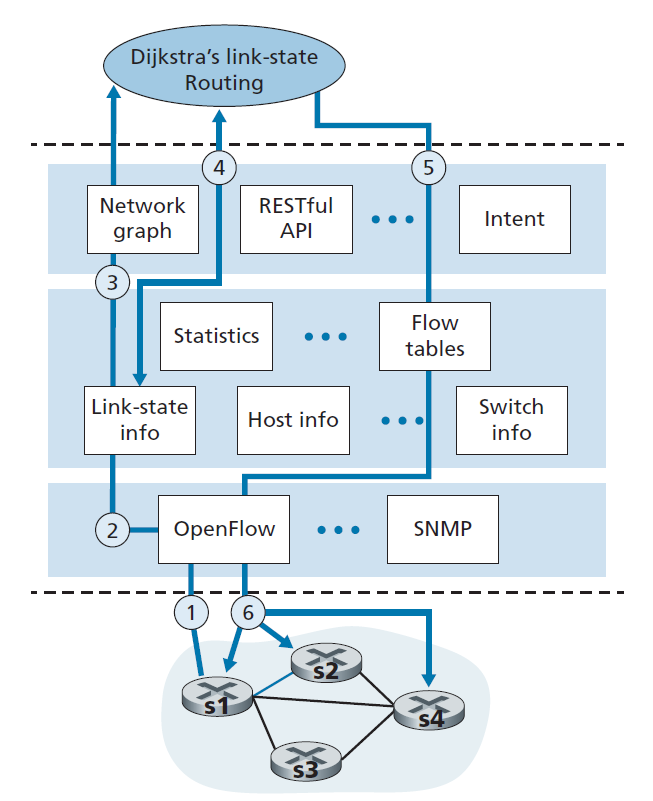
在这个例子中,我们假设交换机s1和s2之间的链路故障(goes down);由于实现了最短路径路由,从而影响s1、s3和s4的流入和流出流转发规则,但是s2的运算是不变的。我们还假设OpenFlow被用作通信层协议,并且控制平面除了链路状态路由之外不执行其他功能。
- 交换机s1和交换机s2之间的链路发生故障,交换机s1通过OpenFlow port-status消息通知SDN控制器链路状态发生变化。
- SDN控制器接收到表示链路状态变化的OpenFlow消息,并通知链路状态管理器,后者更新链路状态数据库。
- 实现Dijkstra链路状态路由的网络控制应用程序以前已经注册,以便在链路状态变化时收到通知。该应用程序接收到链路状态更改的通知。
- 链路状态路由应用程序与链路状态管理器交互以获得更新的链路状态;它也可以咨询状态管理层中的其他组件。然后计算新的最小开销路径。
- 然后,链路状态路由应用程序与流表管理器交互,后者确定要更新的流表。
- 然后,流表管理器使用OpenFlow协议更新受影响交换机上的流表条目——S1(将通过s4路由到s2的数据包),s2(将开始通过中间交换机s4接收来自S1的数据包),以及s4(必须从S1转发到s2的数据包)。
这个示例很简单,但说明了SDN控制平面如何提供控制平面服务(在本例中是网络层路由),这些服务以前是通过在每个网络路由器中执行的逐-路由器控制来实现的。人们现在可以很容易地理解支持SDN的ISP是如何轻松地从开销最低的路径路由切换到更手动定制(hand-tailored)的路由方法的。事实上,由于控制器可以根据自己的意愿调整流表,它可以通过简单地改变应用控制软件来实现任何形式的转发。这种易于更改的情况应该与传统的每个路由器控制平面的情况相比较,在这种情况下,所有路由器(可能由多个独立供应商提供给ISP)中的软件都必须更改。
5.5.4 SDN:过去与未来
虽然对SDN的浓厚兴趣是一个相对较新的现象,但SDN的技术根源,尤其是数据和控制平面的分离,可以追溯到相当远的过去。2004年,[Feamster 2004, Lakshman 2004, RFC 3746]都主张将网络的数据平面和控制平面分离。[van der Merwe 1998]描述了一个带有多个控制器的ATM网络控制框架[Black 1995],每个控制器控制多个ATM交换机。Ethane项目[Casado 2007]率先提出了简单的基于流的以太网交换机网络的概念。match-plus-action流表,一个集中的控制器,管理流的接纳和路由,以及不匹配的数据包从交换机转发到控制器。2007年,一个由300多个Ethane交换机组成的网络开始运行。Ethane很快演变成了OpenFlow项目,其他的(正如俗话所说)都成为了历史。
大量的研究工作旨在开发未来的SDN架构和功能。正如我们所看到的,SDN革命正在导致专用单片交换机和路由器(数据和控制平面)被简单的商用交换硬件和复杂的软件控制平面颠覆性地取代。SDN的概括称为网络功能虚拟化(NFV,network functions virtualization)(我们在前面的4.5节中讨论过),其目的类似于用简单的商品服务器、交换和存储颠覆性地取代复杂的代理(例如带有专用硬件和用于媒体缓存/服务的专有软件的代理)。第二个重要研究领域试图将SDN概念从AS内设置扩展到AS间设置[Gupta 2014]。
SDN控制器案例研究:OpenDayLight和ONOS控制器
在SDN的早期,有一个单一的SDN协议(OpenFlow [McKeown 2008;OpenFlow 2009])和单个SDN控制器(NOX [Gude 2008])。自那时起,SDN控制器的数量显著增长[Kreutz 2015]。一些SDN控制器是公司特定的和专有的,特别是用于控制内部专有网络(例如,在公司的数据中心内部或之间)。但更多的控制器是开源的,并以各种编程语言实现[Erickson 2013]。最近,OpenDaylight控制器[OpenDaylight 2020]和ONOS控制器[ONOS 2020]已经找到了相当大的行业支持。它们都是开源的,并且正在与Linux基金会合作开发。
OpenDaylight控制器
图5.17展示了OpenDaylight (ODL)控制器平台[OpenDaylight 2020, Eckel 2017]的简化视图。
ODL的基本网络功能位于控制器的核心,与图5.15中遇到的全网状态管理功能密切相关。服务抽象层(SAL,Service Abstraction Layer)是控制器的神经中枢,允许控制器组件和应用程序调用彼此的服务、访问配置和操作数据,并订阅它们生成的事件。SAL还为ODL控制器和受控设备之间操作的特定协议提供了统一的抽象接口。这些协议包括OpenFlow(我们在4.5节中介绍过),和简单网络管理协议(SNMP)和网络配置协议(NETCONF),这两个我们将在第5.7节介绍。OVSDB (Open vSwitch Database Management Protocol)用于管理数据中心交换,这是SDN技术的一个重要应用领域。我们将在第6章中介绍数据中心网络。
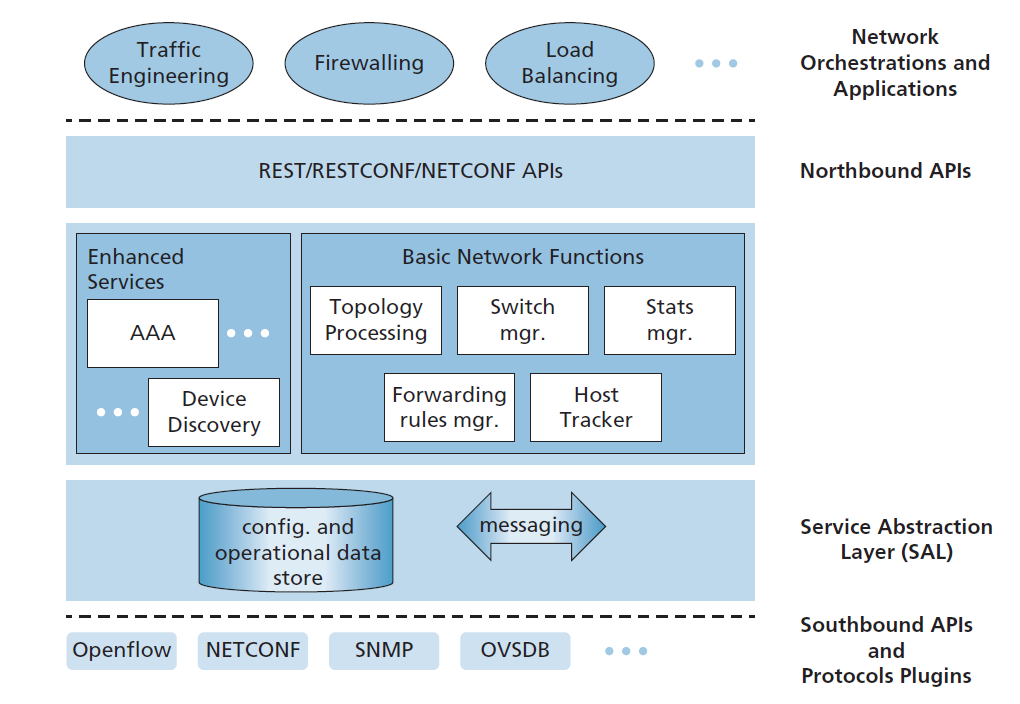
网络编制(Orchestrations)和应用程序决定如何在受控设备中完成数据平面转发和其他服务(如防火墙和负载均衡)。ODL提供了两种方式,应用程序可以通过这种方式与本机控制器服务(以及设备)以及彼此进行互操作。在API驱动(AD-SAL)方法中,如图5.17所示,应用程序使用运行在HTTP上的REST请求-响应API与控制器模块通信。OpenDaylight控制器的最初版本只提供了AD-SAL。随着ODL越来越多地用于网络配置和管理,后来的ODL版本引入了一种模型驱动(MD-SAL)方法。在这里,YANG数据建模语言[RFC 6020]定义了设备、协议、网络配置和运行状态数据的模型。然后通过使用NETCONF协议操纵这些数据来配置和管理设备。
ONOS控制器
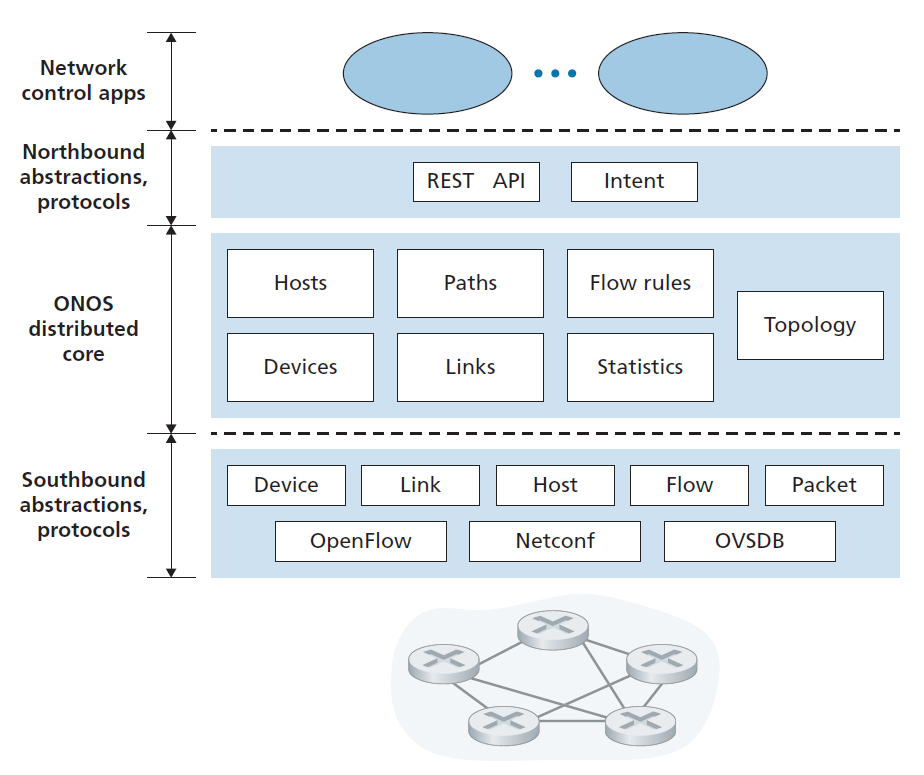
图5.18展示了ONOS控制器的简化视图[ONOS 2020]。与图5.15中的规范控制器类似,ONOS控制器中可以识别三层:
- 北向抽象和协议 ONOS的一个独特的特性是其框架,它允许应用程序请求一个高层次的服务(例如,设置一个主机A和主机B之间的连接,或相反,不允许主机A和主机B通信),而无需知道这个服务是如何执行的细节。状态信息通过北向API同步(通过查询)或异步(通过监听器回调,例如,当网络状态发生变化时)提供给网络控制应用程序。
- Distributed core 网络的链路、主机、设备状态在ONOS的分布式核心中维护。ONOS作为一种服务部署在一组相互连接的服务器上,每个服务器都运行一份相同的ONOS软件副本;服务器数量的增加提供了更大的服务容量。ONOS核心提供了实例间服务复制和协调的机制,为上面的应用程序和下面的网络设备提供了逻辑上中心化的核心服务抽象。
- 南向抽象和协议 南向抽象掩盖了底层主机、链路、交换机和协议的异构性,从而允许分布式核心既不依赖设备,也不依赖协议。由于这种抽象,分布式核心下面的南向接口在逻辑上比图5.14中的规范控制器或图5.17中的ODL控制器更高。
5.6 ICMP: Internet控制消息协议
ICMP (Internet Control Message Protocol)是由[RFC 792]规定的,用于主机和路由器之间的网络层信息通信。ICMP最典型的用途是错误报告。例如,在运行HTTP会话时,您可能会遇到诸如“目标网络不可达”之类的错误消息。该消息起源于ICMP。在某些情况下,IP路由器无法找到HTTP请求中指定的主机的路径。该路由器创建并发送一个ICMP消息到您的主机,表明错误。
ICMP通常被认为是IP的一部分,但在体系结构上它位于IP之上,因为ICMP消息是在IP数据报中携带的。也就是说,ICMP消息作为IP负载携带,就像TCP或UDP段作为IP负载携带一样。类似地,当主机接收到指定为ICMP的上层协议(上层协议号为1)的IP数据报时,它将数据报内容解复用(demultiplex)到ICMP,就像它将数据报内容解复用到TCP或UDP一样。
ICMP消息有一个type字段和一个code字段,包含导致ICMP消息生成的IP数据报的头和前8个字节(以便发送方可以确定导致错误的数据报)。ICMP消息类型如图5.19所示。注意,ICMP消息不仅用于发送错误信息。
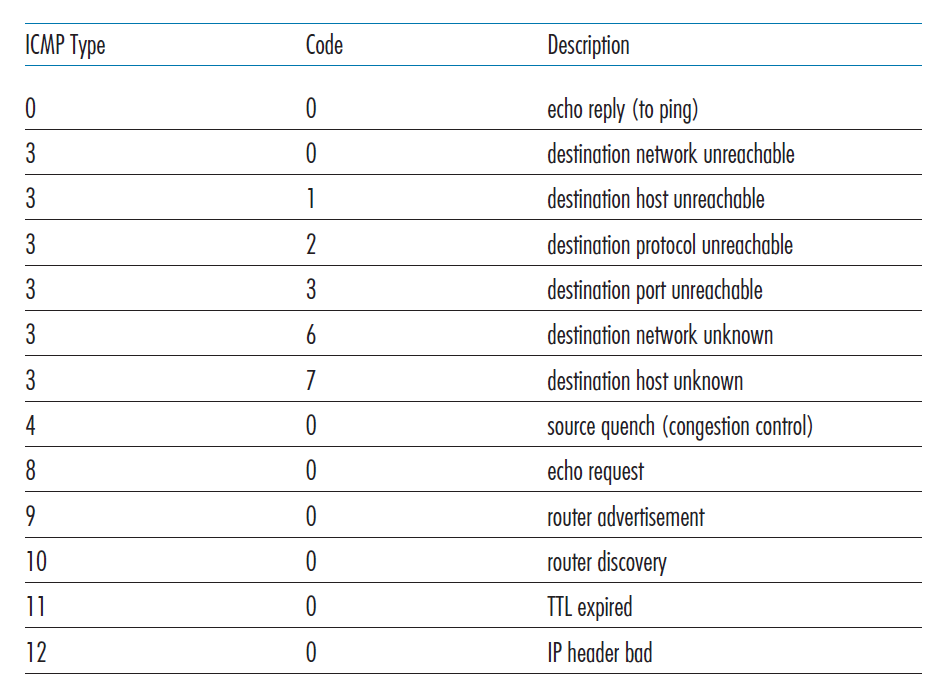
知名的ping程序向指定的主机发送一个type为8 ,code为0的ICMP消息。目标主机看到echo请求后,发送回一个type为0 ,code为0的ICMP echo应答。大多数TCP/IP实现在操作系统中直接支持ping服务器;也就是说,服务器不是进程。[Stevens 1990]的第11章提供了ping客户端程序的源代码。注意,客户端程序需要能够指示操作系统生成type为8,code为0的ICMP消息。
另一个有趣的ICMP消息是源抑制(quench)消息。这条消息在实践中很少使用。它最初的目的是实现拥塞控制——允许拥塞路由器向主机发送ICMP源抑制消息,迫使主机降低其传输速率。我们在第三章已经看到TCP有它自己的传输层拥塞控制机制,并且显式拥塞通知位可以被网络后端设备用来发出拥塞信号。
在第一章中,我们介绍了Traceroute程序,它允许我们跟踪从一个主机到世界上任何其他主机的路由。有趣的是,Traceroute是用ICMP消息实现的。为了确定源端和目标端的路由器名称和地址,源端的Traceroute会向目标端发送一系列普通的IP数据报。每个这些数据报携带一个UDP段与一个不太可能的(unlikely)UDP端口号。第一个数据报的TTL为1,第二个为2,第三个为3,依此类推。源还为每个数据报启动计时器。当第n个数据报到达第n个路由器时,第n个路由器发现该数据报的生存时间刚刚过期。根据IP协议的规则,路由器丢弃该数据报,并向源(type为11,code0)发送包括路由器名称和IP地址在内的ICMP警告消息。当该ICMP消息返回到源端时,源端从定时器中获取往返的时间,从ICMP消息中获取第n台路由器的名称和IP地址。
Traceroute源如何知道何时停止发送UDP段?回想一下,源为它发送的每个数据报增加TTL字段。因此,其中一个数据报将最终到达目标主机。因为这个数据报包含一个UDP段,不太可能的端口号,目标主机向源发送一个端口不可达的ICMP消息(type为3,code为3)。当源主机接收到这个特定的ICMP消息时,它知道它不需要发送额外的探测数据包。(标准的Traceroute程序实际上发送三组TTL相同的数据包;因此,Traceroute输出为每个TTL提供三个结果。)
通过这种方式,源主机可以了解到它与目标主机之间的路由器数量和身份,以及两者之间的往返时间。注意,Traceroute客户端程序必须能够指示操作系统生成具有特定TTL值的UDP数据报,并且必须能够在ICMP消息到达时得到操作系统的通知。现在您已经了解了Traceroute的工作原理,您可能想要更多地使用它。
RFC 4443为IPv6定义了一个新的ICMP版本。除了重新组织现有的ICMP type和code定义外,ICMPv6还增加了新的IPv6功能所需的type和code。这包括“Packet Too Big” type和"unrecognized IPv6 options"错误code。
5.7网络管理和SNMP协议 NETCONF/YANG
现在我们已经结束了对网络层的研究,只剩下链路层,我们很清楚,网络由许多复杂的、相互作用的硬件和软件组成,这些硬件和软件来自链路、交换机、路由器、主机、和其他组成网络物理组件的设备到许多协议来控制和协调这些设备。当一个组织将数百或数千个这样的组件组合在一起形成一个网络时,网络管理员保持网络正常运行的工作无疑是一个挑战。我们在第5.5节中看到,逻辑上中心化的控制器可以在SDN环境中帮助处理这个过程。但是网络管理的挑战早在SDN网络之前就已经存在了,SDN网络提供了一套丰富的网络管理工具和方法,帮助网络管理员监控、管理和控制网络。我们将在本节中研究这些工具和技术,以及与SDN共同发展的新工具和技术。
人们常问:什么是网络管理?[Saydam 1996]对网络管理的一个构思良好的单句(尽管是一个相当长的连续句)定义是:
网络管理包括对网络和网元(element)资源进行监控、测试、轮询、配置、分析、评估和控制,以合理的成本实现对网络和网元资源的实时性、可操作性和服务质量的要求。
鉴于这个宽泛的定义,我们将在本节中只介绍网络管理的基础知识——网络管理员在执行其任务时所使用的体系结构、协议和数据。我们将不讨论管理员的决策过程,其中的主题包括故障识别[Labovitz 1997;Steinder 2002;Feamster 2005;Wu 2005;Teixeira 2006],异常检测[Lakhina 2005;Barford 2009],网络设计/工程,以满足合同服务级协议(SLA,Service Level Agreements)[Huston 1999a],以及更多的考虑。感兴趣的读者可以参考这些参考资料,在[Subramanian 2000;Schonwalder 2010;Claise 2019],更详细的网络管理的处理可在此文本网站。
5.7.1网络管理框架
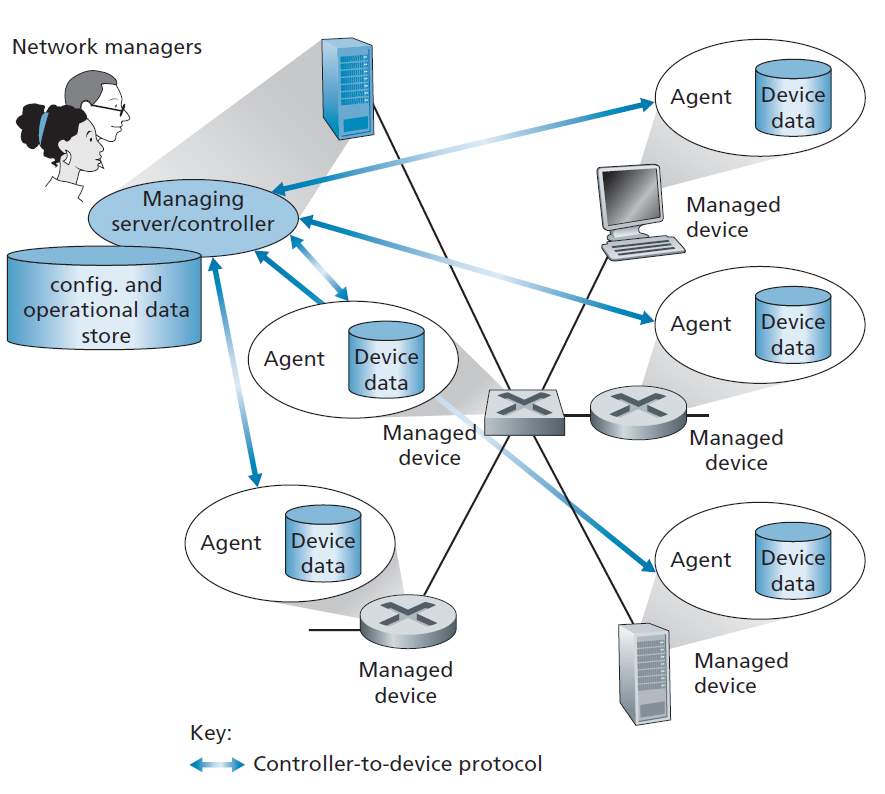
网络管理的关键组成部分如图5.20所示:
- 管理服务器 管理服务器是一个应用程序,通常在网络操作中心(NOC)的集中网络管理站中运行, 网络管理员 (人)也在循环中。管理服务器是网络管理的活动所在地,控制着网络管理信息和命令的收集、处理、分析和分发。在这里启动配置、监视和控制网络管理设备的操作。在实践中,一个网络可能有几个这样的管理服务器。
- 被管理设备 被管理设备是驻留在被管理网络上的一组网络设备(包括其软件)。被管理设备可以是主机、路由器、交换机、中间设备、调制解调器、温度计或其他网络连接设备。设备本身将有许多可管理的组件(例如,一个网络接口只是主机或路由器的一个组件),以及这些硬件和软件组件的配置参数(例如,一个AS内路由协议,如OSPF)。
- 数据 每个被管理设备都有与之关联的数据,也称为状态。有几种不同类型的数据。 配置数据 是指网络管理员明确配置的设备信息,如管理员为设备接口分配/配置的IP地址、接口速率等。 操作数据 是设备在运行过程中获取的信息,例如OSPF协议中的邻居列表。 设备统计 是指随着设备操作员更新的状态指标和计数(如接口丢弃的数据包数、设备冷却风扇转速)。网络管理员可以查询远端设备数据,在某些情况下,通过写入设备数据值来控制远端设备,如下所述。如图5.17所示,管理服务器还维护来自其被管理设备的配置、操作和统计数据以及全网数据(例如网络拓扑)的自己的副本。
- 网络管理代理 网络管理代理是运行在被管理设备上的一个软件进程,它与管理服务器通信,在管理服务器的命令和控制下在被管理设备上执行本地操作。网络管理代理类似于我们在图5.2中看到的路由代理。
- 网络管理协议 网络管理框架的最后一个组成部分是网络管理协议。该协议运行在管理服务器和被管理设备之间,允许管理服务器查询被管理设备的状态,并通过其代理在这些设备上采取操作。代理可以使用网络管理协议通知管理服务器异常事件(例如,组件故障或违反性能阈值)。需要注意的是,网络管理协议本身并不管理网络。相反,它提供了网络管理员可以用来管理(监视、测试、轮询、配置、分析、评估和控制)网络的功能。这是一个微妙但重要的区别。
在实践中,网络操作员管理网络的常用方法有三种,使用上述组件:
- CLI 网络操作员可以向设备发出CLI(CLI,Command Line Interface)命令。这些命令可以在被管理设备的控制台上直接输入(如果操作人员在设备上),或者通过Telnet或安全外壳(SSH)连接,可能通过脚本,网络操作员可以向设备发出直接的命令行接口(CLI)命令。CLI命令是特定于供应商和设备的,可能相当神秘。虽然经验丰富的网络向导可能能够使用CLI完美地配置网络设备,但CLI的使用很容易出错,并且很难实现自动化或有效地扩展大型网络。面向消费者的网络设备,例如您的无线家庭路由器,可以导出一个管理菜单,您(网络管理员!)可以通过HTTP访问来配置该设备。虽然这种方法可以很好地用于单一的、简单的设备,而且比CLI更不容易出错,但它也不能扩展到更大的网络。
- SNMP/MIB 通过这种方式,网络操作员可以通过 SNMP (Simple network Management Protocol)对设备的 MIB (Management Information Base)对象中包含的数据进行查询和设置。一些MIB是特定于设备和供应商的,而其他的MIB(例如,由于IP数据报头错误而在路由器上丢弃的IP数据报的数量,或在主机上接收的UDP段的数量)是设备无关的,提供了抽象和通用。网络运营商通常使用这种方法来查询和监视操作状态和设备统计信息,然后使用CLI主动控制/配置设备。我们注意到,重要的是,这两种方法都单独管理设备。我们将在下面的第5.7.2节中介绍自20世纪80年代末以来一直在使用的SNMP和MIB。互联网架构委员会在2002年召开的网络管理研讨会[RFC 3535]不仅指出了SNMP/ MIB方法在设备监控方面的价值,也指出了它的缺点,特别是在大规模的设备配置和网络管理方面。这就产生了最新的网络管理方法,使用NETCONF和YANG。
- NETCONF/YANG NETCONF/YANG方法对网络管理采取了更抽象、全网络(network-wide)和整体(holistic)的观点,更强调配置管理,包括指定正确性约束和提供对多个受控设备的原子管理操作。YANG [RFC 6020]是一种用于对配置和操作数据建模的数据建模语言。NETCONF协议[RFC 6241]用于与YANG兼容的操作和与远程设备(或远程设备之间)数据通信。我们在图5.17中OpenDaylight Controller的案例研究中简要地遇到了NETCONF和YANG,并将在下面的5.7.3节中研究它们。
5.7.2 SNMP与MIB
简单网络管理协议 第三版 (Simple Network Management Protocol version 3) [RFC 3410]是一种应用层协议,用于在管理服务器和代表该管理服务器执行的代理之间传递网络管理控制和信息消息。SNMP最常见的用法是采用请求-响应模式,在这种模式中,SNMP管理服务器向SNMP代理发送请求,他接收请求,执行一些操作,并向请求发送应答。通常,一个请求将用于查询(检索)或修改(设置)与被管理设备相关的MIB对象的值。SNMP的第二种常见用法是代理向管理服务器发送未经请求的消息(称为trap消息)。Trap消息用于通知管理服务器异常情况(如链路接口up或down),导致MIB对象值发生变化。
MIB节点由SMI(Structure of Management Information)数据描述语言指定[RFC 2578;RFC 2579;RFC 2580],这是网络管理框架的一个命名很奇怪的组件,它的名字没有给出其功能的任何提示!将相关MIB对象集合成MIB模块。截至2019年底,已有超过400个与MIB相关的RFC和更多供应商专用(私有)的MIB模块。
SNMPv3定义了七种类型的消息,通常被称为协议数据单元——PDU——如表5.2所示。PDU格式如图5.21所示。
 表5.2 SNMPv3 PDU 类型
表5.2 SNMPv3 PDU 类型
- GetRequest、GetNextRequest和GetBulkRequest PDU都是由管理服务器发送给代理,请求被管理设备上的一个或多个MIB节点的值。PDU的变量绑定部分指定被请求值的MIB对象。GetRequest、GetNextRequest和GetBulkRequest的数据请求粒度不同。GetRequest可以请求任意一组MIB值;可以使用多个GetNextRequests对MIB对象列表(list)或表(table)进行排序;GetBulkRequest允许返回大数据块,避免了发送多个GetRequest或GetNextRequest消息时产生的开销。在这三种情况下,代理都用一个包含对象标识符及其关联值的Response PDU进行响应。
- SetRequest PDU用于管理服务器设置被管理设备中一个或多个MIB对象的值。代理返回一个Response PDU,状态为noError,以确认该值确实已被设置。
- InformRequest PDU用于管理服务器将与接收服务器相距较远的MIB信息通知另一个管理服务器。
- Response PDU通常从被管理设备发送到管理服务器,以响应来自该服务器的请求消息,返回所请求的信息。
- SNMPv3 PDU的最后一种类型是trap消息。trap消息是异步生成的;也就是说,它们不是根据接收到的请求而生成的,而是根据管理服务器需要通知的事件而生成的。RFC 3418定义了众所周知的trap类型,包括设备冷启动或热启动、链路up或down、邻居丢失、认证失败事件等。接收到的trap请求没有需要管理服务器的响应。
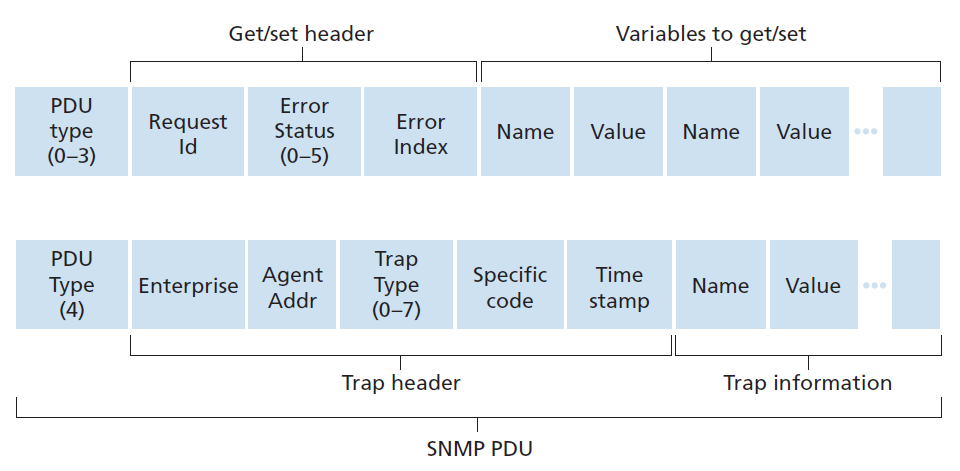
鉴于SNMP的请求-响应特性,这里值得注意的是,尽管SNMP PDU可以通过许多不同的传输协议进行传输,但SNMP PDU通常在UDP数据报的负载中进行传输。实际上,RFC 3417指出UDP是"the preferred transport mapping"。然而,由于UDP是一个不可靠的传输协议,不能保证请求或其响应将在预期的目的地接收。PDU(参见图5.21)的请求ID字段被管理服务器用来给代理编号;代理的响应从接收到的请求中获取其请求ID。因此,管理服务器可以使用请求ID字段来检测丢失的请求或应答。如果在给定的时间内没有收到相应的响应,则由管理服务器决定是否重新传输请求。特别是,SNMP标准并不强制要求进行任何特定的重传过程。它只要求管理服务器需要对重传的频率和持续时间负责。当然,这让人想知道一个负责任的协议应该如何行动。
SNMP已经发展了三个版本。SNMPv3的设计者说,SNMPv3可以被认为是具有额外安全性和管理能力的SNMPv2 [RFC 3410]。当然,SNMPv3比SNMPv2有一些变化,但这些变化在管理和安全领域最为明显。安全性在SNMPv3中的核心作用尤其重要,因为缺乏足够的安全性导致SNMP主要用于监控而不是控制(例如,SetRequest在SNMPv1中很少使用)。我们再次看到,安全——我们将在第8章详细讨论的话题——是一个至关重要的问题,但它的重要性再次被意识到可能有点晚,只有在那时才被添加进来。
管理信息库(MIB)
我们之前了解到,在网络管理的SNMP/MIB方法中,被管理设备的运行状态数据(在一定程度上是它的配置数据)被表示为对象,这些对象被收集到该设备的MIB中。一个MIB对象可以是一个计数器,例如由于IP数据报报头错误而被路由器丢弃的IP数据报的数量;或以太网接口卡中的载波感知(carrier sense)错误数;描述性信息,如在DNS服务器上运行的软件版本;状态信息,如特定设备是否运行正常;或协议专有的信息,如到目的地的路由路径。在各种IETC RFC中定义了超过400个MIB模块;还有更多专用于设备和供应商的MIB。[RFC 4293]指定了定义被管理对象(包括ipSystemStatsInDelivers)的MIB模块,用于管理IP (Internet Protocol)及其相关ICMP (Internet Control Message Protocol)协议的实现。[RFC 4022]为TCP协议使用的MIB模块,[RFC 4113]为UDP协议使用的MIB模块。
虽然与MIB相关的RFC读起来相当乏味和枯燥,但考虑一个MIB对象的例子仍然是有益的(例如,就像吃蔬菜一样,这对你是有好处的),ipSystem-StatsInDelivers 该对象类型定义自[RFC 4293],定义了一个32位只读计数器,用于跟踪从被管理设备接收并成功交付给上层协议的IP数据报的数量。在下面的例子中,Counter32是SMI中定义的基本数据类型之一。
ipSystemStatsInDelivers OBJECT-TYPE
SYNTAX Counter32
MAX-ACCESS read-only
STATUS current
DESCRIPTION
“成功发送到ipuser协议(包括ICMP)的数据报总数。跟踪接口统计信息时,
数据报地址所在接口的计数器将递增。此接口可能与某些数据报的输入接口不同。
该计数器的值在管理系统重新初始化时中断,以及ipSystemStatsDiscontinuityTime
的值所指示的其他时间中断。”
::= { ipSystemStatsEntry 18 }5.7.3网络配置协议(NETCONF)和YANG
NETCONF协议在管理服务器和被管理网络设备之间运行,为(i)检索、设置和修改被管理设备上的配置数据提供消息;(ii)查询被管理设备的运作数据和统计数据;以及(iii)订阅由被管理设备产生的通知。管理服务器通过向其发送配置(在结构化XML文档中指定)并激活被管理设备上的配置来主动控制被管理设备。NETCONF使用远程过程调用(RPC,remote procedure call)范式,其中协议消息也用XML编码,并通过安全的、面向连接的会话(如TCP上的TLS(Transport Layer Security)协议(在第8章中讨论))在管理服务器和被管理设备之间交换。
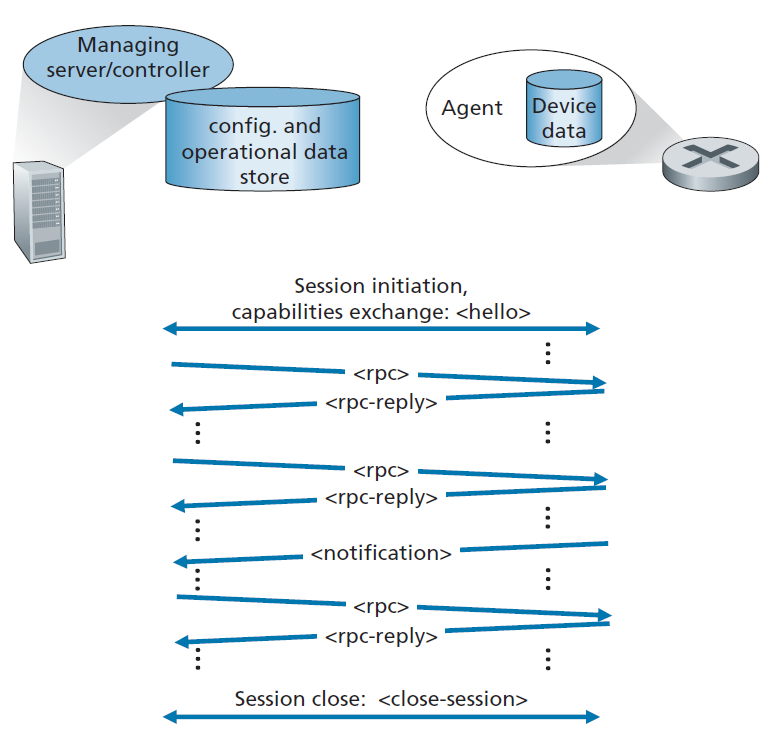
图5.22显示了一个NETCONF会话示例。首先,管理服务器与被管理设备建立安全连接。(在NETCONF术语中,管理服务器实际上被称为客户端,而被管理设备被称为服务器,因为管理服务器建立了与被管理设备的连接。但是为了与图5.20中所示的长期存在的网络管理服务器/客户端术语保持一致,这里我们将忽略这一点。)一旦建立了安全连接,管理服务器和被管理设备就会交换hello消息,宣布他们的"能力"——补充[RFC 6241]中基本NETCONF规范的NETCONF功能。管理服务器和被管理设备之间的交互采用远程过程调用的形式,使用rpc和rpc-response消息。这些消息用于检索、设置、查询和修改设备配置、操作数据和统计数据,以及订阅设备通知。设备通知本身使用NETCONF notification消息主动地从被管理设备发送到管理服务器。session-close message用于关闭会话。
表5.3显示了管理服务器可以在被管理设备上执行的许多重要NETCONF操作。在SNMP的情况下,我们看到获取操作状态数据的操作(get),和事件通知。然而,get-config, edit-config, lock 和 unlock操作演示了NETCONF特别重要的设备配置。使用表5.3所示的基本操作,还可以创建一组更复杂的网络管理事务,这些事务要么以原子方式(即作为一个组)完成并成功地在一组设备上完成,要么完全反转并使设备处于事务前状态。这种多设备事务——transactions—“使操作员能够专注于网络的整体配置而不是单个设备”是[RFC 3535]中提出的一项重要的操作员需求。
| NETCONF操作 | 描述 |
|---|---|
| get-config | 获取给定配置的全部或部分。一个设备可以有多种配置。总是有一个running/配置来描述设备当前(运行)配置。 |
| get | 获取配置状态和操作状态数据的全部或部分。 |
| edit-config | 更改被管理设备上指定配置的全部或部分。如果指定了running/配置,那么设备的当前(运行)配置将被更改。如果被管理设备能够满足请求,则发送一个rpc-reply,包含一个ok元素;否则返回rpcerror响应。发生错误时,设备的配置状态可以回滚到以前的状态。 |
| lock, unlock | lock (unlock)操作允许管理服务器锁定(解锁)被管理设备的整个配置数据存储系统。锁是短期的,允许客户端进行更改,而不必担心与来自其他源的其他NETCONF、SNMP或CLI命令交互。 |
| create-subscription,notification | 此操作启动一个事件通知订阅,该订阅将为被管理设备感兴趣的指定事件发送异步事件notification到管理服务器,直到该订阅终止。 |
表5.3 NETCONF操作
NETCONF的完整描述超出了我们的范围;[RFC 6241, RFC 5277, Claise 2019;Schonwalder 2010]提供更深入的报道。
但是,由于这是我们第一次看到格式化为XML文档的协议消息(而不是传统的带有头字段和消息主体的消息,例如,如图5.21所示的SNMP PDU),让我们用两个例子来结束我们对NETCONF的简要研究。
在第一个示例中,从管理服务器发送到被管理设备的XML文档是一个请求所有设备配置和操作数据的NETCONFget命令。通过该命令,服务器可以了解设备的配置信息。
01 <?xml version=”1.0” encoding=”UTF-8”?>
02 <rpc message-id=”101”
03 xmlns=”urn:ietf:params:xml:ns:netconf:base:1.0”>
04 <get/>
05 </rpc>尽管很少有人能完全直接解析XML,但我们看到NETCONF命令相对来说是比较容易读懂的,它比我们在图5.21中看到的SNMP PDU格式的协议消息格式更容易让人想起HTTP和HTML。RPC消息本身跨越了02 - 05行(为了教学目的,我们在这里添加了行号)。RPC的消息ID值为101,在第02行中声明,并包含单个NETCONF get命令。设备的应答包含一个匹配的ID号(101),以及设备的所有配置数据(XML格式),从第04行开始,最后以rpc-reply结束。
下面的第二个例子改编自[RFC 6241],从管理服务器发送到被管理设备的XML文档将名为Ethernet0/0的接口的最大传输单元(MTU)设置为1500字节:
01 <?xml version=”1.0” encoding=”UTF-8”?>
02 <rpc message-id=”101”
03 xmlns=”urn:ietf:params:xml:ns:netconf:base:1.0”>
04 <edit-config>
05 <target>
06 <running/>
07 </target>
08 <config>
09 <top xmlns=”http://example.com/schema/
1.2/config”>
10 <interface>
11 <name>Ethernet0/0</name>
12 <mtu>1500</mtu>
13 </interface>
14 </top>
15 </config>
16 </edit-config>
17 </rpc>RPC消息本身跨越02-17行,消息ID值为101,并且包含一个单一的NETCONF edit-config命令,跨越04-15行。行06表示被管理设备当前运行的设备配置会发生变化。第11、12行指定要设置的Ethernet0/0接口的MTU大小。
一旦被管理设备在配置中更改了接口的MTU大小,它就用一个OK回复响应管理服务器(下面的第04行),同样是在XML文档中:
01 <?xml version=”1.0” encoding=”UTF-8”?>
02 <rpc-reply message-id=”101”
03 xmlns=”urn:ietf:params:xml:ns:netconf:base:1.0”>
04 <ok/>
05 </rpc-reply>YANG
YANG是一种数据建模语言,用于精确指定NETCONF使用的网络管理数据的结构、语法和语义,其方式与在SNMP中使用SMI指定MIB的方式非常相似。所有YANG定义都包含在模块中,可以从YANG模块生成描述设备及其功能的XML文档。
YANG提供了一组小的内置数据类型(在SMI的情况下),还允许数据建模者表达必须由有效的NETCONF配置满足的约束,这是帮助确保NETCONF配置满足指定的正确性和一致性约束的强大帮助。YANG还用于指定NETCONF通知。
关于YANG的更详细的讨论超出了我们的范围。欲了解更多信息,我们推荐感兴趣的读者阅读这本优秀的书[Claise 2019]。
5.8总结
我们现在已经完成了对网络核心的两章研究——从第四章中对网络层数据平面的研究开始,到现在对网络层控制平面的研究结束。我们了解到,控制平面是网络范围内的逻辑,它不仅控制数据报如何沿着从源主机到目标主机的端到端路径在路由器之间转发,而且还控制如何配置和管理网络层组件和服务。
我们了解到有两种广泛的方法来构建控制平面:传统的逐-路由器控制(路由算法在每台路由器上运行,路由器中的路由组件与其他路由器中的路由组件通信)和软件定义网络(SDN)控制(逻辑上中心化的控制器计算和分发转发表,供每台路由器使用)。我们研究了图链路状态路由和距离矢量路由中计算最小开销路径的两种基本路由算法——5.2节中;这些算法在逐-路由器控制和SDN网络控制中都有应用。这些算法是我们在5.3节和5.4节中介绍的两种广泛部署的互联网路由协议OSPF和BGP的基础。在第5.5节中,我们讨论了SDN网络层控制平面的方法,研究了SDN网络控制应用程序、SDN控制器以及用于控制器和SDN控制设备之间通信的OpenFlow协议。在5.6节和5.7节中,我们介绍了管理IP网络的一些具体细节:ICMP (Internet控制消息协议)和使用SNMP和NETCONF/YANG进行网络管理。
在完成了对网络层的研究之后,我们的旅程现在将我们带到协议栈的下一个步骤,即链路层。和网络层一样,链路层也是每一个网络连接设备的一部分。但是我们将在下一章中看到,链路层的任务更加本地化,即在同一链路或局域网的节点之间移动数据包。虽然与网络层的任务相比,这个任务表面上看起来相当简单,但我们将看到链路层涉及许多重要而迷人的问题,这些问题会让我们忙碌很长时间。