第三章 传输层
第三章 传输层
传输层位于应用程序层和网络层之间,是分层网络体系结构的中心部分。它的关键作用是直接向运行在不同主机上的应用程序进程提供通信服务。在本章中,我们采用的教学方法是交替讨论传输层原则和讨论如何在现有协议中实现这些原则;和往常一样,我们将特别强调因特网协议,特别是TCP和UDP传输层协议。
我们将从讨论传输层和网络层之间的关系开始。这为检查传输层的第一个关键功能做好准备:将网络层两个终端系统之间的交付服务扩展到运行在终端系统上的两个应用层进程之间的交付服务。我们将在因特网的无连接传输协议UDP中说明这个功能。
然后,我们将回到原理,并面对计算机网络中最基本的问题之一,即两个实体如何在可能丢失和损坏数据的介质上可靠地通信。通过一系列日益复杂的场景,我们将构建一系列传输协议用来解决这个问题。然后,我们将展示这些原则如何在TCP (Internet的面向连接的传输协议)中具体表达。
接下来,我们将讨论网络中第二个重要的基本问题——控制传输层实体的传输速率,以避免网络中的拥塞或从拥塞中恢复过来。我们将考虑拥塞的原因和后果,以及常用的拥塞控制技术。在对拥塞控制背后的问题有了坚实的理解之后,我们将研究TCP的拥塞控制方法。
3.1 介绍和传输层服务
在前两章中,我们讨论了传输层的角色及其提供的服务。让我们快速回顾一下我们已经学过的关于传输层的内容。
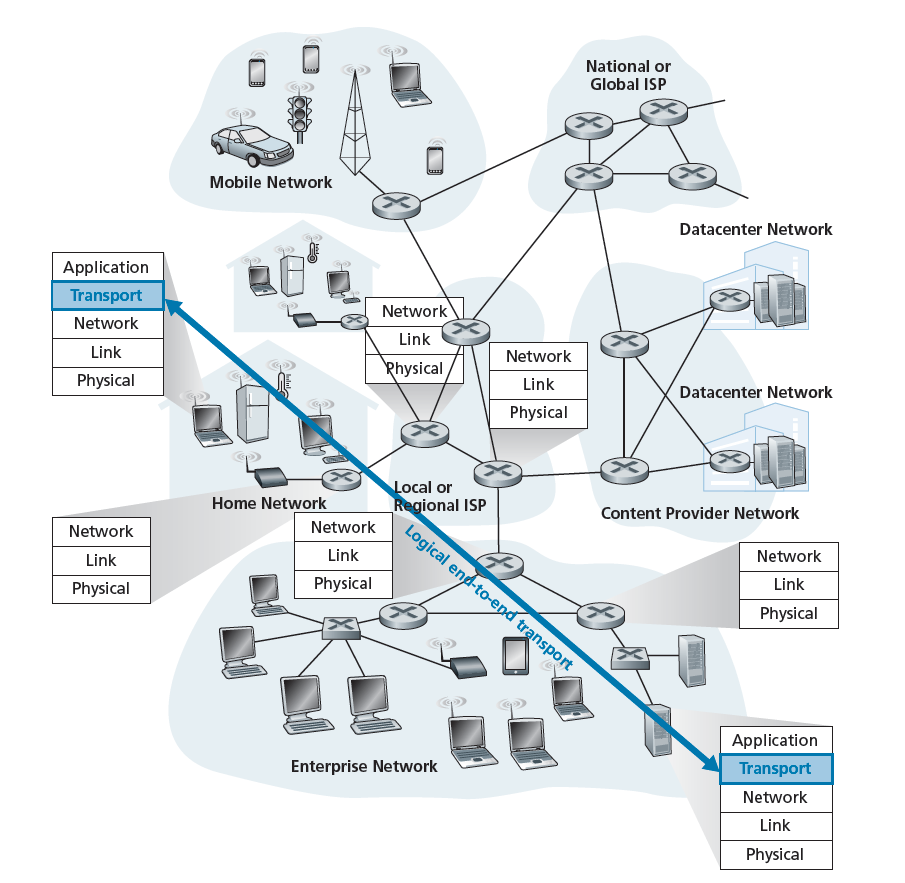
传输层协议提供了运行在不同主机上的应用程序进程之间的 逻辑通信(logical communication) 。通过逻辑通信,我们的意思是,从应用程序的角度来看,就像运行进程的主机是直接连接的;在现实中,主机可能在地球的另一端,通过无数路由器和各种各样的链路类型连接。应用程序进程使用传输层提供的逻辑通信来相互发送消息,而不必担心用于承载这些消息的物理基础设施的细节。图3.1说明了逻辑通信的概念。
如图3.1所示,传输层协议是在终端系统中实现的,而不是在网络路由器中。在发送方,传输层将它从发送应用程序进程中接收到的应用层消息转换为传输层数据包,在Internet术语中称为传输层段(segments)。这是通过(可能的)将应用程序消息分解为更小的块,并向每个块添加传输层头来创建传输层段来实现的。然后,传输层将这个段交付给发送方系统的网络层,在那里,这个段被封装在一个网络层数据包(一个数据报)中,并发送到目的地。重要的是要注意,网络路由器只作用于数据报的网络层字段;也就是说,它们不检查被数据报封装的传输层段的字段。在接收方,网络层从数据报中提取传输层段,并将该段向上交付给传输层。然后传输层处理接收到的段,使段中的数据对接收应用程序可用。
网络应用程序可以使用一个以上的传输层协议。例如,Internet有两个协议:TCP和UDP。这些协议中的每一个都为调用应用程序提供了一组不同的传输层服务。
3.1.1传输层与网络层的关系
回想一下,传输层位于协议栈中的网络层之上。传输层协议提供运行在不同主机上的进程之间的逻辑通信,而网络层协议提供主机之间的逻辑通信。这种区别很小,但很重要。让我们借助一个家庭的类比来检验这一区别。
假设有两所房子,一所在东海岸,另一所在西海岸,每所房子都住着十二个孩子。东海岸家庭的孩子是西海岸家庭孩子的表兄妹。这两个家庭的孩子都喜欢互相写信,每个孩子每周都给每个表兄弟写信,每封信都装在一个独立的信封里,通过传统的邮政服务投递。因此,每个家庭每周向另一个家庭发送144封信。(如果这些孩子有电子邮件的话,他们可以省下一大笔钱!)在每个家庭中,都有一个孩子:西海岸房子里的Ann,东海岸房子里的Bill,负责收集和分发邮件。每个星期,Ann都会去看望她所有的兄弟姐妹,收集邮件,并把邮件交给每天都会来的邮递员。当信件到达西海岸的房子,Ann也有分配邮件给她的兄弟姐妹的工作。Bill在东海岸有一份类似的工作。
在本例中,邮政服务提供了两个机构之间的逻辑通信——邮政服务将邮件从一家移动到另一家,而不是从一个人移动到另一个人。另一方面,Ann和Bill提供了表兄妹之间的逻辑交流,Ann和Bill为他们的兄弟姐妹取信和送信。请注意,从表兄妹的角度来看,Ann和Bill是邮件服务,尽管Ann和Bill只是端到端交付过程的一部分(终端系统部分)。这个家喻户晓的例子很好地解释了传输层与网络层之间的关系:
应用程序消息=信封中的信件
进程=表兄妹
主机(也称为终端系统)=房子
传输层协议= Ann和Bill
网络层协议=邮政服务(包括邮递员)继续这个类比,注意Ann和Bill在他们各自的家里做他们所有的工作;例如,它们不涉及在任何中间邮件中心对邮件进行分类或将邮件从一个邮件中心移动到另一个邮件中心等。类似地,传输层协议位于终端系统中。在终端系统中,传输协议将消息从应用程序进程移动到网络边缘(即网络层),反之亦然,但它对如何在网络核心中移动消息没有任何发言权。事实上,如图3.1所示,中间路由器既不处理也不识别传输层可能添加到应用程序消息中的任何信息。
继续我们的家庭故事,假设现在当Ann和Bill去度假时,另一对表兄弟姐妹,Susan和Harvey代替他们,提供家庭内部的邮件收集和投递。对于这两个家庭来说,不幸的是Susan和Harvey并没有按照Ann和Bill完全相同的方式来收集和运送货物。Susan和Harvey年纪还小,他们收发邮件的频率就不那么频繁了,偶尔还会丢信(信有时会被家里的狗咬烂)。因此,表姐妹Susan和Harvey不提供与Ann和Bill相同的服务集(即相同的服务模型)。以类似的方式,计算机网络可以提供多个传输协议,每个协议为应用程序提供不同的服务模型。
Ann和Bill能提供的服务显然受到邮政服务可提供的服务的限制。例如,如果邮政服务不提供这两家之间的邮递时间约定(例如,一日达),Ann和Bill就不能保证表兄间的信件收发。以类似的方式,传输协议可以提供的服务通常受到底层网络层协议的服务模型的约束。如果网络层协议不能为主机之间发送的传输层段提供延迟或带宽保证,那么传输层协议就不能为进程之间发送的应用程序消息提供延迟或带宽保证。
然而,即使底层网络协议没有在网络层提供相应的服务,传输协议也可以提供某些服务。例如,我们将在本章中看到,即使底层网络协议不可靠,也就是说,即使网络协议丢失、乱码或重复数据包,传输协议也可以为应用程序提供可靠的数据传输服务。作为另一个例子(我们将在第8章讨论网络安全时讨论这个例子),传输协议可以使用加密来保证应用程序消息不会被入侵者读取,即使网络层不能保证传输层段的机密性。
3.1.2 Internet传输层概述
回想一下,Internet为应用层提供了两个不同的传输层协议。这些协议之一是 UDP (User Datagram Protocol),它为调用方(invoking)应用程序提供了一个不可靠的、无连接的服务。第二个协议是 TCP (Transmission Control Protocol),它为调用方应用程序提供可靠的、面向连接的服务。在设计网络应用程序时,应用程序开发人员必须指定这两种传输协议之一。正如我们在2.7节中看到的,应用程序开发人员在创建套接字时要在UDP和TCP之间进行选择。
为了简化术语,我们将传输层数据包称为一个 段(segment) 。然而,我们提到,Internet文献(例如RFC)也将TCP的传输层数据包作为一个段,但通常将UDP的数据包称为数据报(datagram)。然而,同样的网络文献也使用术语数据报来表示网络层数据包!对于这样一本介绍计算机网络的书,我们认为将TCP和UDP数据包都称为段,并将术语数据报保留为网络层数据包,这样不容易混淆。
在开始简要介绍UDP和TCP之前,先简单介绍一下因特网的网络层是很有用的。(我们将在第4章和第5章详细了解网络层。)因特网的网络层协议有一个名字——IP,即Internet Protocol。IP提供主机之间的逻辑通信。IP服务模型是一种尽力而为交付服务(best-effort delivery service)。这意味着IP尽最大努力在通信的主机之间交付段,但它不能保证。特别是,它不保证段的交付,它不保证段的有序交付,它不保证段中数据的完整性。基于这些原因,IP被认为是一种不可靠的服务。我们还在这里提到,每台主机至少有一个网络层地址,即所谓的IP地址。我们将在第4章详细介绍IP地址;在本章中,我们只需要记住每个主机都有一个IP地址。
在简要了解了IP服务模型之后,现在让我们总结一下UDP和TCP提供的服务模型。UDP和TCP最基本的职责是将两个端系统之间的IP交付服务扩展为运行在端系统上的两个进程之间的交付服务。将主机到主机的交付扩展到进程到进程的交付称为传输层多路复用(transport-layer multiplexing)和解复用(demultiplexing)。我们将在下一节中讨论传输层复用和解复用。UDP和TCP也通过在它们的段头中包含错误检测字段来提供完整性检查。这两个迷你的传输层服务:进程到进程的数据交付和错误检查,是UDP提供的唯二服务!特别是,像IP, UDP是一个不可靠的服务,它不能保证由一个进程发送的数据将完整地到达目的地进程。UDP将在章节3.3中详细讨论。
另一方面,TCP为应用程序提供了一些额外的服务。首先,它提供 可靠的数据传输 。使用流控制、序列号、确认和计时器(我们将在本章详细探讨这些技术),TCP确保数据从发送进程到接收进程正确有序地交付。因此,TCP将IP在终端系统之间的不可靠服务转换为进程之间的可靠数据传输服务。TCP还提供 拥塞控制(congestion control) 。拥塞控制与其说是提供给调用方应用程序的服务,倒不如说它是为整个互联网提供的服务,是福泽众生的服务。大致地说,TCP拥塞控制防止任何一个TCP连接用过多的流量淹没通信主机之间的链路和路由器。TCP努力给每个穿越拥塞链路的连接提供均等的链路带宽。这是通过调节TCP连接发送方向网络发送流量的速率来实现的。另一方面,UDP流量是不受管制的。一个使用UDP传输的应用程序可以以任何速率发送,只要它喜欢。
提供可靠数据传输和拥塞控制的协议必然是复杂的。我们将需要几个小节来覆盖可靠的数据传输和拥塞控制的原则,以及其他小节来覆盖TCP协议本身。这些主题将在第3.4至3.7节中讨论。本章所采用的方法是在基本原理和TCP协议之间交替使用。例如,我们将首先讨论可靠的数据传输,然后讨论TCP如何专门提供可靠的数据传输。类似地,我们将首先讨论拥塞控制,然后讨论TCP如何执行拥塞控制。但在进入所有这些好东西之前,让我们首先看看传输层多路复用和解复用。
3.2 多路复用和解复用
在本节中,我们将讨论传输层多路复用和解复用,也就是说,将网络层提供的主机到主机的交付服务扩展为运行在主机上的应用程序的进程到进程的交付服务。为了使讨论更加具体,我们将在Internet环境中讨论这个基本的传输层服务。然而,我们要强调的是,所有计算机网络都需要多路复用/解复用服务。
在目标主机上,传输层从下面的网络层接收段。传输层负责将这些段中的数据交付给在主机上运行的适当的应用程序进程。让我们看一个例子。假设您坐在计算机前,正在下载Web页面,同时运行一个FTP会话和两个Telnet会话。因此,有四个网络应用程序进程运行:两个Telnet进程、一个FTP进程和一个HTTP进程。当计算机中的传输层从下面的网络层接收数据时,它需要将接收到的数据指向这四个进程中的一个。现在让我们来看看这是如何做到的。
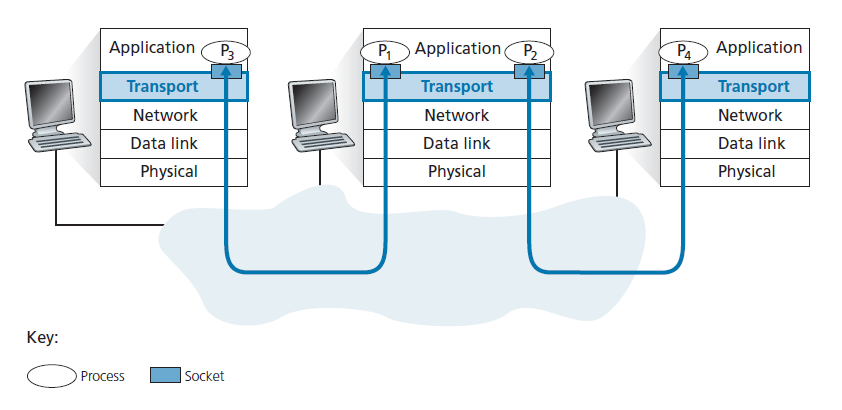
首先回顾2.7节,一个进程(作为网络应用程序的一部分)可以有一个或多个 套接字 (socket),即数据从网络传送到进程和从进程传送到网络的门。因此,如图3.2所示,接收主机中的传输层实际上并不直接将数据交付给进程,而是将数据交付给中间套接字。因为在任何给定的时间,接收主机中都可以有多个套接字,所以每个套接字都有一个唯一的标识符。标识符的格式取决于套接字是UDP套接字还是TCP套接字,我们稍后将对此进行讨论。
现在让我们探讨接收主机如何将传入的传输层段定向到适当的套接字。每个传输层段中都有一组用于此目的的字段。在接收方,传输层检查这些字段以识别接收套接字,然后将段定向到该套接字。 这种在传输层段中将数据交付到正确的套接字的工作称为解复用 。 在源主机上从不同的套接字收集数据块,用头信息(稍后将用于解复用)封装每个数据块以创建段,并将这些段交付给网络层的工作称为多路复用 。注意图3.2中中间主机的传输层必须将从下面网络层到达的段进行解复用到上面的P1或P2进程;即通过将到达的段的数据导向对应进程的socket。中间主机的传输层还必须从这些套接字收集传出的数据,形成传输层段,并将这些段向下交付给网络层。尽管我们已经在Internet传输协议的环境中介绍了多路复用和解复用,但是每当一层(在传输层或其他地方)的单个协议被下一个更高的层的多个协议使用时,了解它们(多路复用和解复用)是关注点非常重要。
为了说明解复用的工作,回想一下前一节中的家庭类比。每个孩子都有他或她的名字。当Bill从邮递员那里收到一批邮件时,他会观察信件的收件人,然后亲手把邮件交给他的兄弟姐妹。当Ann从她的兄弟姐妹那里收集信件,并将收集到的邮件交给邮递员时,她执行了多路复用操作。
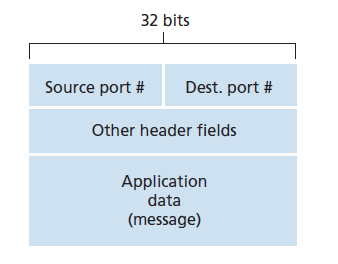
既然我们已经理解了传输层多路复用和解复用的作用,那么让我们来看看它在主机中是如何完成的。从上面的讨论中,我们知道传输层复用要求(1)套接字有唯一的标识符,(2)每个段都有特殊的字段来指示段要交付给的套接字。这些特殊字段,如图3.3所示, 源端口号字段 (source port number field)和 目标端口号字段 (destination port number field)。(UDP和TCP段也有其他字段,如本章后面章节所讨论的那样。)端口号为16 bit整数,取值范围为0 ~ 65535。端口号范围从0到1023被称为 知名端口号 (well-known port numbers),这些端口号是受限制的,这意味着他们是为知名的应用协议保留的,如HTTP(使用80端口号)、FTP(使用21端口号)。已知端口号列表在RFC 1700中给出,并在http://www.iana.org [RFC 3232]中更新。当我们开发一个新的应用程序时(例如在第2.7节中开发的简单应用程序),我们必须为应用程序分配一个端口号。
现在应该清楚传输层如何实现解复用服务:主机中的每个套接字都可以被分配一个端口号,当一个段到达主机时,传输层检查段中的目标端口号,并将该段定向到相应的套接字。段数据然后通过套接字交付给附加的进程。正如我们将看到的,这基本上是UDP做的事。然而,我们也会看到TCP中的多路复用/解复用更加微妙。
无连接多路复用与解复用
回想一下2.7.1节,Python程序在主机上运行时可以使用以下语句创建UDP套接字:
clientSocket = socket(AF_INET, SOCK_DGRAM)当UDP套接字以这种方式创建时,传输层会自动为套接字分配一个端口号。具体来说,传输层分配的端口号范围是1024到65535,当前主机上没有任何其他UDP端口使用这个端口号。或者,在创建套接字之后,可以在Python程序中添加一行代码,通过socket bind()方法将特定的端口号(例如19157)与UDP套接字关联起来:
clientSocket.bind(('', 19157))如果编写代码的应用程序开发人员要实现知名协议的服务器端,那么开发人员必须分配相应的知名端口号。通常,应用程序的客户端让传输层自动(且透明地)分配端口号,而应用程序的服务器端分配特定的端口号。
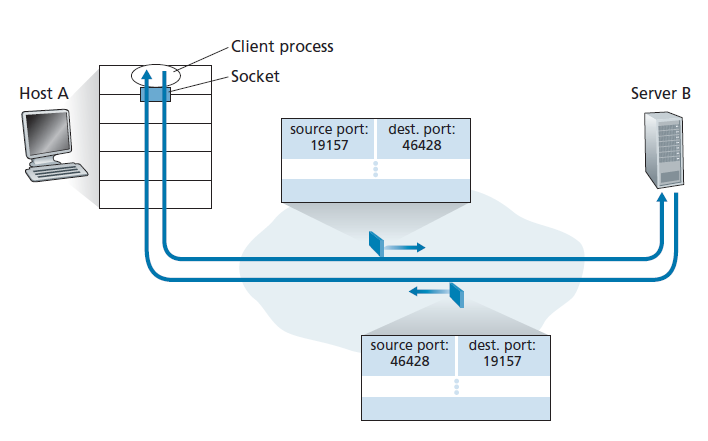
通过将端口号分配给UDP套接字,我们现在可以精确地描述UDP多路复用/解复用。假设主机A中的进程,其UDP端口号是19157,想发送应用程序数据给使用UDP,端口号为46428的主机B,主机A创建包含应用数据的传输层段、源端口号(19157)、目标端口号(46428),还有另外两个值(稍后讨论,但对于当前的讨论不重要)。然后传输层将结果段交付给网络层。网络层将段封装在IP数据报中,并尽最大努力将段发送给接收主机。如果段到达接收主机B,接收主机的传输层检查段(46428)中的目标端口号,并将段发送到由端口46428标识的套接字。注意主机B可能运行多个进程,每个进程都有自己的UDP套接字和相关的端口号。当UDP段从网络到达时,主机B通过检查段的目标端口号来将每个段定向(解复用)到适当的套接字。
重要的是要注意 UDP套接字是由一个二元组(two-tuple)完全标识 的,二元组由一个目标IP地址和一个目标端口号组成。因此,如果两个UDP段有不同的源IP地址和/或源端口号,但有相同的目标IP地址和目标端口号,那么这两个段将通过相同的目标套接字定向到相同的目标进程。
您现在可能想知道,源端口号的目的是什么?如图3.4所示,在A-to-B段中,源端口号作为“返回地址”的一部分——即当B向A发送一个段时,B-to-A段中的目标端口将从A-to-B段的源端口中获取值。(完整的返回地址为A的IP地址和源端口号。)作为一个例子,回想一下在第2.7节中学习的UDP服务器程序。在UDPServer.py中,服务器使用recvfrom()方法在它从客户端接收到的段中提取客户端(源)端口号;然后它向客户端发送一个新的段,提取的源端口号作为这个新段中的目标端口号。
面向连接的多路复用和解复用
为了理解TCP解复用,我们必须仔细研究TCP套接字和TCP连接的建立。TCP套接字和UDP套接字之间的一个细微差别是, TCP套接字由一个四元组(源IP地址、源端口号、目标IP地址、目标端口号)来标识 。因此,当一个TCP段从网络到达主机时,主机使用所有四个值将该段导向(解复用)到适当的套接字。
特别是,与UDP相比,两个到达的不同源IP地址或源端口号的TCP段(携带原始连接建立请求的TCP段除外)将被定向到两个不同的套接字。为了进一步了解,让我们重新考虑2.7.2节中的TCP客户端-服务器编程示例:
- TCP服务器应用程序有一个欢迎套接字,用于等待同TCP客户端建立连接的请求(见图2.29),端口号为12000。
- TCP客户端创建一个套接字并发送一个连接建立请求段:
clientSocket = socket(AF_INET, SOCK_STREAM)
clientSocket.connect((serverName,12000))- 一个连接建立(connection-establishment)请求只不过是一个TCP段,其目标端口号为12000,在TCP头中设置一个特殊的连接建立位(在第3.5节中讨论)。这个段还包括一个由客户端选择的源端口号。
- 当运行服务器进程的计算机的主机操作系统接收到目标端口为12000的连接请求段时,它定位到端口号为12000的正在等待连接的服务器进程。然后服务器进程创建一个新的套接字:
connectionSocket, addr = serverSocket.accept()- 此外,服务器的传输层注意到连接请求段中的以下四个值:(1)段中的源端口号,(2)源主机的IP地址,(3)段中的目标端口号,(4)自己的IP地址。新创建的连接套接字由这四个值标识;后续到达的所有源端口、源IP地址、目标端口和目标IP地址匹配这四个值的段将被解复用到该套接字。有了TCP连接,客户端和服务器就可以互相发送数据了。
聚焦安全之:端口扫描
我们已经看到,服务器进程在一个开放的端口耐心地等待,以便与远程客户端进行联系。一些端口为知名的应用程序保留(例如,Web、FTP、DNS和SMTP服务器);其他端口通常被流行的应用程序使用(例如,Microsoft Windows SQL server侦听UDP端口1434的请求)。因此,如果我们确定某个主机上的端口是开放的,我们就可以将该端口映射到运行在该主机上的特定应用程序。这对于系统管理员非常有用,因为他们通常对了解哪些网络应用程序在其网络中的主机上运行感兴趣。但是,攻击者为了探路(case the joint),还想知道目标主机上哪些端口是开放的。如果找到主机运行的应用程序与一个已知的安全漏洞(例如,一个SQL服务器监听端口1434受制于缓冲区溢出,允许远程用户在脆弱的主机上执行任意代码。通过监狱蠕虫的漏洞利用(CERT 2003 04)),那么主机攻击的时机已经成熟。
确定哪些应用程序正在侦听哪些端口是一项相对简单的任务。事实上,有许多公共领域的程序,称为端口扫描器,就是这样做的。其中使用最广泛的可能是nmap,它可以在http://nmap.org上免费获得,并且包含在大多数Linux发行版中。对于TCP, nmap顺序扫描端口,寻找正在接受TCP连接的端口。对于UDP, nmap再次顺序扫描端口,寻找响应传输UDP段的UDP端口。在这两种情况下,nmap都返回一个打开、关闭或不可达端口的列表。运行nmap的主机可以尝试扫描Internet上任何位置的任何目标主机。在第3.5.6节讨论TCP连接管理时,我们将重新讨论nmap。
如图3.5所示,主机C向服务器B发起两个HTTP会话,主机A向服务器B发起一个HTTP会话。主机A、C和服务器B分别有各自唯一的IP地址A、C和B。主机C为它的两个HTTP连接分配两个不同的源端口号(26145和7532)。因为主机A选择源端口号与C无关,所以它也可能为它的HTTP连接分配一个源端口26145。但这不是问题,服务器B仍然能够正确地将具有相同源端口号的两个连接解复用,因为这两个连接有不同的源IP地址。
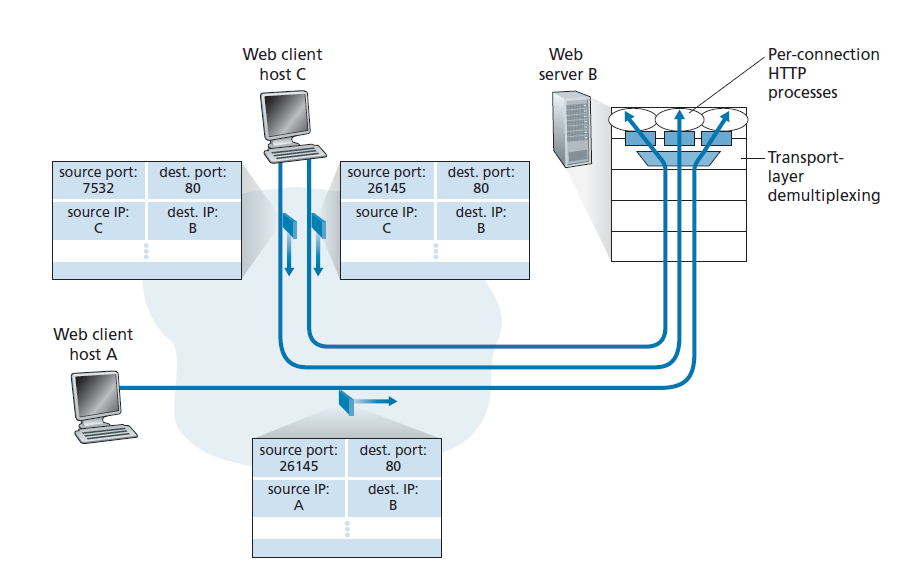
Web服务器和TCP
在结束这个讨论之前,有必要再说几句关于Web服务器和它们如何使用端口号的话。考虑在端口80上运行Web服务器的主机,例如Apache Web服务器。当客户端(例如,浏览器)向服务器发送段时,所有段都有目标端口80。特别是,初始的连接建立段和携带HTTP请求消息的段的目标端口都是80。正如我们刚才描述的,服务器通过源IP地址和源端口号将这些段与不同的客户端区分开来。
图3.5显示了为每个连接生成一个新进程的Web服务器。如图3.5所示,每个进程都有自己的连接套接字,HTTP请求通过这个连接套接字接收,HTTP响应通过这个连接套接字发送。然而,我们提到,连接套接字和进程之间并不总是一对一的对应关系。事实上,今天的高性能Web服务器通常只使用一个进程,并为每个新的客户端连接创建一个带有新连接套接字的新线程。(线程可以被看作是轻量级的子进程。)如果您在第2章中完成了第一个编程任务,那么您就构建了一个Web服务器来完成这个任务。对于这样的服务器,在任何给定的时间都可能有许多连接套接字(具有不同的标识符)附加到同一个进程上。
如果客户端和服务器使用持久HTTP,那么在整个持久连接期间,客户端和服务器通过相同的服务器套接字交换HTTP消息。然而,如果客户端和服务器使用非持久HTTP,则会为每个请求/响应创建和关闭一个新的TCP连接,因此会为每个请求/响应创建一个新的套接字,然后关闭。频繁创建和关闭套接字会严重影响繁忙的Web服务器的性能(尽管可以使用许多操作系统技巧来缓解这个问题)。对于围绕持久和非持久HTTP的操作系统问题感兴趣的读者可以看看[Nielsen 1997;Nahum2002]。
既然我们已经讨论了传输层多路复用和解复用,让我们继续讨论互联网的传输协议之一UDP。在下一节中,我们将看到UDP对网络层协议的贡献比多路复用/解复用服务少得多。
3.3 无连接传输:UDP
在本节中,我们将细看UDP,它是如何工作的,以及它做什么。我们鼓励您回顾2.1节,其中包括UDP服务模型的概述,以及2.7.1节,其中讨论了使用UDP的套接字编程。
为了激发我们对UDP的讨论,假设您对设计一个简单、基本的传输协议感兴趣。你会怎么做呢?您可能首先考虑使用一个没什么卵用的(vacuous)传输协议。特别是,在发送方,您可以考虑从应用程序进程中获取消息,并将它们直接交付给网络层;在接收方,您可以考虑接收来自网络层的消息,并将它们直接交付给应用程序进程。但是,正如我们在前一节中所学到的,我们必须多做些!至少,传输层必须提供多路复用/解复用服务,以便在网络层和正确的应用程序级进程之间传递数据。
UDP,在[RFC768]中定义,基本上能做一个传输协议所能做的事。除了多路复用/解复用功能和一些轻微的错误检查,它没有添加任何东西到IP。事实上,如果应用程序开发人员选择UDP而不是TCP,那么应用程序几乎是直接与IP通信。UDP从应用程序进程中获取消息,附加源端口号和目标端口号字段用于多路复用/解复用服务,添加另外两个小字段,并将结果段交付给网络层。网络层将传输层段封装成IP数据报,然后尽最大努力将段发送给接收主机。如果段到达接收主机,UDP使用目标端口号将段的数据交付给正确的应用程序进程。注意,使用UDP,在发送段之前,发送和接收传输层实体之间没有握手。因此,UDP被认为是无连接的。
DNS是典型使用UDP的应用层协议的一个例子。当主机中的DNS应用程序想要进行查询时,它会构造一个DNS查询消息,并将该消息交付给UDP。在不与目标端系统上运行的UDP实体进行任何握手的情况下,主机端UDP向消息中添加头字段,并将结果段交付给网络层。网络层将UDP段封装成一个数据报,并将该数据报发送到名称服务器(name server)。然后,查询主机上的DNS应用程序等待对其查询的应答。如果它没有接收到应答(可能是因为底层网络丢失了查询或应答),它可能尝试重新发送查询,尝试将查询发送到另一个名称服务器,或者通知调用应用程序它无法获得应答。
现在您可能想知道为什么应用程序开发人员会选择基于UDP而不是TCP构建应用程序。难道TCP不好吗?因为TCP提供可靠的数据传输服务,而UDP不?答案是否定的,因为一些应用程序更适合UDP,原因如下:
对发送什么数据和何时发送数据的应用程序有更精细的控制 在UDP下,一旦有一个应用程序进程将数据交付给UDP, UDP将打包数据到UDP段,并立即将该段交付给网络层。另一方面,TCP有一种拥塞控制机制,当源主机和目标主机之间的一条或多条链路过度拥塞时,该机制可以抑制传输层TCP发送方。TCP也将继续重新发送段,直到接收段被目的地确认,无论可靠的传输需要多长时间。由于实时应用程序通常要求最小的发送速率,不希望过度延迟段传输,并且能够容忍一些数据丢失,TCP的服务模型并不能很好地满足这些应用程序的需求。正如下面所讨论的,这些应用程序可以使用UDP来实现。
没有连接建立 我们将在后面讨论,TCP在开始传输数据之前使用三次握手。而UDP在没有任何正式预备的情况下直接传输数据。因此,UDP不引入任何延迟来建立连接。这可能是DNS运行在UDP上而不是TCP上的主要原因,如果它运行在TCP上,DNS会慢得多。HTTP使用TCP而不是UDP,因为可靠性对于带有文本的Web页面至关重要。但是,正如我们在第2.2节中简要讨论的那样,HTTP中的TCP连接建立延迟是与下载Web文档相关的延迟的一个重要因素。事实上,在谷歌的Chrome浏览器中使用的QUIC协议(Quick UDP Internet Connection, [IETF QUIC 2020]),该协议使用UDP作为其底层传输协议,并在UDP之上实现了应用层协议的可靠性。我们将在第3.8节中进一步研究QUIC。
无连接状态 TCP维护终端系统间的连接状态。这种连接状态包括接收和发送缓冲区、拥塞控制参数、序列和确认号参数。我们将在3.5节中看到,这个状态信息是实现TCP可靠的数据传输服务和提供拥塞控制所需要的。另一方面,UDP不维护连接状态,也不跟踪这些参数。由于这个原因,当应用程序运行在UDP而不是TCP上时,专用于特定应用程序的服务器通常可以支持更多的活动客户端。
更小的数据包头开销 TCP的每个段有20字节的头开销,而UDP只有8字节的开销。
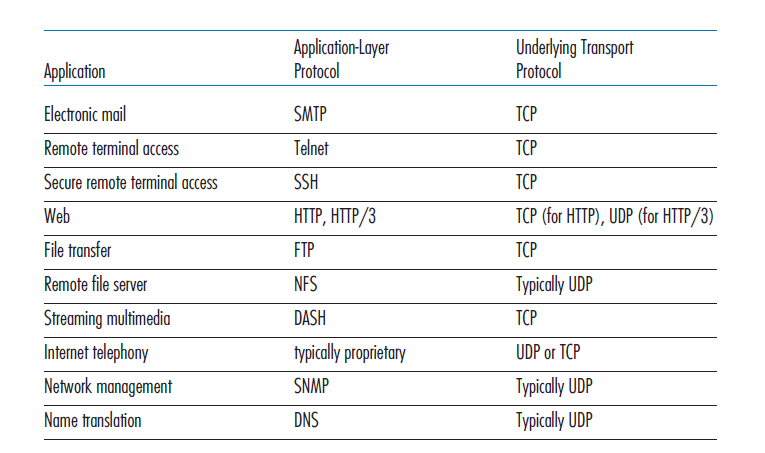
图3.6列出了流行的Internet应用程序和它们使用的传输协议。正如我们所预料的那样,电子邮件、远程终端访问和文件传输都需要TCP提供可靠的数据传输服务。我们在第2章中了解到,早期版本的HTTP运行在TCP上,而最新版本的HTTP运行在UDP上,在应用层提供了自己的错误控制和拥塞控制(以及其他服务)。然而,许多重要的应用程序运行在UDP而不是TCP上。例如,使用UDP承载网络管理(SNMP;参见5.7节)数据。在这种情况下,UDP优先于TCP,因为网络管理应用程序通常必须在网络处于高压状态下运行——可靠且精准,拥塞控制的数据传输是难以实现的。此外,正如我们前面提到的,DNS在UDP上运行,从而避免了TCP建立连接的延迟。
如图3.6所示,UDP和TCP现在有时都被用于多媒体应用程序,如互联网电话、实时视频会议和存储的音频和视频流。我们刚才提到,所有这些应用程序都可以容忍少量的丢包,因此可靠的数据传输对应用程序的成功不是绝对关键的。此外,实时应用,如网络电话和视频会议,对TCP的拥塞控制反应非常差。由于这些原因,多媒体应用程序的开发人员可能会选择在UDP而不是TCP上运行他们的应用程序。受一些组织出于安全原因而阻塞UDP流量的影响(见第8章),TCP成为流媒体传输中越来越有吸引力的协议。
虽然现在已经很普遍了,但在UDP上运行多媒体应用程序需要非常小心。正如我们上面提到的,UDP没有拥塞控制。但是需要拥塞控制来防止网络进入拥塞状态,在这种状态下,几乎没有什么有用的工作被完成。如果每个人都在不使用任何拥塞控制的情况下开始流媒体的高比特率视频,那么路由器上就会出现大量的数据包溢出,以至于很少有UDP数据包能够成功地通过源到目标的路径。此外,不受控制的UDP发送方导致的高丢包率将导致TCP发送方(我们将看到,在拥塞面前确实降低了它们的发送速率)急剧降低它们的速率。因此,UDP拥塞控制的缺乏会导致UDP发送方和接收方之间的高丢包率,以及TCP会话的拥挤。许多研究人员提出了新的机制来迫使所有的源,包括UDP源,执行自适应拥塞控制[Mahdavi 1997;Floyd 2000年;Kohler 2006: RFC 4340]。
在讨论UDP段结构之前,我们提到,当使用UDP时,应用程序可以有可靠的数据传输。如果将可靠性构建到应用程序本身中(例如,通过添加确认和重传机制,我们将在下一节中研究这些机制),就可以做到这一点。我们在前面提到过,QUIC协议在UDP之上的应用层协议中实现了可靠性。但这是一项非同小可的任务,会让应用程序开发人员花很长时间忙于调试。然而,将可靠性直接构建到应用程序中,可以让应用程序“鱼与熊掌兼得”。也就是说,应用程序进程可以可靠地通信,而不受TCP拥塞控制机制所施加的传输速率约束。
3.3.1 UDP段结构
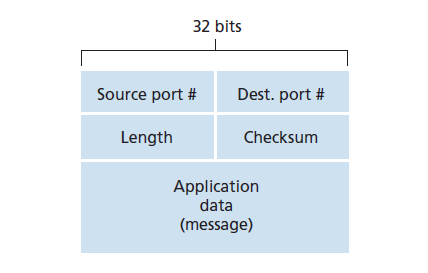
UDP的段结构,如图3.7所示,在RFC768中定义。应用数据占用了UDP段的data字段。例如,对于DNS,data字段包含查询消息或响应消息。对于音频应用程序,音频采样填充data字段。UDP头只有四个字段,每个字段由两个字节组成。如前一节所讨论的,端口号允许目标主机将应用程序数据交付给在目标端系统上运行的正确进程(即执行解复用功能)。Length字段指定UDP段(头加上data)中的字节数。一个显式的长度值是需要的,因为一个UDP段的data字段的大小可能不同于下一个。接收主机使用校验和(checksum)来检查段中是否引入了错误。事实上,除了UDP段外,校验和也在IP头中的一些字段上计算。但我们忽略了这个细节,以便透过树木看到整个森林。我们将在下面讨论校验和计算。错误检测的基本原理在第6.2节中描述。
UDP 校验和
UDP校验和提供了错误检测功能。也就是说,校验和用来确定UDP段中的比特在从源到目标移动时是否被改变了(例如,由于链路中的噪声或存储在路由器中)。
UDP在发送方执行段中所有16 bit字(word)的的1补和(1s complement)运算,上位溢出时循环进位(即高位溢出,在低位加上1)。这个结果被放在UDP段的校验和字段中。这里我们给出了一个简单的校验和计算的例子。你可以在RFC 1071中找到关于计算的高效实现细节,还有[Stone 1998;Stone 2000]。例如,假设我们有以下三个16 bit的词:
0110011001100000
0101010101010101
1000111100001100其前两个16 bit字和是:
0110011001100000
0101010101010101
————————————————
1011101110110101加上第三个:
1011101110110101
1000111100001100
————————————————
0100101011000010请注意,最后加的内容有溢出,执行了 循环进位 。补码是将所有的0转换为1,再将所有的1转换为0得到的。因此,和0100101011000010的1补码是1011010100111101,这就变成了校验和。在接收方,所有四个16 bit字都被添加进去,包括校验和。如果数据包中没有引入错误,那么接收方收到的数据和将是111111111111111111。如果其中一个位是0,那么我们就知道错误已经引入到了数据包中。
您可能想知道为什么UDP首先提供校验和,因为许多链路层协议(包括流行的以太网协议)也提供错误检查。原因是不能保证源和目标之间的所有链路都提供错误检查;也就是说,其中一个链路可能使用不提供错误检查的链路层协议。此外,即使段在链路上正确地传输,当段存储在路由器的内存中时,也有可能引入比特错误。链路到链路的可靠性和内存中的错误检测都得不到保证,如果端到端数据传输服务要提供错误检测,UDP必须在端到端基础上在传输层提供错误检测。这是系统设计中著名的 端到端原则 的一个例子[Saltzer 1984],它指出,由于某些功能(在这种情况下,错误检测)必须在端到端基础上实现:“与在较高一级提供这些职务的开销相比,设在较低一级的职务可能是多余的或没有多大价值的。“
因为IP应该在任何第二层协议上运行,所以对于传输层来说,提供错误检查作为一种安全措施是很有用的。虽然UDP提供了错误检查,但它不做任何事情来从错误中恢复。UDP的一些实现简单地丢弃损坏的段;其他程序则将损坏的段交付给应用程序并发出警告。
这就结束了我们对UDP的讨论。我们很快就会看到TCP为它的应用程序提供可靠的数据传输,以及UDP不能提供的其他服务。当然,TCP也比UDP复杂。不过,在讨论TCP之前,我们最好先回顾一下可靠数据传输的基本原理。
3.4 可靠数据传输原理
在这一节中,我们将在一般的环境中探讨可靠数据传输的问题。这是恰当的,因为实现可靠数据传输的问题不仅发生在传输层,而且也发生在链路层和应用层。因此,这个普遍问题对网络来说非常重要。的确,如果要找出所有网络中最重要的十大问题,那么这个问题应该是最重要的。在下一节中,我们将检查TCP,并特别说明TCP利用了我们将要描述的许多原则。
图3.8说明了我们研究可靠数据传输的框架。提供给上层实体的服务抽象是一个可靠的通道,通过它可以传输数据。有了可靠的通道,传输的数据位不会被损坏(从0翻转到1,或反之)或丢失,所有的数据都按照发送的顺序发送。这正是TCP向调用它的Internet应用程序提供的服务模型。
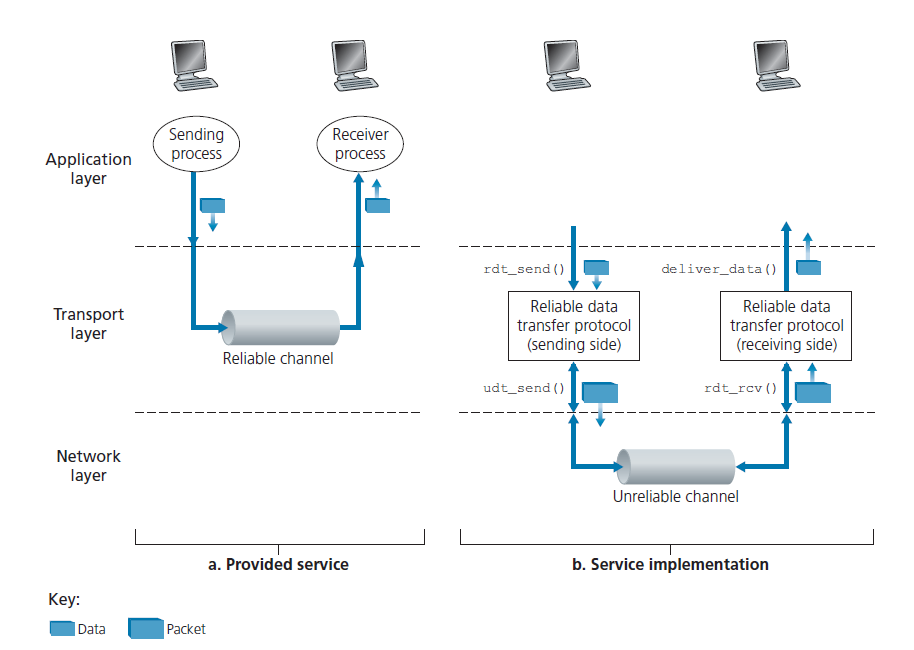
可靠数据传输协议 负责实现这个服务抽象。由于可靠数据传输协议下面的层可能是不可靠的,这一任务变得困难。例如,TCP是一种可靠的数据传输协议,在不可靠的(IP)端到端网络层上实现。一般来说,两个可靠通信端点下面的层可能由单个物理链路(如在链路级数据传输协议中)或全局互连网(如在传输级协议中)组成。然而,出于我们的目的,我们可以将这个较低的层简单地看作是一个不可靠的点对点通道。
在本节中,考虑到底层信道(chanel)日益复杂的模型,我们将渐进式(incrementally)地开发可靠数据传输协议的发送方和接收方。例如,我们将考虑当底层信道可能损坏比特或丢失整个数据包时需要什么协议机制。在整个讨论过程中,我们将采用的一个假设是,数据包将按照发送的顺序发送,其中一些数据包可能会丢失;也就是说,底层信道不会重新排序数据包。图3.8(b)说明了我们的数据传输协议的接口。数据传输协议的发送方将通过调用rdt_send()从上面唤起。它将要传送的数据交付给接收方上层。(此处rdt表示reliable data transfer,_send表示rdt发送方正在被调用。开发任何协议的第一步都是选择一个好名字!)在接收方,当一个数据包从信道接收方到达时,rdt_rcv()将被调用。当rdt协议希望向上层交付数据时,它将通过调用deliver_data()来实现。在下面的文章中,我们使用术语数据包(packet)而不是传输层段。由于本节中发展的理论一般适用于计算机网络,而不仅仅适用于Internet传输层,所以通用术语数据包在这里可能更合适。
在本节中,我们只考虑单向数据传输的情况,即数据从发送方传输到接收方。可靠的双向(即全双工)数据传输在概念上并不困难,但解释起来却相当繁琐。虽然我们只考虑单向数据传输,但需要注意的是,我们协议的发送和接收方仍然需要在两个方向上传输数据包,如图3.8所示。我们很快就会看到,除了交换包含要传输的数据的数据包之外,rdt的发送方和接收方还需要交换控制数据包的来往。rdt的发送方和接收方都通过调用udt_send()将数据包发送到另一端。
3.4.1 建立可靠的数据传输协议
现在,我们逐步了解一系列协议,每一个协议都变得更加复杂,最终得到一个完美的、可靠的数据传输协议。
完美可靠信道之上的可靠数据传输:rtd1.0
我们首先考虑最简单的情况,在这种情况下,底层信道是完全可靠的。协议本身(我们称之为rdt1.0)很简单。rdt1.0发送方和接收方的有限状态机(FSM)定义如图3.9所示。图3.9(a)中的FSM定义发送方的操作,图3.9(b)中的FSM定义接收方的操作。重要的是要注意,发送方和接收方有独立的FSM。图3.9中的发送方和接收方FSM都只有一个状态。FSM描述中的箭头表示协议从一种状态到另一种状态的转换。(因为图3.9中的每个FSM只有一个状态,所以必须从一个状态转换回自身;我们将很快看到更复杂的状态图。)导致转换的事件显示在标记转换的水平线之上,而事件发生时所采取的操作显示在水平线之下。当事件没有采取任何操作,或者事件没有发生而采取了某个操作时,我们将使用符号Λ分别在水平线下或水平线上,以明确表示缺少动作或事件。虚线箭头表示FSM的初始状态。尽管图3.9中的FSM只有一个状态,但是我们很快就会看到FSMs有多个状态,所以识别每个FSM的初始状态是很重要的。
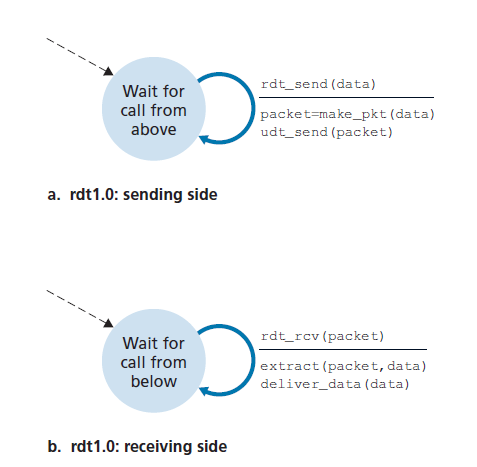
rdt的发送方通过rdt_send(data)事件接收来自上层的数据,创建包含数据的数据包(通过动作make_pkt(data)),并将数据包发送到信道中。实际上,rdt_send(data)事件是由上层应用程序的过程调用(procedure call,如rdt_send())产生的。
在接收方,rdt通过rdt_rcv(packet)事件从底层信道接收一个数据包,从数据包中迁移数据(通过动作extract(packet, data)),并将数据交付给上层(通过动作\deliver_data(data))。在实践中,rdt_rcv(packet)事件是由底层协议的过程调用(例如rdt_rcv())引起的。
在这个简单的协议中,数据单位和数据包之间没有区别。同时,所有数据包流都是从发送方到接收方;有了一个完全可靠的信道,接收方就不需要向发送方提供任何反馈,因为不会出错!注意,我们还假设接收方接收数据的速度与发送方发送数据的速度一样快。因此,接收方不需要要求发送方放慢速度。
在有比特错误信道之上的可靠数据传输:rtd2.0
一个更现实的底层信道模型是一个数据包中的比特可能被损坏的信道。这种比特错误通常发生在数据包传输、传播或缓冲时网络的物理组件中。我们暂时将继续假设所有传输的数据包都按照发送的顺序被接收(尽管它们的比特可能被损坏)。
在开发通过这种信道进行可靠通信的协议之前,首先考虑人们可能如何处理这种情况。考虑一下你自己如何在电话中口述一条很长的信息。在一个典型的场景中,信息接受者可能会在每个句子被听到、理解和录音后说OK。如果对方听到了错误的句子,你就得重复一遍。这个口述消息协议使用 正向确认(positive acknowledgments) 和 负向确认(negative acknowledgments) 。这些控制消息允许接收方让发送方知道哪些信息被正确接收,哪些信息被错误接收,因此需要重复接收。在计算机网络设置中,基于这种重传的可靠数据传输协议称为 ARQ(Automatic Repeat reQuest) 协议。
基本上,在ARQ协议中需要三个额外的协议功能来处理比特错误的存在:
错误检测 首先,需要一种机制来允许接收方检测何时发生了比特错误。回想上一节,UDP使用Internet校验和字段正是为了这个目的。在第六章中,我们将更详细地探讨错误检测和校正技术;这些技术允许接收方检测并纠正数据包的比特错误。现在,我们只需要知道这些技术要求额外的比特(原始数据要传输的比特以外)从发送方发送到接收方;这些比特将被收集到rdt2.0数据包的数据包校验和字段中。
接收方反馈(Receiver feedback) 由于发送方和接收方通常是执行在不同的终端系统,可能相隔数千英里,发送方的唯一获悉接收方接收数据包是否正确的方法是接收方提供显式确认给发送方。信息口述(message-dictation)情景中,正向确认(ACK)和负向确认(NAK)就是这种反馈的例子。我们的rdt2.0协议将类似地将ACK和NAK数据包从接收方发送回发送方。原则上,这些数据包只需要一个比特那么长;例如,0值可以表示NAK, 1值可以表示ACK。
重传 在接收方接收到的数据包错误时将由发送方重传。
图3.10展示了rdt2.0的FSM表示形式,rdt2.0是一种使用错误检测、正向确认和负向确认的数据传输协议。
rdt2.0的发送方有两种状态。在最左边的状态下,发送方协议等待数据从上层传递下来。当rdt_send(data)事件发生时,发送方将创建一个包含要发送的数据,校验和的数据包(sndpkt)(例如,在章节3.3.2中讨论的UDP段的情况),然后通过udt_send(sndpkt)操作发送数据包。在最右边的状态下,发送方协议等待接收方的ACK或NAK数据包。如果接收到ACK数据包(图3.10中的rdt_rcv(rcvpkt) && isACK(rcvpkt)对应此事件),则发送方知道最近发送的数据包已经被正确接收到,因此协议返回到等待上层数据的状态。如果接收到一个NAK,协议将重新发送上一个数据包,并等待接收方返回一个ACK或NAK作为对重传数据包的响应。需要注意的是,当发送方处于wait-for-ACK-or-NAK状态时,无法从上层获取更多数据;即rdt_send()事件不能发生;这只会发生在发送方收到ACK并离开这个状态之后。因此,发送方在确定接收方已正确接收到当前数据包之前,不会发送新的数据。由于这种行为,像rdt2.0这样的协议被称为 停等(stop-and-wait)协议 。
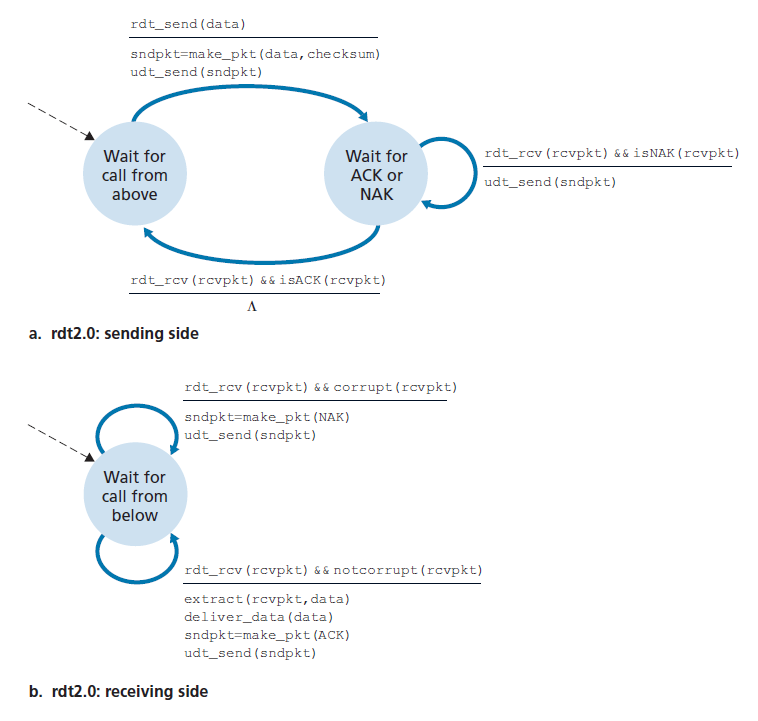
rdt2.0的接收方FSM仍然只有一个状态。在数据包到达时,接收方根据收到的数据包是否损坏,用ACK或NAK进行应答。在图3.10中,rdt_rcv(rcvpkt) &&Corrupt (rcvpkt)对应的事件是接收到一个数据包并发现它是错误的。
协议rdt2.0看起来似乎可行,但不幸的是,它有一个致命的缺陷。特别是,我们还没有考虑到ACK或NAK数据包可能被破坏的可能性!(在继续之前,您应该考虑如何解决这个问题。)不幸的是,我们的小小疏忽并不像看起来那样无害。最低限度,我们将需要向ACK/NAK数据包添加校验和位来检测此类错误。更困难的问题是协议应该如何从ACK或NAK数据包的错误中恢复。这里的困难在于,如果ACK或NAK被损坏,发送方无法知道接收方是否正确地接收了上一段传输的数据。
考虑处理已损坏的ACK或NAK的三种可能性:
对于第一种可能性,考虑在消息口述场景中人类可能会做什么。如果说话人听不懂对方的OK或“你再说一遍”,说话人可能会问:“你说了什么?”(从而为我们的协议引入了一种新型的发送方到接收方数据包)。然后接收者会重复回复。但是如果说话人说“你说了什么?”损坏吗?听者不知道这个乱说的句子是口述的一部分,还是要求重复上一个回答,可能会回答“你说了什么?”当然,这种反应可能会被曲解。显然,我们正走在一条艰难的道路上。
第二种方法是添加足够的校验和位,这样发送方不仅可以检测到比特错误,还可以从比特错误中恢复过来。这直接解决了信道可能破坏数据包但不会丢包的问题。
第三种方法是,发送方在收到错误的ACK或NAK数据包时,简单地重新发送当前数据包。然而,这种方法会在发送方到接收方信道中引入 重复的数据包 。重复数据包的根本困难在于接收方不知道它上一次发送的ACK或NAK是否被发送方正确接收。因此,它不能预先知道到达的数据包是否包含新数据或重传数据。
这个新问题的一个简单解决方案(几乎所有现有的数据传输协议都采用了这个方案,包括TCP)是在数据包中添加一个新字段,并通过在这个字段中输入 序列号 来让发送方为它的数据包编号。然后,接收方只需要检查这个序列号,以确定接收到的数据包是否为重传。对于这个简单的停等协议,一个1位的序列号就足够了,因为它允许接收方知道发送方是在重发之前发送的数据包(收到的数据包的序列号和最近收到的数据包的序列号相同)还是一个新的数据包(序列号改变了,在modulo-2算法中“向前”移动)。由于我们目前假设信道不会丢失数据包,所以ACK和NAK数据包本身不需要指出它们正在确认的数据包的序列号。发送方知道接收到的ACK或NAK数据包(不管是否被篡改)是对其最近发送的数据包的响应。
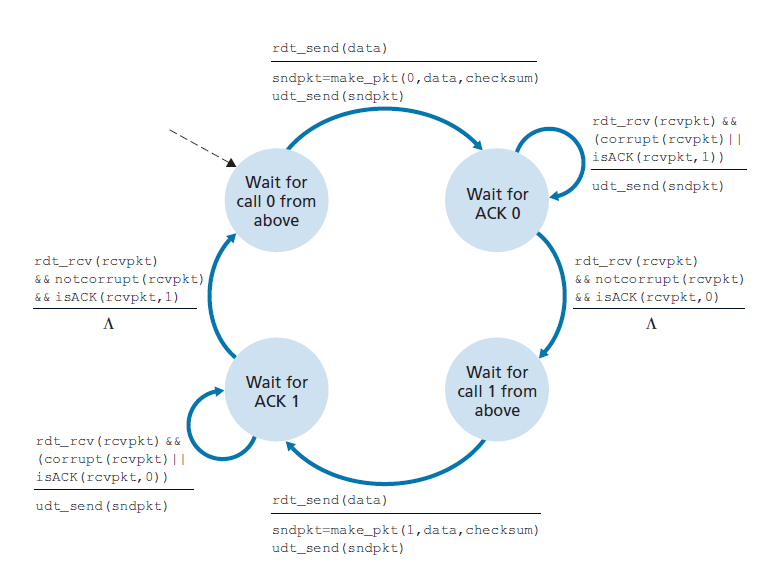
图3.11和3.12显示了rdt2.1的FSM描述,rdt2.0的修复版本。rdt2.1发送方和接收方FSM的状态数现在都是以前的两倍。这是因为协议状态现在必须反映当前(由发送方)发送的或预期(在接收方)发送的数据包的序列号是0还是1。请注意,发送或预期编号0的数据包的状态与发送或预期编号1的数据包的状态是镜像关系;唯一的区别在于序列号的处理。
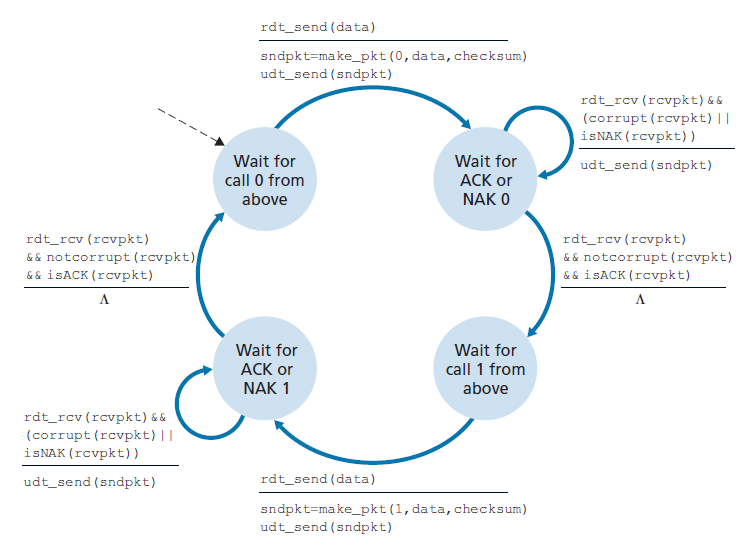
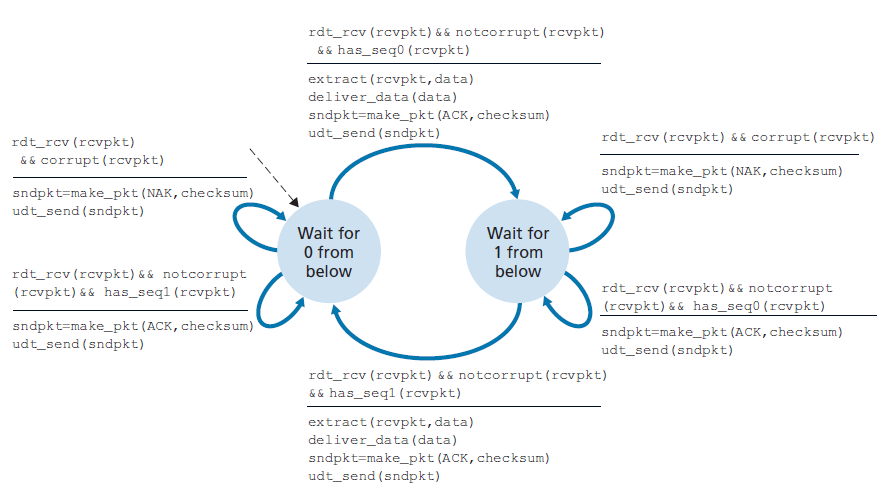
协议rdt2.1使用了从接收方到发送方的正向确认和负向确认。当接收到一个无序数据包时,接收方对它所接收到的数据包发送一个正向确认。当接收到一个损坏的数据包时,接收方发送一个负向确认。我们可以实现与NAK相同的效果,即不发送NAK,而是为上一个正确接收的数据包发送一个ACK。对于同一个数据包,发送方收到两个ACK(即收到重复的ACK),则知道接收方没有正确地接收到跟随在被两次ACK的数据包之后的数据包。对于存在比特错误的信道,我们的NAK-free可靠数据传输协议是rdt2.2,如图3.13和3.14所示。rtdt2.1和rdt2.2之间的一个微妙的变化是,接收方现在必须包含被ACK消息确认的数据包的序列号(这是通过在接收方FSM的make_pkt()中包含ACK, 0或ACK, 1参数来完成的),发送方现在必须检查接收到的ACK消息确认的数据包的序列号(这是通过在发送方FSM的isACK()中包含0或1参数来完成的)。
在有丢包和比特错误的信道上的可靠数据传输:rtd:3.0
假设现在除了损坏比特之外,底层信道还可能丢失数据包,这在当今的计算机网络(包括Internet)中并不罕见。协议现在必须解决另外两个问题:如何检测数据包丢失以及当数据包丢失发生时该做什么。使用校验和、序列号、ACK数据包和重传——rdt2.2中已经开发的技术将使我们能够回答后一个问题。处理第一个问题需要添加一个新的协议机制。
处理数据包丢失有许多可能的方法(本章末尾的练习中讨论了更多的方法)。在这里,我们将把检测和恢复丢失数据包的任务交给发送方。假设发送方发送了一个数据包,而这个数据包或者这个数据包的接收方的ACK丢失了。在这两种情况下,发送方都不会收到接收方的回复。如果发送方愿意等待足够长的时间,以确定数据包已经丢失,它可以简单地重新发送数据包。您应该说服自己这个协议确实有效。
但是发送方要等多久才能确定丢失了什么东西呢?显然,发送方必须至少等待发送方和接收方之间的往返延迟(可能包括中间路由器的缓冲延迟)以及接收方处理一个数据包所需的时间。在许多网络中,这种最坏情况下的最大延迟甚至很难估计,更不用说确切地知道了。此外,理想情况下,协议应尽快从丢包中恢复;等待最坏情况下的延迟可能意味着很长时间的等待,直到启动错误恢复。因此,在实践中采用的方法是,发送方明智地选择一个时间值,期间很可能(尽管不能保证)发生丢包。如果在这个时间内没有收到ACK,则数据包将被重传。请注意,如果一个数据包经历了特别大的延迟,发送方可以重新发送数据包,即使数据包和它的ACK都没有丢失。这引入了发送方到接收方信道中重复数据包的可能性。令人高兴的是,rdt2.2协议已经有足够的功能(即序列号)来处理重复的包。
从发送方的观点来看,重传是一种灵丹妙药。发送方不知道数据包是否丢失,ACK是否丢失,或者数据包或ACK是否只是过度延迟。在所有情况下,操作都是相同的:重新发送。实现基于时间的重传机制需要一个倒计时计时器,它可以在给定的时间过期后中断发送方。因此,发送方需要能够(1)每次发送一个数据包(无论是第一次发送还是重传)时启动定时器,(2)响应一个定时器中断(采取适当的行动),(3)停止定时器。
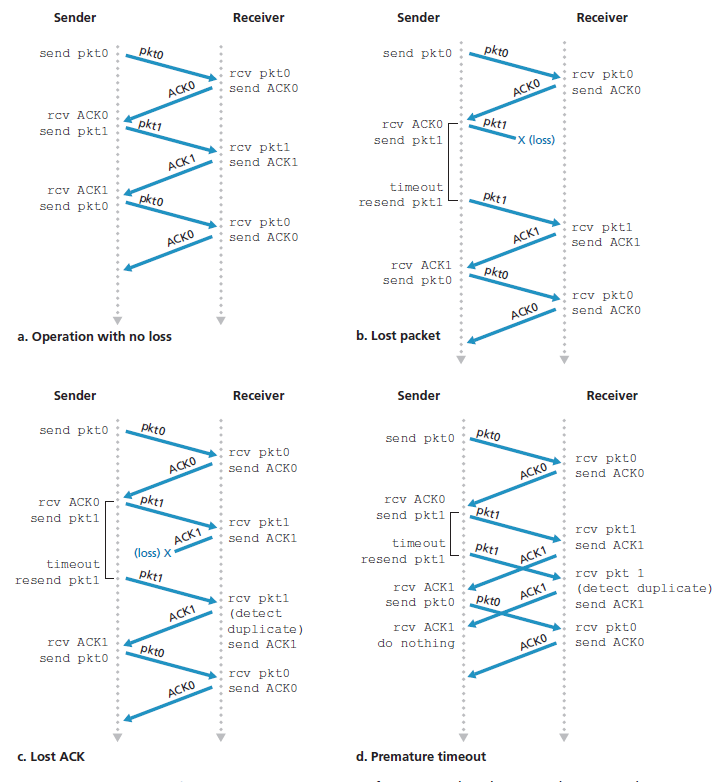
图3.15显示了rdt3.0的发送方FSM, rdt3.0是一种在可能损坏或丢失数据包的信道上的可靠数据传输协议;在作业问题中,你会被要求提供rdt3.0的接收方FSM。图3.16显示了协议在没有丢失或延迟数据包的情况下是如何工作的,以及它如何处理丢失的数据包。在图3.16中,时间从图的顶部向前移动到图的底部;请注意,由于传输和传播延迟,数据包的接收时间必然要晚于数据包的发送时间。在图3.16(b) (d)中,发送方方括号表示超时。本章末尾的练习将探讨该协议的几个较微妙的方面。因为数据包序列号在0和1之间交替,协议rdt3.0有时被称为 比特交替协议(alternating-bit protocol) 。
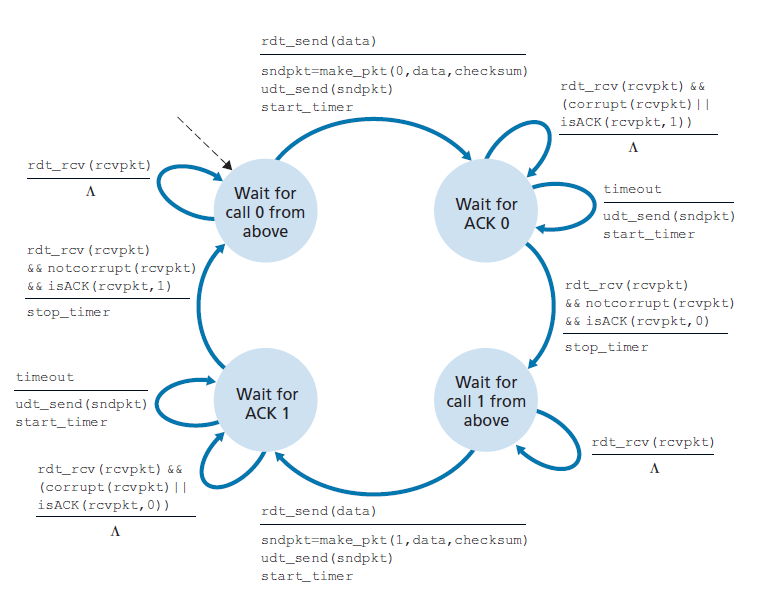
我们现在已经集齐了数据传输协议的关键要素。校验和、序列号、定时器以及正负确认数据包在协议的运行中都起着至关重要和必要的作用。我们现在有了一个工作可靠的数据传输协议!
管道化的可靠数据传输协议
rdt3.0协议在功能上是正确的协议,但它的性能不太可能让任何人满意,特别是在今天的高速网络中。rdt3.0性能问题的核心是它是一个停等协议。
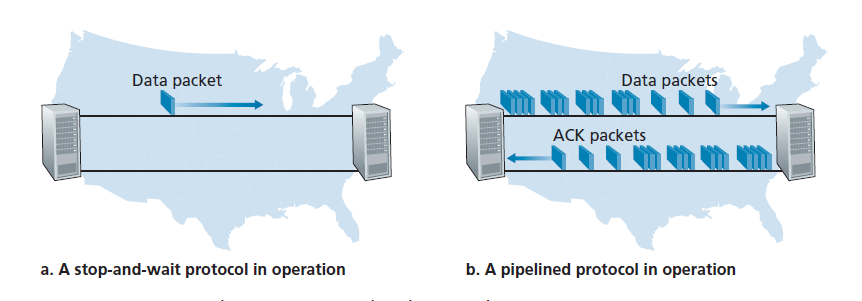
为了了解这种停止和等待行为的性能影响,考虑一个理想的情况,有两个主机,一个位于美国西海岸,另一个位于东海岸,如图3.17所示。这两个终端系统之间的光速往返传播延迟(RTT)大约是30毫秒。假设它们通过一个传输速率R为1gbps(每秒109比特)的信道连接。如果数据包的大小为L,每个数据包1,000字节(8,000比特),包括头字段和数据,则实际将数据包传输到1 Gbps链路所需的时间是:
dtrans = L/R = (8000 bits/ 10^9bits) /sec = 8 microseconds
图3.18(a)显示,在我们的停等协议中,如果发送方在t = 0时开始发送数据包,那么在t = L/R = 8微秒时,最后一个比特进入发送方的信道。然后数据包进行15毫秒的越野旅行,数据包的最后一个比特在t = RTT/2 + L/R = 15.008毫秒时出现在接收方。为简单起见假设ACK数据包是极其微小的(这样我们可以忽略它们的传输时间),接收方一旦收到数据包的最后一个比特就可以立即发送ACK,ACK在t = RTT + L / R = 30.008微秒回到发送方。此时,发送方可以发送下一条消息。因此,在30.008 msec中,发送方只发送了0.008 msec。如果我们将发送方(或信道)的利用率(utilization)定义为发送方实际忙于向信道发送比特的时间的比例,由图3.18(a)中的分析表明,停等协议的发送方利用率相当低。Usender,即:
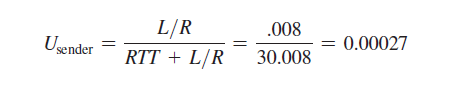
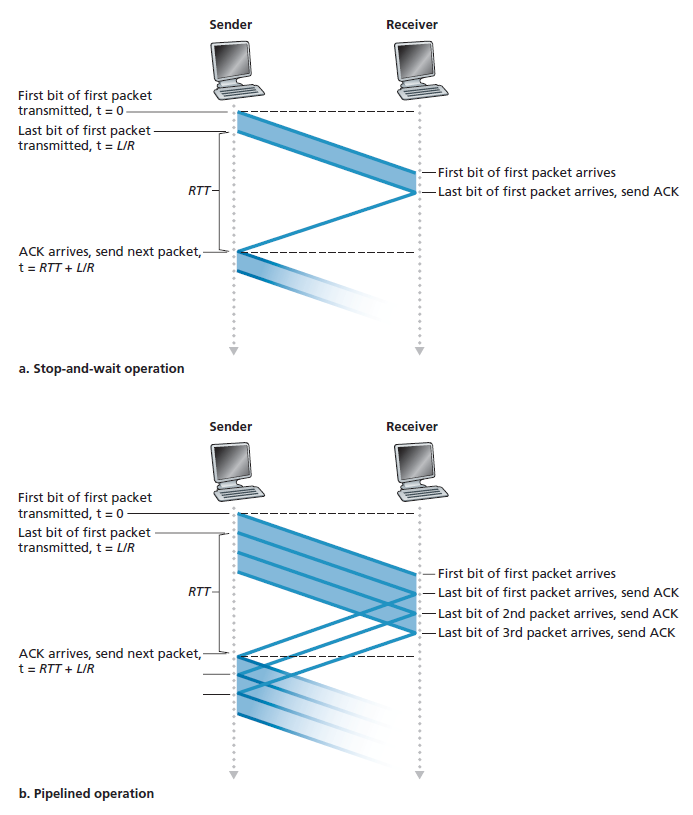
也就是说,发送方在万分之2.7的时间里忙活!从另一个角度来看,发送方能够在30.008毫秒内只发送1000字节,即使1 Gbps链路可用,有效吞吐量也只有267 kbps !想象一下,一个不高兴的网络经理刚刚花了一大笔钱购买了一个千兆容量的链路,却仅获得了只有267千比特每秒的吞吐量!这是一个网络协议如何限制底层网络硬件提供的功能的图形示例。此外,我们忽略了底层协议在发送方和接收方的处理时间,以及在发送方和接收方之间的任何中间路由器上可能发生的处理和排队延迟。包括这些影响只会进一步增加拖延和进一步加重不良的业绩。
这个特殊的性能问题的解决方案很简单:发送方被允许发送多个数据包而不等待确认,而不是以停止和等待的方式操作,如图3.17(b)所示。图3.18(b)显示,如果允许发送方在等待确认之前发送三个数据包,则发送方的利用率实质上是原来的三倍。由于许多传输中的发送方到接收方数据包可以被可视化为填充管道,因此这种技术被称为管道技术(pipelining)。管道对于可靠的数据传输协议有以下影响:
必须增加序列号的范围,因为每个在传输中的数据包(不计算重传)必须有一个唯一的序列号,并且可能有多个在传输中的、未确认的数据包。
协议的发送方和接收方可能必须缓冲多个数据包。至少,发送方必须缓冲已传输但尚未确认的数据包。在接收方也可能需要对正确接收到的数据包进行缓冲,如下所述。
所需的序列号范围和缓冲需求将取决于数据传输协议对丢失、损坏和过度延迟的数据包的响应方式。可以确定实现管道线错误恢复的两种基本方法: Go-BACK-N 和 选择性重复(selective repeat) 。
Go-BACK-N (GBN)
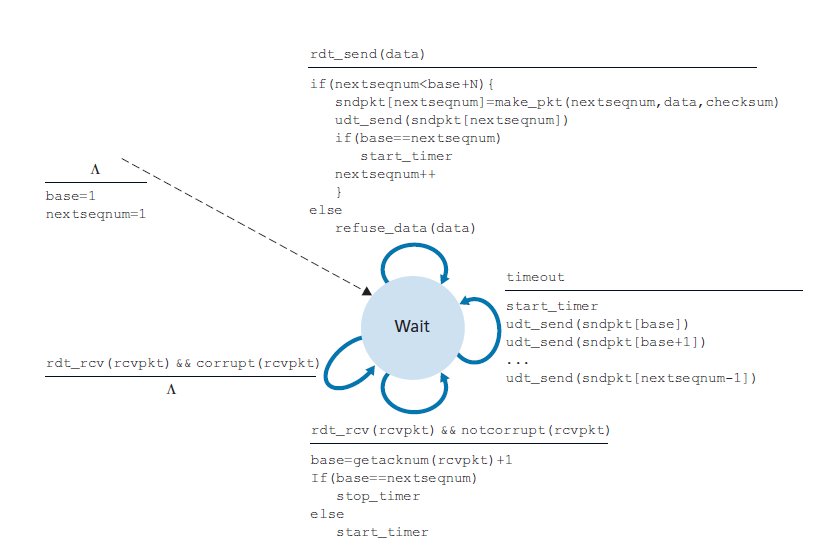
在 Go-BACK-N (GBN)协议 中,发送方被允许在不等待确认的情况下发送多个数据包(当可用时),但被限制在管道中不超过某个最大允许数N的未确认数据包。我们将在本节详细描述GBN协议。但是在继续阅读之前,建议您在配套的Web站点上玩一下GBN动画(一个很棒的交互式动画)。
图3.19显示了GBN协议中序列号范围的发送方视图。如果我们将base定义为最开始未确认数据包的序列号,将nextseqnum定义为最小的未使用的序列号(即下一个要发送的数据包的序列号),则可以在序列号范围内识别出四个区间。区间[0,base-1]的序列号对应的是已经发送并确认的数据包。 区间[base,nextseqnum-1]对应的是已经发送但尚未确认的数据包。如果数据从上层到达,对于能够立即发送的数据包,可以使用区间[nextseqnum,base+N-1]的序列号。最后,大于或等于base+N的序列号不能被使用,直到当前管道中的一个未被确认的数据包(具体地说,带有base序列号的数据包)被确认。
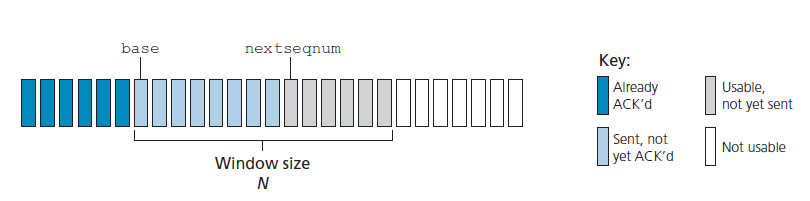
由图3.19可以看出,对于已发送但尚未确认的数据包,允许的序列号范围可以看作是序列号范围内大小为N的窗口。当协议运行时,该窗口在序列号空间上向前滑动。因此,N通常被称为 窗口大小 ,GBN协议本身称为 滑窗协议(sliding-window protocol) 。您可能想知道,为什么一开始我们甚至要将未处理的、未确认的数据包的数量限制为N。为什么不允许无限数量的这样的数据包呢?我们将在3.5节中看到,流量控制是对发送方施加限制的原因之一。我们将在3.7节研究TCP拥塞控制时研究这样做的另一个原因。
在实际应用中,数据包的序列号在数据包头的固定长度字段中携带。如果k是数据包序列号字段中的位数,则序列号的范围为[0,2k - 1]。对于有限范围的序列号,所有涉及序列号的算术运算必须使用modulo 2k算法来完成。(也就是说,序列号空间可以被认为是一个大小为2k的环,其中序列号2k - 1后面紧跟着序列号0。)回想一下,rdt3.0有一个1位的序列号其范围为[0,1]。本章末尾的几个问题探讨了序列号有限范围的影响。我们将在3.5节中看到,TCP有一个32 bit的序列号字段,其中TCP序列号计算字节流中的字节数,而不是数据包。
图3.20和3.21给出了基于ACK、NAK-free、GBN协议的发送方和接收方的扩展FSM描述。我们将此FSM描述称为扩展的FSM,因为我们为base和nextqnum添加了变量(类似于编程语言变量),并添加了对这些变量的操作和涉及这些变量的条件操作。注意,扩展的FSM规范现在开始看起来有点像编程语言规范。[Bochman 1984]提供了对FSM技术以及其他用于指定协议的基于编程语言的技术的额外扩展的出色调查。
GBN发送方必须响应三种类型的事件:
Invocation from above 当上面调用rdt_send()时,发送方首先检查窗口是否已满,也就是说,是否有N个未确认的数据包。如果窗口未满,则创建并发送一个数据包,并适当地更新变量。如果窗口已满,发送方只需将数据返回给上层,这是窗口已满的隐式指示。上层可能随后必须再试一次。在实际实现中,发送方更可能要么缓冲(但不是立即发送)这些数据,或将同步机制(例如,一个信号量(semaphore)或标记)在窗口未满时允许上层调用rdt_send()。
Receipt of an ACK 在我们的GBN协议中,对序列号为n的数据包的确认将被视为 累积确认(cumulative ACKnowledgment) ,表示接收方已正确接收到序列号为n的所有数据包。当我们探讨GBN的接收方时,我们将很快回到这个问题。
A timeout event 协议的名称“Go-BACK-N”是根据发送方在出现丢失或延迟过大的数据包时的行为而来的。与停等协议一样,计时器将再次用于从丢失的数据或确认数据包中恢复。如果超时发生,发送方将重新发送所有之前已经发送但尚未被确认的数据包。在图3.20中,我们的发送方只使用了一个计时器,它可以被认为是最开始发送的但尚未确认的数据包的计时器。如果接收到ACK,但仍有额外的传输了但尚未确认的数据包,则重新启动计时器。如果没有未完成的、未确认的数据包,则停止定时器。
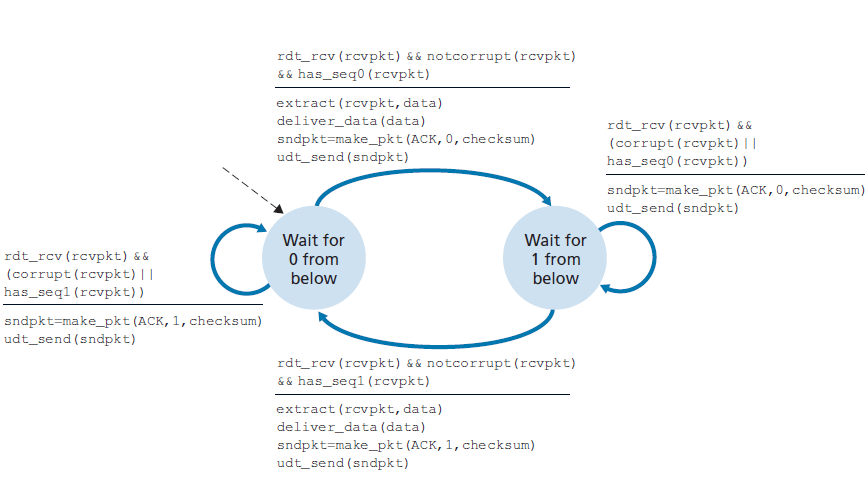
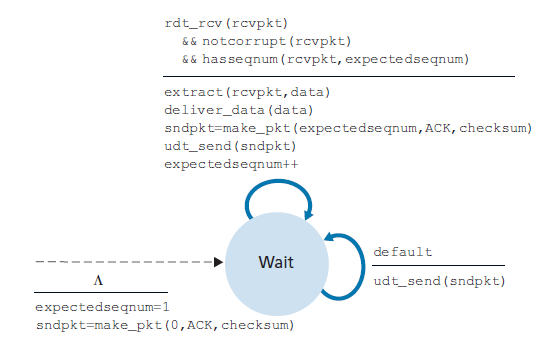
接收方在GBN中的动作也很简单。如果正确接收到一个序列号为n的数据包且有序(也就是说,上一次交付到上层的数据来自一个序列号为n - 1的数据包),接收方为数据包n发送ACK并把数据包的数据部分交付给上层。在所有其他情况下,接收方丢弃数据包,并为最近收到的有序的数据包重发一个ACK。注意,由于数据包一次只发送一个到上层,如果数据包k已经被接收和发送,那么序列号小于k的所有数据包也都被发送了。因此,使用累积确认是GBN的自然选择。
在我们的GBN协议中,接收方丢弃无序的数据包。尽管丢弃正确接收(但顺序不对)的数据包看起来很愚蠢和浪费,但这样做是有理由的。回想一下,接收方必须按照顺序向上层交付数据。假设现在需要数据包n,但是数据包n + 1到达了。因为数据必须按顺序交付,接收方可以缓冲(保存)数据包n + 1,在接收和交付数据包n之后,再向上层交付该数据包。然而,如果数据包n失去了,由于GBN发送方的重传规则,它和数据包n + 1最终将将被重传。因此,接收方可以直接丢弃数据包n + 1。这种方法的优点是接收方缓冲更轻松——接收方不需要缓冲任何无序的数据包。因此,当发送方必须维护其窗口的上下界和nextseqnum在该窗口中的位置时,接收方唯一需要维护的信息就是下一个有序数据包的序列号。这个值保存在变量expectedseqnum中,如图3.21中接收方FSM所示。当然,丢弃正确接收到的数据包的缺点是,该数据包随后的重传可能会丢失或失真,因此可能需要更多的重传。
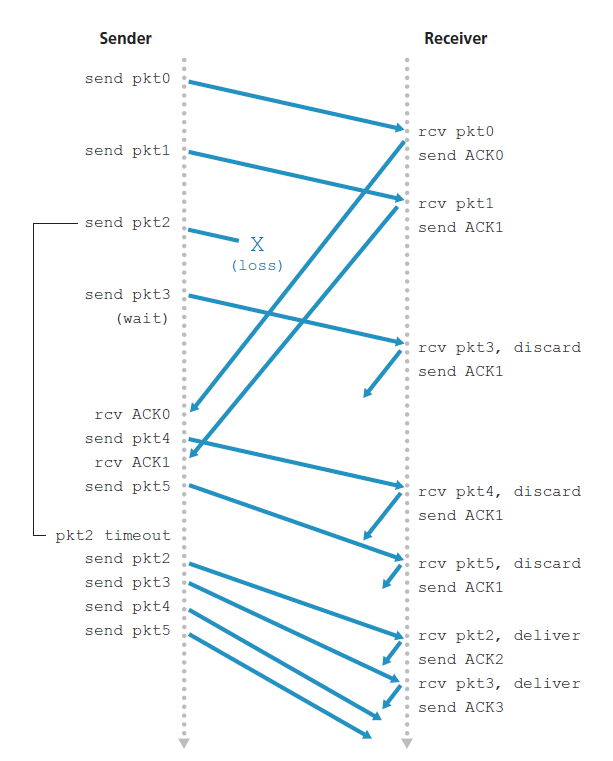
图3.22显示了GBN协议在窗口大小为4个数据包的情况下的操作。由于这个窗口大小限制,发送方发送数据包0到3,但是必须等待一个或多个数据包被确认后才能继续。当接收到每一个连续的ACK(例如,ACK0和ACK1)时,窗口向前滑动,发送方可以发送一个新的数据包(分别是pkt4和pkt5)。在接收方,数据包2丢失,从而发现数据包3、4、5出现故障而被丢弃。
在结束我们对GBN的讨论之前,值得注意的是,该协议在协议栈中的实现可能具有类似于图3.20中扩展的FSM的结构。实现也很可能采用各种程序的形式,这些程序实现对可能发生的各种事件所要采取的操作。在这种 基于事件的编程中(event-based programming) ,各种过程(procedure)要么被协议栈中的其他过程调用,要么作为中断的结果。在发送方中,这些事件包括:(1)上层实体调用rdt_send(),(2)定时器中断,(3)当一个数据包到达时下层实体调用rdt_rcv()。本章末尾的编程练习将让您有机会在模拟但真实的网络设置中实际实现这些例程。
我们在这里注意到,GBN协议包含了我们在第3.5节中研究TCP的可靠数据传输组件时将遇到的几乎所有技术。这些技术包括使用序列号、累积确认、校验和和超时/重传操作。
3.4.4选择性重复(SR)
GBN协议允许发送方在图3.17中潜在地用数据包填充管道,从而避免了我们在停等协议中注意到的信道利用问题。然而,在某些情况下,GBN本身也存在性能问题。特别是,当窗口大小和带宽延迟影响都很大时,可以有很多数据包在管道中。因此,单个数据包错误就会导致GBN重传大量的数据包,其中很多是不必要的。随着信道错误概率的增加,管道就会充满这些不必要的重传。想象一下,在口述消息的场景中,如果每次说错一个单词,那么就必须重复相关的1000个单词(例如,窗口大小为1000个单词)。口述会因为所有重复的单词而慢下来。
顾名思义,选择性重复协议通过让发送方只重传它怀疑在接收方错误接收(即丢失或损坏)的数据包来避免不必要的重传。这个单独的,根据需要的,重传将要求接收方单独确认正确收到的数据包。窗口大小为N将再次用于限制管道中未确认的、未处理的数据包的数量。然而,与GBN不同的是,发送方在窗口中已经收到了一些数据包的ACK。图3.23显示了序列号空间的SR发送方视图。
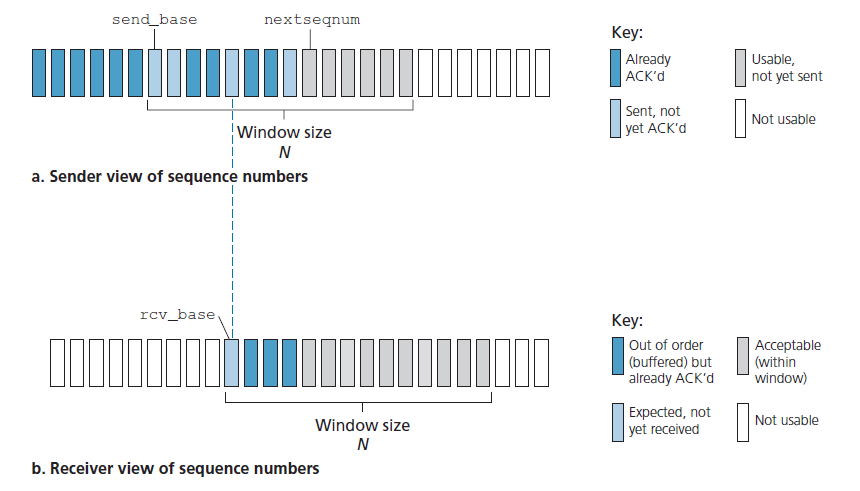
SR发送方所采取的各种行动:
- Data received from above 当从上面接收到数据时,SR发送方检查数据包的下一个可用序列号。如果序列号在发送方的窗口内,则数据被分组(packetized)并发送;否则,它要么被缓冲,要么同随后的传输返回到上层,就像在GBN中一样。
- Timeout 定时器再次被用来防止数据包丢失。但是,每个数据包现在必须有自己的逻辑计时器,因为在超时时只有一个数据包被传输。一个硬件计时器可以用来模拟多个逻辑计时器的操作[Varghese 1997]。
- ACK received 如果接收到ACK,则SR发送方将该数据包标记为已接收,前提是它在窗口中。如果数据包的序列号等于send_base,则窗口的base将被移动到序列号最小的未确认的数据包。如果窗口移动了,并且现在有序列号在窗口内的未传输数据包,则会传输这些数据包。
无论是否有序,SR接收方都将确认正确接收到的数据包。乱序的数据包将被缓冲,直到收到任何丢失的数据包(即序列号较低的数据包),此时可以按顺序将一批数据包交付到上层。下面列出了SR接收方所采取的各种动作:
- 正确接收到序列号在区间[rcv_base,rcv_base+N-1]的数据包。在这种情况下,接收到的数据包落在接收方窗口内,一个严格挑选的ACK数据包返回给发送方。如果数据包以前没有收到,它被缓冲。如果这个数据包的序列号等于接收窗口的rcv_base,那么这个数据包和之前缓冲的连续编号(以rcv_base开头)的数据包被交付到上层。然后,接收窗口根据发送到上层的数据包的数量向前移动。例如,图3.26。当接收到序列号rcv_base=2的数据包时,可以同时交付数据包3、4、5到上层。
- 正确接收到序列号在区间[rcv_base-N, rcv_base-1]的数据包。在这种情况下,必须生成一个ACK,即使这是一个接收方之前已经确认过的数据包。
- 否则,忽视数据包。
图3.26显示了存在丢包情况下SR操作的示例。注意,在图3.26中,接收方最初缓冲数据包3、4、5,当最终接收到数据包2时,将它们和数据包2一起交付到上层。
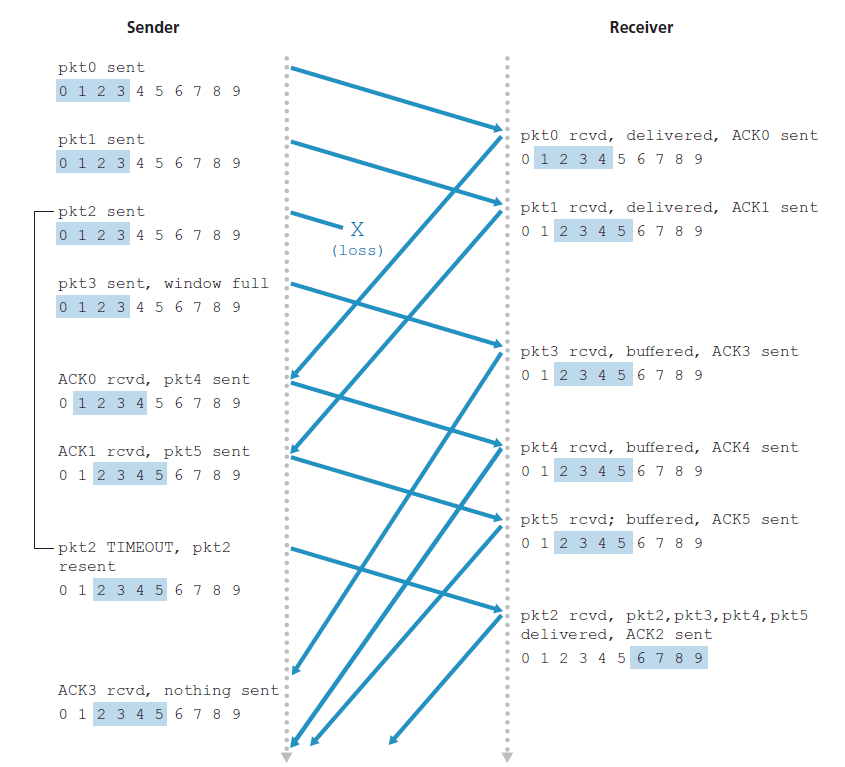
需要注意的是,在上面的步骤2中,接收方重新确认(而不是忽略)已经收到了序列号低于当前窗口base的特定的数据包。你应该说服自己,这种重新确认确实是必要的。假设图3.23中的发送方和接收方的序列号空间,例如,如果数据包send_base没有从接收方确认给发送方的ACK,发送方最终将重新发送数据包send_base,即使很明显接收方已经收到了这个数据包。如果接收方没有确认这个数据包,发送方的窗口将永远不会向前移动!这个例子说明了SR协议(以及许多其他协议)的一个重要方面。发送方和接收方对正确接收到的数据包和错误接收到的数据包的看法并不总是一致的。对于SR协议,这意味着发送方和接收方窗口不会总是一致。
当我们面对序列号范围有限的现实时,发送方和接收方窗口之间缺乏同步具有重要的后果。例如,考虑一个有限范围内的4个数据包序列号(0、1、2、3)和窗口大小为3时会发生什么。假设发送了0到2的数据包,并且在接收方正确接收并确认。此时,接收方窗口超过了第4、第5和第6个数据包,这些数据包的序列号分别为3、0和1。现在考虑两种情况。在第一种场景中,如图3.27(a)所示,前3个数据包的ACK都丢失了,发送方向重传了这些数据包。因此,接收方接下来接收一个序列号为0的数据包,它是第一个发送的数据包的副本。
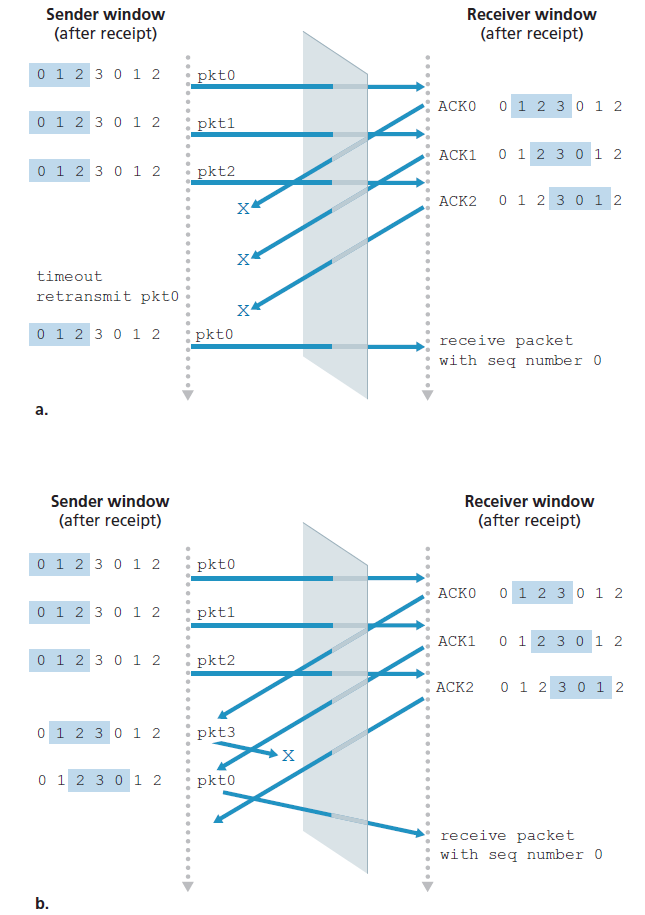
第二种情况,如图3.27(b)所示,前3个数据包的ACK都正确发送。发送方因此向前移动它的窗口,发送第四个、第五个和第六个数据包,序列号分别为3、0和1。序列号为3的数据包丢失,但序列号为0的数据包到达一个包含新数据的数据包。
现在探讨图3.27中接收方视角,它在发送方和接收方之间就像有一个窗帘,因为接收方不能看到发送方所采取的行动。接收方所观察到的是它从信道接收到的消息序列。就目前而言,图3.27中的两个场景是相同的。无法区分第一个数据包的重传和第5个数据包的原始传输。显然,比序列号空间的大小小1的窗口大小是行不通的。但是窗口大小必须多少才合适呢?本章末尾的一个问题要求您说明窗口大小必须小于或等于SR协议序列号空间大小的一半。
在配套的Web站点上,您将看到一个演示SR协议操作的动画。尝试执行与GBN动画相同的实验。结果与你预期的一致吗?
这就完成了我们对可靠数据传输协议的讨论。我们已经讨论了很多方面,并介绍了许多机制,这些机制一起提供了可靠的数据传输。表3.1总结了这些机制。现在我们已经看到所有这些机制在操作,可以看到大局,我们鼓励您重新审查这一节,看这些机制是如何逐步添加到覆盖越来越复杂(和现实)模型的发送方和接收方信道连接,或提高协议的性能。
让我们通过探讨底层信道模型中剩下的一个假设来结束对可靠数据传输协议的讨论。回想一下,我们假设数据包不能在发送方和接收方之间的信道内重新排序。当发送方和接收方通过一条物理线路连接时,这通常是一个合理的假设。然而,当连接两者的通道是一个网络时,数据包的重新排序就可能发生。数据包重新排序的一种表现形式是,序列号或确认号为x的数据包的旧副本可能会出现,即使发送方和接收方的窗口都不包含x。通过数据包的重新排序,信道可以被认为是在本质上数据包缓冲,并在将来的任何时刻自发地发送这些数据包。因为序列号可能会被重用,所以必须注意防止这样的重复数据包。在实践中采用的方法是,确保序列号不会被重用,直到发送方确定以前发送的任何序列号为x的数据包不再存在于网络中。这是通过假设一个数据包不能在网络中存在超过某个固定的最长时间来实现的。在高速网络的TCP扩展中,假设最大的数据包生命周期大约为3分钟[RFC 7323]。[Sunshine 1978]描述了一种使用序列号的方法,这样可以完全避免重新排序的问题。
3.5 面向连接的传输:TCP
现在我们已经讨论了可靠数据传输的基本原理,让我们转向TCP——Internet的传输层、面向连接的可靠传输协议。在本节中,我们将看到,为了提供可靠的数据传输,TCP依赖于在前一节中讨论的许多基础原则,包括错误检测、重传、累积确认、计时器,以及序列和确认号的头字段。RFC 793、RFC 1122、RFC 2018、RFC 5681、RFC 7323定义了TCP协议。
3.5.1 TCP连接
之所以说TCP是 面向连接 的,是因为在一个应用程序进程开始向另一个进程发送数据之前,两个进程必须首先相互握手,也就是说,它们必须互相发送一些初步的段,以建立随后的数据传输的参数。作为TCP连接建立的一部分,连接的两端将初始化与TCP连接相关的一些 TCP状态变量(其中许多将在本节和3.7节中讨论)。
TCP连接不是线路交换网络中的端到端TDM或FDM电路。相反,连接是一个逻辑连接,公共状态只驻留在两个通信端系统的TCP中。回想一下,因为TCP协议只在终端系统中运行,而不在中间网络元素(路由器和链路层交换机)中运行,所以中间网络元素并不维护TCP连接状态。事实上,中间路由器完全不知道TCP连接;他们看到的是数据报,而不是连接。
TCP连接提供 全双工服务(full-duplex service) :如果有一个在主机的进程A和另一个主机进程B间的TCP连接,那么应用层数据从进程A流向进程B的同时也可以从进程B流向进程A. TCP连接是 点对点(point-to-point) 的,即单个发送方和单个接收方之间。所谓的多点广播(multicasting,请参阅本文的在线补充材料)是指在一个发送操作中从一个发送方向多个接收方传输数据,而TCP是不可能实现的。对于TCP,两个主机是伙伴,三个主机是乌合之众!
现在让我们看看TCP连接是如何建立的。假设一个运行在一个主机上的进程想要发起与另一个主机上的另一个进程的连接。回想一下,初始化连接的进程称为客户端进程,而另一个进程称为服务器进程。客户端应用程序进程首先通知客户端传输层,它希望建立到服务器中的进程的连接。回顾2.7.2节,Python客户端程序通过发出命令来实现此功能:
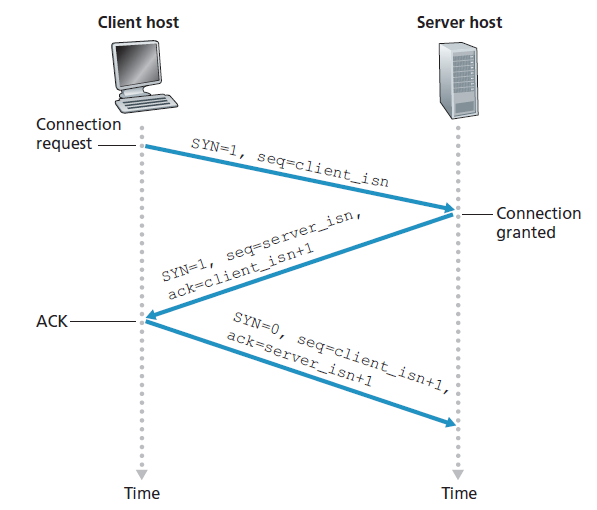
clientSocket.connect((serverName,serverPort))其中serverName是服务器的名称,而serverPort标识服务器上的进程。然后客户端中的TCP继续与服务器中的TCP建立TCP连接。在本节的最后,我们详细讨论了建立连接的过程。现在,只要知道客户端首先发送一个特殊的TCP段就足够了;服务器响应第二个特殊的TCP段;最后,客户端再次以第三个特殊的段回应。前两个段没有负载,即没有应用层数据;这些部分的第三个可以携带一个有效负载。因为两个主机之间要发送三个段,所以这个建立连接的过程通常称为 三次握手 。
一旦TCP连接建立,两个应用程序进程就可以互相发送数据。让我们探讨一下如何将数据从客户端进程发送到服务器进程。客户端进程通过socket(进程的门)传递数据流,如2.7节所述。一旦数据通过门,数据就在客户端中运行的TCP手中。如图3.28所示,TCP将这些数据定向到连接的 发送缓冲区(send buffer) ,这是初始三次握手期间预留的缓冲区之一。TCP会时不时地从发送缓冲区抓取数据块,并将数据交付给网络层。有趣的是,TCP规范[RFC793]在指定TCP应在何时发送缓冲数据方面非常宽松,规定TCP“在自己方便时分段(段)发送数据”。一个段中可以抓取和放置的最大数据量受 最大段大小(MSS ,maximum segment size) 的限制。MSS通常是先通过确定本地发送主机可以发送的 最大传输单元(MTU,maximum transmission unit) ,然后设置MSS以确保TCP段(当封装在IP数据报中时)加上TCP/IP头长度(通常为40字节)将适合单个链路层帧。以太网和PPP链路层协议的MTU都是1500字节。因此,MSS的典型值为1460字节。也有人提出了一些方法来发现path MTU——即从源到目的地的所有链路上可以发送的最大链路层帧[RFC 1191]——并根据path MTU值来设置MSS。需要注意的是,MSS是该段中应用层数据的最大值,而不是包含头的TCP段的值。(这个术语令人困惑,但我们不得不接受它,因为它已经根深蒂固。)
TCP将客户端数据的每个块与一个TCP头配对,从而形成 TCP段 。这些段向下交付给网络层,在那里它们被单独封装在网络层IP数据报中。然后将IP数据报发送到网络中。当TCP在另一端接收到一个段时,该段数据被放在TCP连接的接收缓冲区中,如图3.28所示。应用程序从这个缓冲区读取数据流。连接的每一端都有自己的发送缓冲区和接收缓冲区。(你可以看到在线流量控制在 http://www.awl.com/kurose-ross 的交互式动画,它提供了发送和接收缓冲区的动画。)
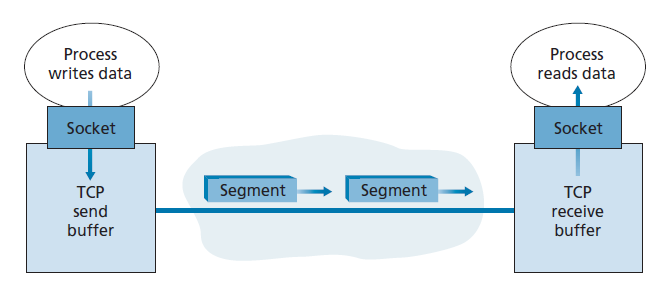
从本文的讨论中,我们可以看到TCP连接包括缓冲区、变量和到一台主机上的进程的套接字连接,以及另一组缓冲区、变量和到另一台主机上的进程的套接字连接。如前所述,没有为主机之间的网络元素(路由器、交换机和中继器)中的连接分配缓冲区或变量。
3.5.2 TCP段结构
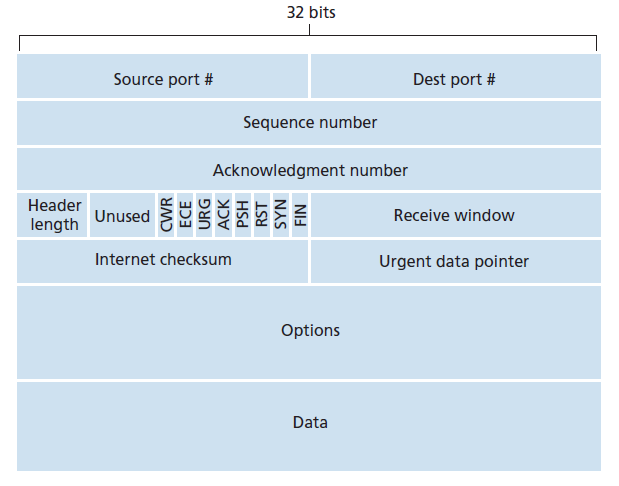
在简要地了解了TCP连接之后,让我们来检查TCP段结构。TCP段由头字段和数据字段组成。数据字段包含一个应用程序数据块。如上所述,MSS限制了段数据字段的最大大小。当TCP发送一个大文件(比如作为Web页面一部分的图像)时,它通常将文件分成大小为MSS的块(最后一个块除外,它通常小于MSS)。然而,交互式应用程序经常传输比MSS小的数据块;例如,对于远程登录应用程序,如Telnet和ssh, TCP段中的数据字段通常只有一个字节。因为TCP头通常是20字节(比UDP报头多12字节),通过Telnet和ssh发送的段可能只有21字节的长度。
图3.29显示了TCP段的结构。与UDP一样,头包括 源和目标端口号 ,用于将数据多路复用/解复用从/到上层应用。同样,与UDP一样,头包含一个 校验和 字段。一个TCP段头还包含以下字段:
- 32 bit的 序列号字段(sequence number field) 和32 bit的 确认号字段(ACKnowledgment number field) 由TCP发送方和接收方在实现可靠的数据传输服务时使用,如下所述。
- 用于流控的16 bit 接收窗口字段(receive window field) ,用于指示接收方愿意接受的字节数。
- 4 bit 头长字段(header length field) 指定TCP头的长度,以32 bit字(32-bit words)为单位。由于TCP options字段,TCP头的长度可以是可变的。(通常,options字段为空,因此典型的TCP头的长度为20字节——即160 bit。)
- 可选和可变长度的 options字段 用于发送方和接收方协商最大段大小(MSS)或作为高速网络中使用的窗口缩放因子。还定义了一个时间戳选项。详细信息请参见RFC 854和RFC 1323。
- 8 bit的 标志字段(flag field) 。 ACK bit用于指示在确认字段中携带的值是有效的;也就是说,段包含对已成功接收的段的确认。 RST,SNY 和 FIN bit用于连接的设置和关闭,我们将在本节的最后讨论。 CWR 和 ECE bit在显式拥塞通知中使用,如章节3.7.2所述。 PSH bit,表示接收方立即将数据交付给上层。最后, URG bit用来表示在这个段中有数据被发送方上层实体标记为紧急。这个紧急数据的最后一个字节的位置由16 bit 紧急数据指针字段(urgent data pointer field) 表示。当紧急数据存在时,TCP必须通知接收方上层实体,并向其传递一个指向紧急数据末端的指针。(实际中不使用PSH、URG和紧急数据指针。但是,我们提到这些字段是为了完整性。)
序列号和确认号
TCP段头中两个最重要的字段是序列号字段和确认号字段。这些字段是TCP可靠数据传输服务的关键部分。但是在讨论如何使用这些字段来提供可靠的数据传输之前,让我们首先解释一下TCP到底在这些字段中放入了什么。
TCP将数据视为一种非结构化但有序的字节流。TCP使用序列号反映了这一观点,因为序列号是在传输的字节流上,而不是在传输的一系列段上。因此,段的序列号(sequence number for a segment)是段中第一个字节的字节流号。让我们看一个例子。假设主机A中的一个进程想要通过TCP连接向主机B中的一个进程发送一个数据流。主机A中的TCP将隐式地为数据流中的每个字节编号。假设数据流由一个50万字节的文件组成,MSS为1000字节,数据流的第一个字节编号为0。如图3.30所示,TCP从数据流中构造了500个段。第一个段被分配的序列号为0,第二个段被分配的序列号为1000,第三个段被分配的序列号为2000,以此类推。每个序列号被插入到相应TCP段头中的序列号字段中。
现在让我们考虑确认号。这比序列号要复杂一些。回想一下,TCP是全双工的,因此主机A在向主机B发送数据时,可能正在接收来自主机B的数据(作为同一TCP连接的一部分)。每个从主机B到达的段都有一个从B流向A的数据的序列号。 主机A放在其段中的确认号是主机A期待来自主机B的下一个字节的序列号 。最好看几个例子来理解这里发生了什么,假设主机A收到了来自主机B的编号为0到535的所有字节,并假设它即将向主机B发送一个段。主机A正在等待字节536以及主机B的数据流中的所有后续字节。所以主机A把536放在它发送给B的段的确认号字段中。
另一个例子,假设主机A从主机B接收到一个包含字节0到535的段,以及另一个包含字节900到1000的段。由于某种原因,主机A还没有接收到536到899的字节。在本例中,主机A仍在等待字节536(及以上),以便重新创建B的数据流。因此,A到B的下一段将在确认号字段中包含536。因为TCP只确认流中丢失的第一个字节之前的字节,所以TCP被认为提供了累积确认。
最后一个例子也提出了一个重要但微妙的问题。主机A在收到第二个段(536 ~ 899)之前,已经收到了第三个段(900 ~ 1000)。因此,第三个段无序到达。一个微妙的问题是:当主机在TCP连接中接收到无序的段时,它会做什么?有趣的是,TCP的RFC在这里没有强加任何规则,而是将决定权留给实现TCP的程序员。基本上有两种选择:要么(1)接收方立即丢弃乱序的段(正如我们在前面讨论的那样,这样可以简化接收方设计),要么(2)接收方保留乱序的字节并等待丢失的字节填补空白。显然,就网络带宽而言,后一种选择更有效,也是在实践中采用的方法。
在图3.30中,我们假设初始序列号为零。实际上,TCP连接的两端随机选择一个初始序列号。这样做是为了减少之前的段仍然存在于网络中的可能性,在两个主机间已被关闭的连接之后的新连接误认为这是一个有效的段(这通常发生在与旧连接使用相同的端口号)[Sunshine 1978]。
Telnet:序列号和确认号的案例研究
RFC 854中定义的Telnet是一种流行的应用层协议,用于远程登录。它在TCP上运行,并被设计为在任何一对主机之间工作。与第2章中讨论的批量数据传输应用程序不同,Telnet是一个交互式应用程序。我们在这里讨论一个Telnet示例,因为它很好地说明了TCP序列号和确认号。我们注意到,许多用户现在更喜欢使用SSH协议而不是Telnet,因为Telnet连接中发送的数据(包括密码!)没有加密,这使得Telnet容易受到窃听攻击(如第8.7节所述)。
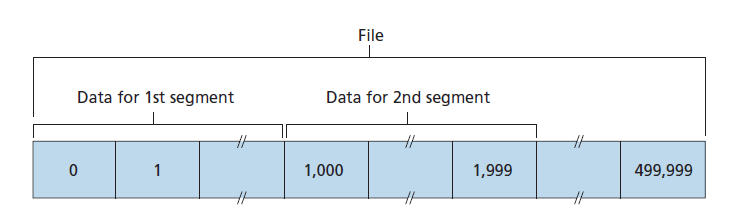
假设主机A与主机B发起了Telnet会话。因为主机A发起了会话,所以它被标记为客户端,而主机B被标记为服务器。用户(在客户端)输入的每个字符都将被发送到远程主机;远程主机将发回每个字符的副本,它将显示在Telnet用户的屏幕上。此回显用于确保远程站点已经接收并处理了Telnet用户看到的字符。因此,从用户敲击键盘的时间到该字符显示在用户监视器上的时间,每个字符都要经过两次网络。
现在假设用户输入一个字母C,然后拿起一杯咖啡。让我们检查一下客户端和服务器之间发送的TCP段。如图3.31所示,我们假设客户端和服务器的起始序列号分别是42和79。回忆一下,段的序列号就是数据字段中的第一个字节的序列号。因此,从客户端发送的第一个段的序列号为42;从服务器发送的第一个段的序列号为79。回想一下,确认号是主机等待的下一个数据字节的序列号。TCP连接建立后,在发送任何数据之前,客户端正在等待79字节,而服务器正在等待42字节。
如图3.31所示,发送了三个段。第一个段从客户端发送到服务器,在它的数据字段中包含字母C的1字节ASCII表示。第一个段的序列号字段中也有42,就像我们刚才描述的那样。同样,因为客户端还没有从服务器接收到任何数据,所以第一个段的确认号字段中有79。
第二个段从服务器发送到客户端。它有双重目的。首先,它对服务器接收到的数据进行确认。通过在确认字段中输入43,服务器就告诉客户端它已经成功接收到字节42之前的所有内容,现在正在等待字节43之后的内容。这个段的第二个目的是回显字母C。因此,第二个段在其数据字段中具有C的ASCII表示。第二个段的序列号是79,这是这个TCP连接的服务器到客户端数据流的初始序列号,因为这是服务器正在发送的数据的第一个字节。请注意,客户端到服务器数据的确认是在服务器到客户端的段中进行的。
第三个段从客户端发送到服务器。它的唯一目的是确认从服务器接收到的数据。(回想一下,第二个段包含了从服务器到客户端的字母C的数据。)这个段有一个空的数据字段(也就是说,确认没有携带任何客户端到服务器的数据)。段在确认号字段中有80,因为客户端已经接收到字节序列号79以内的字节流,它现在正在等待字节80。您可能会认为这个段也有一个序列号是奇怪的,因为这个段不包含数据。但是因为TCP有一个序列号字段,段需要有一个序列号。
3.5.3往返时间估算和超时间隔
TCP,就像3.4节中的rdt协议一样,使用超时/重传机制从丢失的段中恢复。尽管这在概念上很简单,但当我们在实际协议(如TCP)中实现超时/重传机制时,会出现许多微妙的问题。也许最明显的问题是超时间隔的长度。显然,超时间隔应该大于连接的往返时间(RTT),即从发送段到段被确认的时间。否则,将发送不必要的重传。但是大多少呢?一开始应该如何估算RTT ?一个定时器应该与每一个未确认的段相关联吗?这么多问题!我们在本节中的讨论是基于[Jacobson 1988]中的TCP工作和当前IETF管理TCP定时器的建议[RFC6298]。
估算往返时间
让我们从TCP如何估算发送方和接收方之间的往返时间开始我们的TCP定时器管理的研究。这是通过以下方式实现的。采样RTT,记为SampleRTT,是段发送(即交付给IP)和接收到段的确认之间的时间。大多数TCP实现不是为每个传输段测量SampleRTT,而是每次只测量一个SampleRTT。也就是说,在任何时间点,SampleRTT只对一个传输的但当前未确认的段进行估算,导致SampleRTT的新值接近每个RTT。同样,TCP从不为已重传的段计算SampleRTT;它只测量已传输过一次的段的SampleRTT [Karn 1987]。(本章末尾的一个问题要求你思考原因。)
显然,由于路由器的拥塞和终端系统上的负载的变化,SampleRTT值将在各个段之间波动。由于这种波动,任何给定的SampleRTT值都可能是非典型的。为了估算一个典型的RTT,因此,对SampleRTT值取某种平均值是很自然的。TCP维护SampleRTT值的平均值,称为EstimatedRTT。在获得一个新的SampleRTT后,TCP根据以下公式更新EstimatedRTT:
EstimatedRTT = (1 – α) * EstimatedRTT + α * SampleRTT
上面的公式是以编程语言语句的形式编写的,EstimatedRTT的新值是先前EstimatedRTT的值和SampleRTT的新值的加权组合。α的推荐值= 0.125(即1/8)[RFC 6298],则上式为:
EstimatedRTT = 0.875 * EstimatedRTT + 0.125 * SampleRTT
注意,EstimatedRTT是SampleRTT值的加权平均值。正如本章最后的作业中所讨论的,加权平均对近期样本的权重大于对旧样本的权重。这是很自然的,因为最近的样本更好地反映了当前网络的拥塞情况。在统计学中,这样的平均称为 指数加权移动平均(EWMA,exponential weighted moving average) 。指数一词出现在EWMA中是因为给定SampleRTT的权值随着更新的进行呈指数衰减。在作业中,你们会被要求推导EstimatedRTT中的指数项。
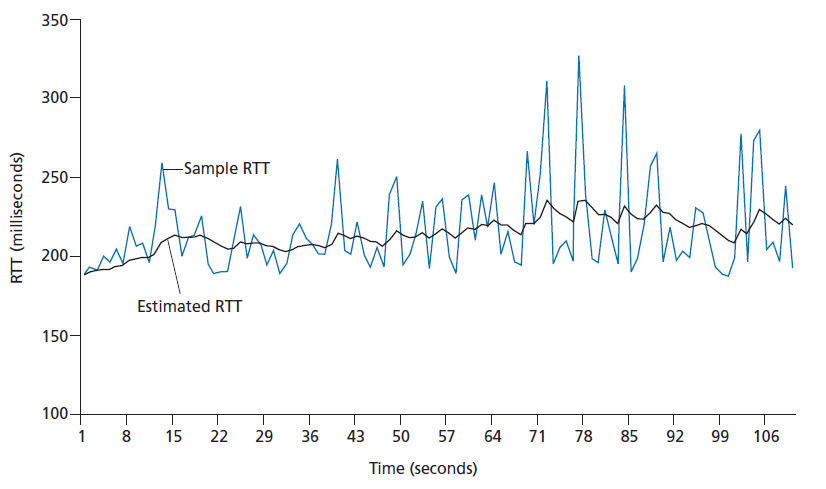
图3.32显示了在α= 1/8时从gaia.c.s.umass.edu(在Amherst,马萨诸塞州)到fantasia.eurecom.fr(在法国南部)的TCP连接的SampleRTT值和EstimatedRTT值。显然,SampleRTT中的变化在EstimatedRTT的计算中是平滑的。
除了RTT的估算外,有一个RTT可变性的度量也是有价值的。[RFC 6298]定义了RTT variation,DevRTT,作为SampleRTT与EstimatedRTT典型差异的估算:
DevRTT = (1 – β) * DevRTT + β * | SampleRTT – EstimatedRTT |
注意,DevRTT是SampleRTT和EstimatedRTT之间的EWMA。如果SampleRTT值波动较小,则DevRTT值较小;另一方面,如果波动很大,DevRTT也会很大。β建议设置为0.25。
设置和管理重传超时间隔
给定EstimatedRTT和DevRTT的值,TCP的超时间隔应该用什么值?显然,间隔应该大于或等于EstimatedRTT,否则将发送不必要的重传。但是超时间隔不应该比EstimatedRTT大太多;否则,当段丢失时,TCP将无法快速重传该段,从而造成较大的数据传输延迟。因此,我们希望将超时设置为EstimatedRTT加上一些余量(margin)。当SampleRTT值波动较大时,margin应较大;波动小的时候小些。因此,DevRTT的值应该在这里发挥作用。在确定重传超时间隔的TCP方法中,所有这些考虑都被考虑在内:
TimeoutInterval = EstimatedRTT + 4 * DevRTT
建议TimeoutInterval的初始值为1秒[RFC 6298]。另外,当超时发生时,TimeoutInterval的值将加倍,以避免即将被确认的后续段出现过早超时。然而,一旦接收到一个段并更新EstimatedRTT,就会再次使用上面的公式计算TimeoutInterval。
3.5.4可靠数据传输
回想一下,因特网的网络层服务(IP服务)是不可靠的。IP不保证数据报的交付,不保证数据报的顺序交付,也不保证数据报中数据的完整性。在IP服务中,数据报可能溢出路由器缓冲区,永远不会到达目的地,数据报可能无序到达,数据报中的比特可能被损坏(从0翻转到1,反之亦然)。因为传输层段是由IP数据报在网络上传输的,所以传输层段也会遇到这些问题。
TCP在IP的不可靠的尽力而为服务的基础上创建了可靠的数据传输服务。TCP可靠的数据传输服务确保进程从TCP接收缓冲区读取的数据流是无损的,没有间隔,没有重复,并且按顺序读取;也就是说,字节流与连接另一端的终端系统发送的字节流完全相同。TCP如何提供可靠的数据传输涉及到我们在第3.4节中研究的许多原则。
在我们早期开发的可靠数据传输技术中,在概念上很容易假设每个传输了但尚未被确认的段都有一个与之关联的单独的计时器。虽然在理论上很好,但计时器管理可能需要相当大的开销。因此,推荐的TCP定时器管理程序[RFC6298]只使用一个重传定时器,即使有多个传输了但尚未确认的段。本节中描述的TCP协议遵循单定时器的建议。
我们将讨论TCP如何在两个增量(incremental)步骤中提供可靠的数据传输。我们首先给出了一个高度简化的TCP发送方描述,它只使用超时来从丢失的段中恢复;然后,我们提供了一个更完整的描述,除了超时之外,还使用了重复确认。在接下来的讨论中,我们假设数据只在一个方向上发送,从主机A发送到主机B,并且主机A正在发送一个大文件。
下面的伪代码给出了一个高度简化的TCP发送方的描述。我们看到,在TCP发送方中,有三个主要事件与数据传输和重传相关:从上面的应用接收的数据;定时器超时;和ACK收据。在第一个主要事件发生时,TCP从应用程序接收数据,将数据封装在一个段中,并将该段交付给IP。请注意,每个段都包含一个序列号,它是段中数据的第一个字节的字节流号,如章节3.5.2所述。还需要注意的是,如果这个定时器已不在其他的段上运行,那么TCP会在这个段被交付给IP时启动这个定时器。(将计时器与最久的未确认的段联系起来是有帮助的。)这个计时器的过期时间间隔是TimeoutInterval,它是从EstimatedRTT和DevRTT计算出来的,如章节3.5.3所述。
# 假设发送方不受TCP流或拥塞控制的限制,来自上面的数据小于MSS,数据传输只有一个方向。
NextSeqNum=InitialSeqNumber
SendBase=InitialSeqNumber
loop (forever) {
switch(event)
event: data received from application above
create TCP segment with sequence number NextSeqNum
if (timer currently not running)
start timer
pass segment to IP
NextSeqNum=NextSeqNum+length(data)
break;
event: timer timeout
retransmit not-yet-ACKnowledged segment with
smallest sequence number
start timer
break;
event: ACK received, with ACK field value of y
if (y > SendBase) {
SendBase=y
if (there are currently any not-yet-ACKnowledged segments)
start timer
}
break;
}第二个主要事件是超时。TCP通过重传段引起超时来响应超时事件。然后TCP重新启动定时器。
TCP发送方必须处理的第三个主要事件是来自接收方的确认段(ACK)(更具体地说,包含有效的ACK字段值的确认段)。当这个事件发生时,TCP将ACK值y与其变量SendBase进行比较。TCP状态变量SendBase是最旧的未确认字节的序列号。(因此SendBase-1是已知已在接收方正确且按顺序接收的最近的一个字节的序列号。)如前所述,TCP使用累积确认,因此y确认字节序列号y之前的所有字节。如果y > SendBase,那么ACK确认了一个或多个之前未被确认的段。因此,发送方更新它的SendBase变量;如果当前有任何尚未确认的段,它也会重新启动计时器。
几个有趣的场景
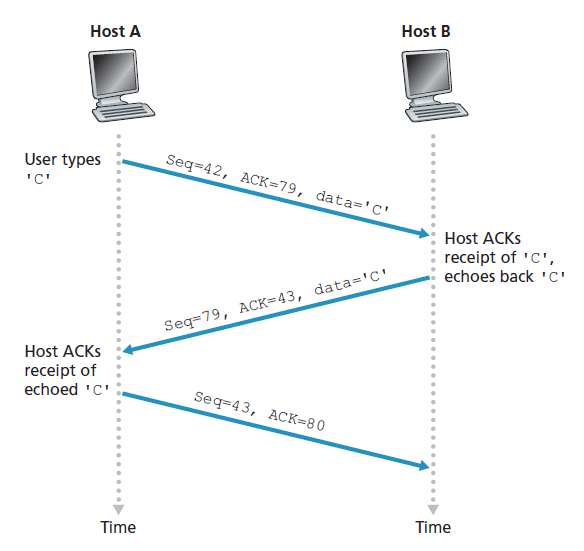
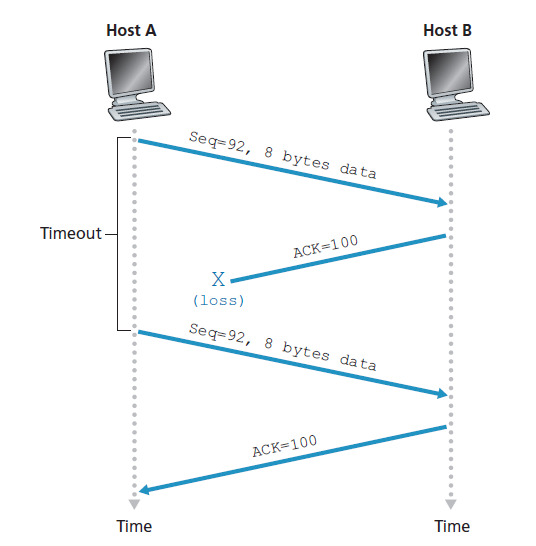
我们刚刚描述了TCP如何提供可靠数据传输的一个高度简化的版本。但即使是这个高度简化的版本也有许多微妙之处。为了更好地了解这个协议是如何工作的,现在让我们来看看几个简单的场景。图3.34描述了第一个场景,在这个场景中,主机A发送一个段给主机B。假设这个段的序列号是92,包含8个字节的数据。在发送这个段后,主机A等待来自B的确认号为100的段。虽然从A到B的段被接收到,但从B到A的确认丢失。在这种情况下,超时事件发生,主机A重传同一段。当然,当主机B接收到重传时,它从序列号观察到段中包含已经接收到的数据。因此,主机B中的TCP将丢弃重传段中的字节。
在第二种场景中,如图3.35所示,主机A将两个段背靠背传送。第一个段有序列号92和8个字节的数据,第二个段有序列号100和20个字节的数据。假设两个段都完整地到达B处,B对每个段发送两个单独的确认。这些确认中的第一个的确认号为100;第二个的确认号为120。假设现在两个确认都没有在超时之前到达主机A。当超时事件发生时,主机A重新发送序号为92的第一个段并重启定时器。只要第二个段的ACK在新的超时之前到达,第二个段就不会被重传。
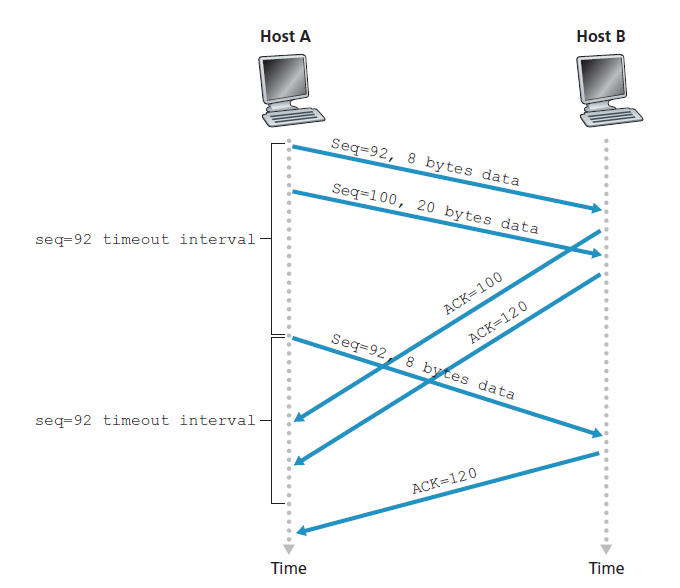
在第三个也是最后一个场景中,假设主机A发送这两个段,就像第二个示例中一样。第一个段的确认在网络中丢失,但在超时事件之前,主机A收到了一个确认号为120的确认。因此主机A知道主机B已经收到了119字节之前的所有信息;所以主机A不会重传这两个段中的任何一个。这个场景如图3.36所示。 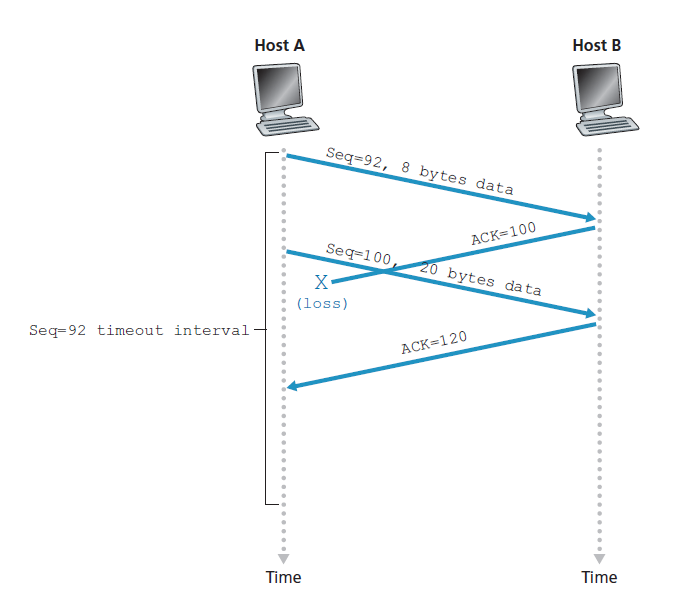
超时间隔加倍
现在我们将讨论大多数TCP实现所采用的一些修改。第一个与计时器超时后的超时间隔(Timeout Interval)有关。在此修改中,每当超时事件发生时,TCP都会用最小序列号重传尚未确认的段,如上所述。但是每次TCP重传时,它都会将下一个超时间隔设置为前一个值的两倍,而不是从最近的EstimatedRTT和DevRTT推导(如章节3.5.3所述)。例如,假设定时器第一次超时时,与最旧的尚未确认的段相关联的TimeoutInterval为0.75秒。TCP将重传这个段,并将新的超时间隔设置为1.5秒。如果1.5秒后这个定时器再次超时,TCP将再次重传这个段,现在将超时间隔设置为3.0秒。因此,每次重传后,间隔将呈指数增长。然而,无论计时器在其他两个事件中的任何一个之后启动(即,从上面的应用程序接收到的数据,以及接收到ACK), TimeoutInterval都是从EstimatedRTT和DevRTT的最新值派生出来的。
这个修改提供了一种有限形式的拥塞控制。(更全面的TCP拥塞控制形式将在3.7节中进行研究。)定时器超时很可能是由网络拥塞引起的,也就是说,太多的数据包到达源和目的地之间的一个(或多个)路由器队列,导致数据包被丢弃和/或长队列延迟。在拥塞的情况下,如果源持续不断地重传数据包,拥塞可能会变得更严重。相反,TCP的行为更有礼貌,每个发送方的重传间隔越来越长。当我们在第六章学习CSMA/CD时,我们将看到以太网使用了类似的思想。
快速重传
超时触发的重传的问题之一是超时时间可能相对较长。当一个段丢失时,这个长超时时间迫使发送方延迟重新发送丢失的数据包,从而增加端到端延迟。幸运的是,发送方通常可以在超时事件发生之前通过所谓的 重复ACK(duplicate ACK) 来检测数据包丢失。重复ACK是一个重新确认发送方先前已经收到的确认的段的ACK。为了理解发送方对重复ACK的响应,我们必须首先看看为什么接收方要发送重复的ACK。表3.2总结了TCP接收方的ACK生成策略[RFC5681]。当TCP接收方接收到一个段其序列号大于下一个,预期的、有序的序列号时,它检测数据流中的一个缺口(gap),即缺失的段。这个缺口可能是网络中丢失或重新排序段的结果。由于TCP不使用否定确认,接收方不能向发送方发送显式的否定确认。相反,它只是重新确认(即生成重复的ACK)它收到的最近的一个有序字节的数据。(请注意,表3.2允许接收方不丢弃无序段的情况。)
| 事件 | TCP接收方动作 |
|---|---|
| 具有预期序列号的段有序到达。所有预期到达的数据的序列号已经确认。 | 延迟ACK。为另一个要到达的有序段等待至多500毫秒。如果下一个有序段在此间隔内没有到达,则发送ACK。 |
| 具有预期序列号的段有序到达。另一个有序段等待ACK传输。 | 立即发送单个累计ACK,并ACKing有序段 |
| 超出预期序列号的无序段到达。缺口检测(Gap detected) | 立即发送重复ACK,指示下一个预期字节的序列号(缺口低的一端)。 |
| 部分或全部到达的段填满接收的数据的缺口 | 立即发送ACK,只要段开始于缺口的低端(lower end of gap)。 |
表3.2 TCP ACK生成建议[RFC 5681]
因为发送方经常连续发送大量的段,如果其中一个段丢失,很可能会出现许多连续重复的ACK。如果TCP发送方对同一数据收到三个重复的ACK,则将此视为一个信号:被ACK了三次的段后面的段已经丢失。(在作业问题中,我们考虑了为什么发送方要等待三个重复的ACK,而不是一个重复的ACK。)当收到三个重复的ACK时,TCP发送方会进行快速重传(RFC 5681),在该段的定时器超时之前重传该段。如图3.37所示,第二个段丢失了,然后在它的计时器超时前重传。对于快速重传的TCP,下面的代码片段替换了图3.33中的ACK接收事件:
event: ACK received, with ACK field value of y
if (y > SendBase) {
SendBase=y
if (there are currently any not yet ACKnowledged segments)
start timer
}else{
/* a duplicate ACK for already ACKed segment */
increment number of duplicate ACKs
received for y
if (number of duplicate ACKS received for y==3)
/* TCP fast retransmit */
resend segment with sequence number y
}
break;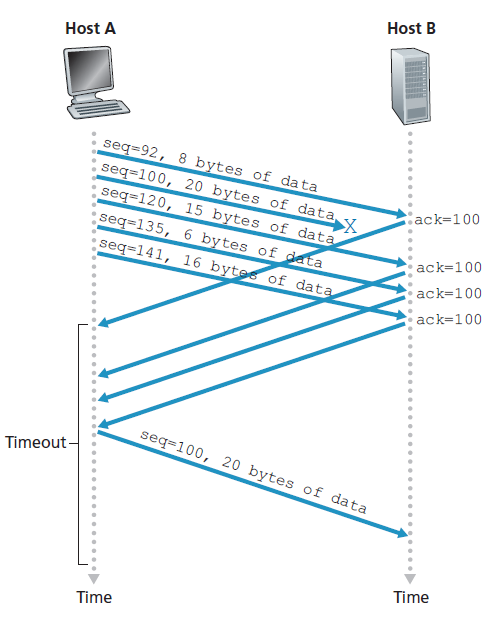
我们在前面注意到,当在实际协议(如TCP)中实现超时/重传机制时,会出现许多微妙的问题。上面的程序是使用TCP计时器30多年经验的结果,应该能使您相信确实如此。
GBN还是SR?
让我们通过考虑以下问题来结束对TCP错误恢复机制的学习:TCP是GBN协议还是SR协议?回想一下,TCP确认是累积的,并且是正确接收的,但是无序的段不会被接收方单独ACK。因此,如图3.33所示(也见图3.19),TCP发送方只需要维护一个已发送但未确认的字节的最小序列号(SendBase)和下一个要发送的字节的序列号(NextSeqNum)。从这个意义上说,TCP看起来很像GBN风格的协议。但是TCP和GBN之间有一些显著的区别。许多TCP实现将缓存正确接收但无序的段[Stevens 1994]。还要考虑当发送方发送一系列段1、2、…N,并且所有的段在接收方无错误且有序到达。进一步假设数据包n < N的确认丢失了,但剩余的N - 1个确认在各自的超时之前到达发送方。在这个例子中,GBN不仅会重传数据包n,而且会重传所有的n + 1, n + 2,…N。另一方面,TCP最多只重传一个段,即段n。而且,如果段n + 1的确认在段n超时之前到达,TCP甚至不会重传段n。
一个对TCP修改的提议,所谓的 选择性确认(selective ACKnowledgment) [RFC 2018],允许TCP接收方有选择地确认无序段,而不是仅仅累积确认最近正确接收的有序段。当与选择性重传相结合时,跳过已经被接收方选择性地确认的段的重传,此时TCP看起来很像我们的通用SR协议。因此,TCP的错误恢复机制可能最好归类为GBN和SR协议的组合。
3.5.5 流控
回想一下,TCP连接的每一端的主机都为连接预留了一个接收缓冲区。当TCP连接接收到正确且有序的字节时,它将数据放在接收缓冲区中。关联的应用程序进程将从这个缓冲区读取数据,但不一定是在数据到达的那一刻。实际上,接收应用程序可能正忙于其他任务,甚至可能在数据到达很久之后才尝试读取数据。如果应用程序读取数据的速度相对较慢,发送方很容易因为快速发送过多的数据而溢出连接的接收缓冲区。
TCP为其应用程序提供了一个 流量控制服务(flow-control service) ,以消除发送方溢出接收方缓冲区的可能性。因此,流量控制是一种速度匹配服务,它将发送方发送的速率与接收方应用程序读取的速率进行匹配。如前所述,TCP发送方也可能由于IP网络内的拥塞而受到限制;这种形式的发送方控制被称为 拥塞控制(congestion control) ,我们将在第3.6和3.7节详细探讨这个主题。尽管流量控制和拥塞控制所采取的行动相似(对发送方进行节流,throttling),但它们显然是出于非常不同的原因而采取的。不幸的是,许多作者交替使用这些术语,精明的读者将会很明智地区分它们。现在让我们讨论TCP如何提供它的流控服务。为了看到树的森林,我们假设整个部分的TCP实现是这样的,TCP接收方丢弃无序的段。
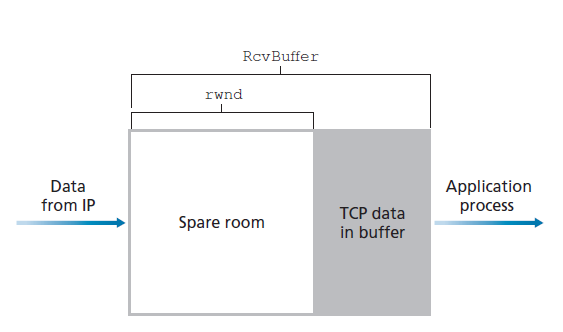
TCP通过让发送方维护一个称为 接收窗口(receive window) 的变量来提供流控。非正式地说,接收窗口用于让发送方了解接收方有多少空闲缓冲区空间可用。因为TCP是全双工的,连接的每一边的发送方都维护一个不同的接收窗口。让我们在文件传输的环境中研究接收窗口。假设主机A通过TCP连接向主机B发送一个大文件。主机B为这个连接分配一个接收缓冲区;用RcvBuffer表示其大小。主机B中的应用程序进程有时会从缓冲区中读取数据。定义以下变量:
- LastByteRead : 主机B中应用程序进程最近在缓冲区中读取的字节流的字节数。
- LastByteRcvd : 最近从网络到达主机B接收缓冲区的字节流的字计数。
因为TCP不允许溢出分配的缓冲区,所以:
LastByteRcvd – LastByteRead <= RcvBuffer
接收窗口,记作rwnd,设置为缓冲区中的空闲空间的数量:
rwnd = RcvBuffer – (LastByteRcvd – LastByteRead)
因为空闲空间是随时间变化的,所以rwnd是动态的。变量rwnd如图3.38所示。
连接如何使用变量rwnd来提供流量控制服务?主机B通过在它发送给主机A的每个段的接收窗口字段中放置它的rwnd当前值来告诉主机A它在连接缓冲区中有多少空闲空间。请注意,要实现这一点,主机B必须跟踪几个于特定连接的变量。
主机A依次跟踪两个变量LastByteSent和LastByteACKed,它们有明显的含义。请注意这两个变量的区别,LastByteSent - LastByteACKed是A发送到连接的未确认数据的数量。通过保持未确认数据的数量小于rwnd的值,主机A可以保证它不会溢出主机B的接收缓冲区。因此,主机A确保在连接的整个生命周期内都是这样的:
LastByteSent – LastByteACKed <= rwnd
这个方案有一个小的技术问题。要看到这一点,假设主机B的接收缓冲区已满,使rwnd = 0。在向主机A公布rwnd = 0之后,还假设B没有任何东西可以发送给主机A。现在考虑发生了什么。当主机B的应用程序进程清空缓冲区,TCP不会发送新的段与新的rwnd值到主机A;实际上,TCP只有在有数据要发送或有确认要发送时才会向主机A发送一个段。因此,主机A永远不会被告知主机B的接收缓冲区中已经有了一些空间。主机A被阻塞,不能再传输数据了!为了解决这个问题,TCP规范要求主机A在B的接收窗口为0时继续发送一个字节数据的段。这些段将被接收方确认。最终,缓冲区将开始清空,确认将包含一个非零的rwnd值。
在描述了TCP的流量控制服务之后,我们在这里简要地提到UDP不提供流量控制,因此,由于缓冲区溢出,段可能会在接收方丢失。例如,考虑从主机A上的一个进程发送一系列的UDP段到主机B上的一个进程。对于一个典型的UDP实现,UDP将把这些段附加在一个有限大小的缓冲区中,该缓冲区位于相应的套接字之前(即,进程的门)。进程每次从缓冲区中读取一个完整的段。如果进程从缓冲区中读取段的速度不够快,那么缓冲区就会溢出,段就会被丢弃。
3.5.6 TCP连接管理
在本小节中,我们将更详细地了解TCP连接是如何建立和拆除的。虽然这个主题可能看起来不是特别令人兴奋,但它很重要,因为TCP连接的建立会显著增加感知的延迟(例如,在浏览Web时)。此外,许多最常见的网络攻击,包括非常流行的SYN flood攻击(请参阅侧栏关于SYN flood攻击),都利用了TCP连接管理中的漏洞。让我们先看看TCP连接是如何建立的。假设一个运行在一台主机(客户端)上的进程想要发起与另一台主机(服务器)上的另一个进程的连接。客户端应用程序进程首先通知客户端TCP,它想要建立到服务器中的一个进程的连接。客户端中的TCP通过以下方式与服务器中的TCP建立TCP连接:
- 客户端TCP首先向服务器端TCP发送一个特殊的TCP段。此特殊段不包含应用层数据。但是段头中的一个标志位(参见图3.29)SYN位被设置为1。由于这个原因,这个特殊的段被称为SYN段。另外,客户端随机选择一个初始序列号(client_isn),并将这个序列号放在初始TCP SYN段的序列号字段中。这个段封装在一个IP数据报中并发送给服务器。为了避免某些安全攻击,人们对正确随机选择client_isn有相当大的兴趣[CERT 2001 09;RFC 4987)。
- 一旦包含TCP SYN段的IP数据报到达服务器主机(假设它确实到达了!),服务器就从数据报中提取TCP SYN段,为连接分配TCP缓冲区和变量,并向客户端TCP发送一个连接同意(connection-granted)的段。(我们将在第8章中看到,在完成三次握手的第三步之前,分配这些缓冲区和变量会使TCP容易受到称为SYN flooding的拒绝服务攻击。)这个连接同意段也不包含应用层数据。然而,它在段头中包含了三个重要的信息。首先,SYN位设置为1。第二,TCP段头的确认字段被设置为client_isn+1。最后,服务器选择它自己的初始序列号(server_isn),并将这个值放在TCP段头的序列号字段中。这个连接同意段实际上是说,我收到了您的SYN数据包,以启动一个使用您的初始序列号client_isn的连接。我同意建立这种连接。我自己的初始序列号是server_isn。连接同意的段称为SYNACK段(SYNACK segment)。
- 在接收到SYNACK段后,客户端还分配缓冲区和变量到连接。然后客户端主机向服务器发送另一个段;最后一个段确认服务器连接同意段(客户端通过将值server_isn+1放在TCP段头的确认字段中来实现)。由于连接建立,SYN位被设置为零。三次握手的第三阶段可能在段有效负载中携带客户端到服务器的数据。
完成这三个步骤后,客户端和服务器主机就可以互相发送包含数据的段。在这些未来的每个段中,SYN位将被设置为零。注意,为了建立连接,两台主机之间要发送三个数据包,如图3.39所示。由于这个原因,这个建立连接的过程通常被称为三次握手。作业问题中探讨了TCP三次握手的几个方面(为什么需要初始序列号?为什么需要三次握手,而不是双向握手?)。有趣的是,攀岩者和其保护者(他在攀岩者的下方,其工作是处理攀岩者的安全绳)使用和TCP相同的three-way-handshake通信协议,以在攀爬者开始攀爬之前,确保两边都准备好。
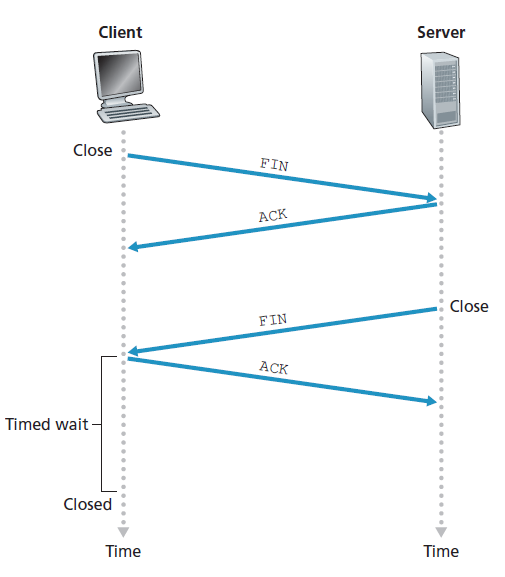
一切美好的事物都有终结的时候,TCP连接也是如此。参与TCP连接的两个进程都可以终止该连接。当连接结束时,主机中的资源(即缓冲区和变量)将被释放。例如,假设客户端决定关闭连接,如图3.40所示。客户端应用程序进程发出一个关闭命令。这导致客户端TCP向服务器进程发送一个特殊的TCP段。这个特殊的段在其报头中有一个标志位,FIN位(参见图3.29),设置为1。当服务器接收到这个段时,它返回给客户端一个确认段。然后服务器发送自己的关闭段,其中FIN位设置为1。最后,客户端确认服务器的关闭段。此时,两个主机中的所有资源现在都被释放了。
在TCP连接的生命周期中,运行在每个主机上的TCP协议要经历各种TCP状态的转换。图3.41展示了客户端TCP访问的一个典型的TCP状态序列。客户端TCP从CLOSED状态开始。客户端的应用程序发起一个新的TCP连接(通过在我们第二章的Python例子中创建一个Socket对象)。这导致客户端的TCP向服务器端的TCP发送一个SYN段。在发送SYN段之后,客户端TCP进入SYN_SENT状态。当处于SYN_SENT状态时,客户端TCP等待来自服务器TCP的一个段,该段包含对客户端上一个段的确认,并将SYN位设置为1。接收到这样一个段后,客户端TCP进入ESTABLISHED状态。当处于ESTABLISHED状态时,TCP客户端可以发送和接收包含有效负载(即应用程序生成的)数据的TCP段。
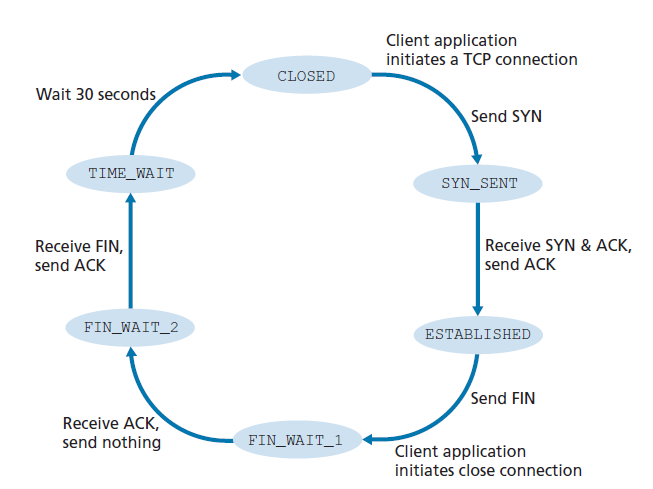
假设客户端应用程序决定关闭连接。(注意服务器也可以选择关闭连接。)这将导致客户端TCP发送一个FIN位为1的TCP段,并进入FIN_WAIT_1状态。当处于FIN_WAIT_1状态时,客户端TCP等待来自服务器的一个TCP段的确认。当它接收到这个段时,客户端TCP进入FIN_WAIT_2状态。当处于FIN_WAIT_2状态时,客户端等待服务器的另一个FIN位为1的段;客户端TCP收到这个段后,确认服务器的段,并进入TIME_WAIT状态。TIME_WAIT状态允许TCP客户端在ACK丢失的情况下重新发送最终确认。花费在TIME_WAIT状态上的时间与实现有关,但典型的值是30秒、1分钟和2分钟。等待之后,连接正式关闭,客户端上的所有资源(包括端口号)被释放。
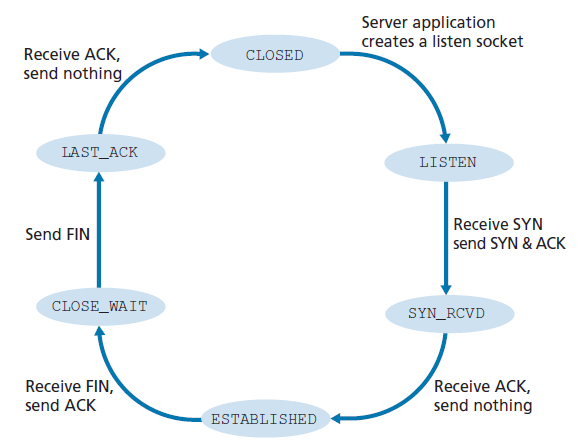
图3.42展示了服务器端TCP访问的一系列状态,假设客户端开始关闭连接。过渡是不言自明的。在这两个状态转换图中,我们只展示了TCP连接是如何正常建立和关闭的。我们还没有描述在某些病理(pathological)场景中会发生什么,例如,当连接的两端同时想要启动或关闭时。如果您有兴趣了解这个和其他关于TCP的高级问题,鼓励您阅读史蒂文斯的综合性著作[Stevens 1994]。
我们上面的讨论假设客户端和服务器都准备通信,也就是说,服务器正在端口监听客户端发送SYN段。让我们考虑一下,当主机接收到一个端口号或源IP地址与主机中正在进行的任何套接字不匹配的TCP段时,会发生什么。例如,假设一个主机收到一个目标端口为80的TCP SYN数据包,但是该主机不接受端口80上的连接(也就是说,它没有在端口80上运行Web服务器)。然后主机将向源发送一个特殊的重置段。这个TCP段的RST标志位(参见章节3.5.2)设置为1。因此,当主机发送一个重置段时,它告诉源我没有这个段的套接字。请不要重发段。当主机接收到一个目标端口号与正在运行的UDP套接字不匹配的UDP数据包时,主机发送一个特殊的ICMP数据报,如第五章所述。
现在,我们已经很好地理解了TCP连接管理,让我们重新访问nmap端口扫描工具,并更深入地研究它的工作原理。为了探测目标主机上的特定TCP端口,比如端口6789,nmap将向该主机发送一个目标端口为6789的TCP SYN段。有三种可能的结果:
- 源主机从目标主机接收到一个TCP SYNACK段。因为这意味着应用程序在目标主机上以TCP端口6789运行,所以nmap返回open。
- 源主机从目标主机接收到一个TCP RST段。这意味着SYN段到达了目标主机,但目标主机没有运行在TCP端口6789的应用程序。但攻击者至少知道,在源主机和目标主机之间的路径上,指向端口为6789的主机的段没有被任何防火墙阻断。(防火墙将在第8章中讨论。)
- 源接收不到任何信息。这可能意味着SYN段被中间的防火墙阻止,永远不会到达目标主机。
Nmap是一个功能强大的工具,它不仅可以探路“case the joint)开放的TCP端口、开放的UDP端口、防火墙及其配置,甚至可以探测应用程序和操作系统的版本。这主要是通过操作TCP连接管理段来完成的。nmap可以从www.nmap.org下载。
这就完成了我们对TCP中的错误控制和流控制的介绍。在3.7节中,我们将回到TCP,并更深入地研究TCP拥塞控制。然而,在这样做之前,我们首先后退一步,在更广泛的背景下研究拥塞控制问题。
聚焦安全之:SYN flood攻击
我们已经在TCP的三次握手的讨论中看到,服务器分配和初始化连接变量和缓冲区来响应接收到的SYN,然后服务器发送一个SYNACK作为响应,并等待来自客户端的ACK段。如果客户端没有发送ACK来完成这个3次握手的第三步,最终(通常在一分钟或更长时间后)服务器将终止这个半开的连接并回收分配的资源。
这个TCP连接管理协议为典型的拒绝服务(DoS)攻击(即SYN flood攻击)奠定了基础。在这种攻击中,攻击者在没有完成第三个握手步骤的情况下,发送大量的TCP SYN段。随着SYN段的泛滥,服务器的连接资源将耗尽,因为它们被分配给了半开的连接(但从来没有使用过!)然后,拒绝为合法客户端提供服务。这种SYN泛洪攻击是最早记录在案的DoS攻击之一[CERT SYN 1996]。幸运的是,现在大多数主要操作系统都部署了一种名为SYN cookie的有效防御。SYN cookie的工作原理如下:
- 当服务器接收到一个SYN段时,它不知道这个段是来自合法用户还是属于SYN flood攻击的一部分。因此,服务器不是为这个SYN创建一个半开的TCP连接,而是创建一个初始的TCP序列号,它是一个复杂的函数(哈希函数),包含SYN段的源IP地址、目标IP地址和端口号,以及一个只有服务器知道的秘密号码。这个精心制作的初始序列号就是所谓的cookie。然后服务器发送一个带有这个特殊初始序列号的SYNACK数据包给客户端。重要的是,服务器不会记住与SYN对应的cookie或任何其他状态信息。
- 一个合法的客户端将返回一个ACK段。当服务器接收到这个ACK时,它必须验证这个ACK是否与之前发送的某个SYN相对应。但是,如果服务器没有维护关于SYN段的内存,如何实现这一点呢?正如你可能已经猜到的,这是用cookie完成的。回想一下,对于合法的ACK,确认字段中的值等于SYNACK中的初始序列号(本例中的cookie值)加上1(参见图3.39)。然后,服务器可以使用SYNACK中的源、目标IP地址和端口号(与原始SYN中的源IP地址和端口号相同)和秘密号运行相同的哈希函数。如果函数加1的结果与客户端SYNACK中的确认 (cookie)值相同,服务器就认为ACK对应于更早的SYN段,因此是有效的。然后服务器创建一个完全打开的连接和一个套接字。
- 另一方面,如果客户端没有返回一个ACK段,那么原始的SYN不会对服务器造成伤害,因为服务器还没有分配任何资源来响应原始的伪造SYN。
3.6 拥塞控制原理
在前几节中,我们研究了一般原则和特定的TCP机制,这些TCP机制用于在面临数据包丢失时提供可靠的数据传输服务。我们前面提到过,在实践中,这种丢失通常是由于网络拥塞时路由器缓冲区溢出造成的。因此,数据包重传只处理网络拥塞的症状(丢失特定的传输层段),而不处理网络拥塞的原因,因为太多的源试图以过高的速率发送数据。为了处理网络拥塞的原因,需要在网络拥塞面前限制发送方的机制。
在这一节中,我们将在一般的背景下考虑拥塞控制问题,试图理解为什么拥塞是一件坏事,网络拥塞如何体现上层应用程序接收的性能,以及可以采取的各种方法来避免或应对网络拥塞。这种更一般的拥塞控制研究是合适的,因为与可靠的数据传输一样,拥塞控制在网络中最重要的十大问题中排名靠前。下面将详细研究TCP的拥塞控制算法。
3.6.1 拥塞的原因和开销
让我们从三种日益复杂的发生拥塞的情况开始对拥塞控制的一般研究。在每一种情况下,我们都将先了解为什么会发生拥塞,以及拥塞的开销(即资源未被充分利用和终端系统接收到的性能较差)。我们不会(现在)关注如何应对或拥塞避免,而是关注更简单的问题:当主机的传输速率增加,网络出现拥塞时,会发生什么。
场景1:两个发送方,一个具有无限缓冲区的路由器
我们首先考虑可能最简单的拥塞场景:两台主机(A和B)都有一个连接,在源和目的地之间共享一个单跳(single hop),如图3.43所示。
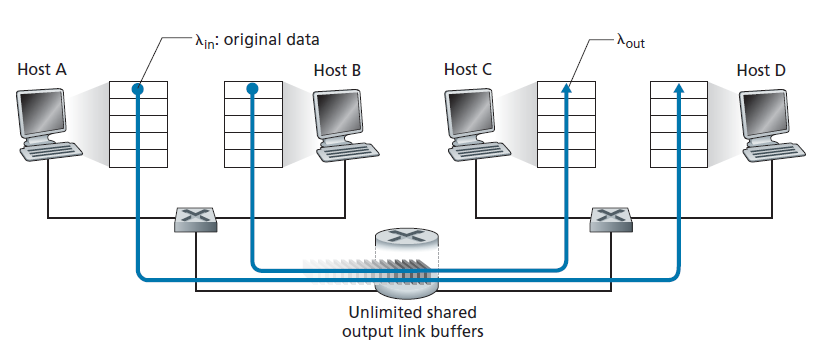
让我们假设主机A中的应用程序正在以平均每秒λin字节的速度向连接发送数据(例如,通过套接字将数据交付给传输级协议)。这些数据是原始的,因为每个数据单元只被发送到套接字一次。底层传输层协议很简单。数据被封装并发送;没有错误恢复(例如,重传),流量控制,或拥塞控制被执行。忽略由于增加传输和底层头信息而产生的额外开销,在第一种情况下,主机A向路由器提供流量的速率是λin字节/秒。主机B以类似的方式运行,为了简单起见,我们假设它也以每秒λin字节的速率发送。来自主机A和主机B的数据包要经过一台路由器,并且通过容量为R的共享传出链路。路由器有缓冲区,当数据包到达速率超过出传出链路的容量时,可以存储传入方向的数据包。在第一个场景中,我们假设路由器有无限的缓冲区空间。
图3.44绘制了第一种场景下主机A的连接性能。左边的图绘制了 逐连接吞吐量 (per-connection throughput,接收方每秒的字节数)关于连接发送速率的函数。当发送速率在0到R/2之间时,接收方吞吐量等于发送方发送速率,发送方发送的所有内容都被接收方以有限的延迟接收。当发送速率大于R/2时,吞吐量仅为R/2。这个吞吐量上限是两个连接共享链路容量的结果。链路不能以超过R/2的稳定速率向接收方发送数据包。无论主机A和主机B将它们的发送速率设置得多高,它们都不会看到高于R/2的吞吐量。
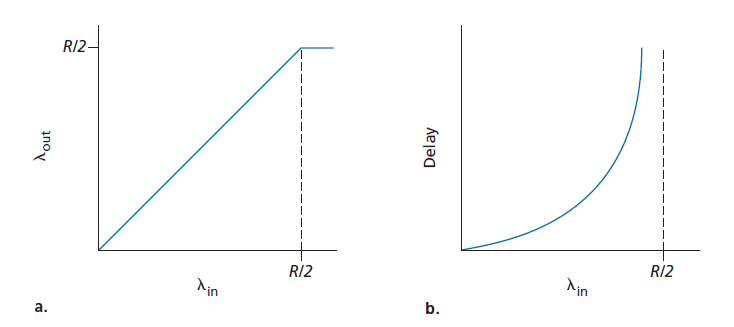
实现逐连接吞吐量R/2实际上似乎是一件好事,因为在向目的地发送数据包时,链路被充分利用了。然而,图3.44中的右边图显示了这样做的后果。当发送速率接近R/2(从左边开始)时,平均延迟越来越大。当发送速率超过R / 2,路由器排队数据包的平均数量是无限的,在源和目的地之间的平均延迟变得无限大(无限的时间,无限数量的缓冲可用)。因此,从吞吐量的角度来看,在接近R的总吞吐量下运行可能是理想的,但从延迟的角度来看,它远非理想。即使在这种(极其)理想的情况下,我们也已经发现了网络拥塞的一个开销——当数据包到达率接近链路容量时,会出现大量的排队延迟。
场景2:两个发送方和一个具有有限缓冲区的路由器
现在让我们用以下两种方式略微修改场景1(参见图3.45)。首先,假设路由器缓冲的数量是有限的。这样当数据包到达一个已满的缓冲区时将被丢弃。其次,我们假设每个连接都是可靠的。如果包含传输级段的数据包在路由器上被丢弃,发送方最终将重新发送它。因为数据包可以被重传,所以我们现在必须更加小心地使用术语 发送速率 (sending rate)。特别地,让我们再次以 λin 字节/秒表示应用程序将原始数据发送到套接字的速率。传输层将段(包含原始数据和重传数据)发送到网络的速率将以 λin' 字节/秒表示, λin' 有时被称为网络的 提供负载(offered load) 。
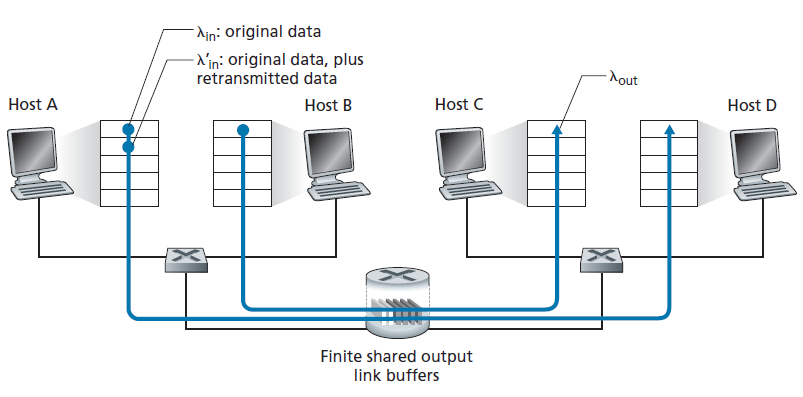
在场景2中实现的性能现在在很大程度上取决于如何执行重传。首先,考虑一种不现实的情况,主机A能够以某种方式确定路由器中缓冲区是否空闲,因此只有当缓冲区空闲时才发送数据包。在这种情况下,不会发生任何丢失,λin 等于 λin',连接的吞吐量等于 λin。案例如图3.46(a)所示。从吞吐量的角度来看,性能是理想的,发送的所有内容都被接收到。注意,在这种情况下,主机的平均发送速率不能超过R/2,因为假设丢包不会发生。
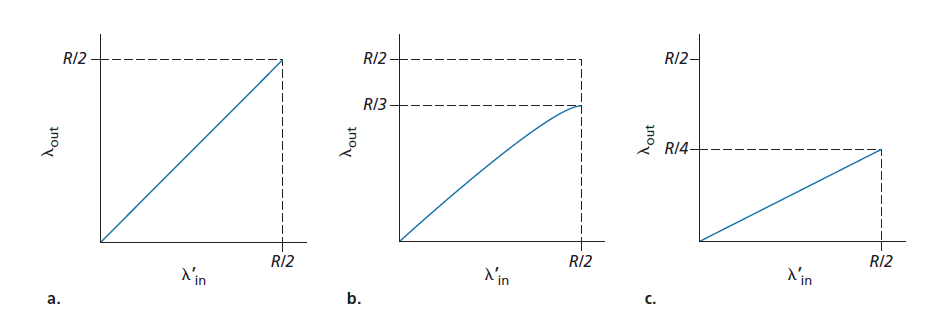
接下来考虑更现实一点的情况,发送方只有在确定丢包时才重新发送。(同样,这个假设有点牵强。然而,发送主机可能会将它的超时设置得足够大,以确保一个尚未被确认的数据包被认为已丢失。)在这种情况下,性能可能如图 3.46(b)所示。为了理解这里发生了什么,考虑这样一种情况,即提供负载λin'(原始数据传输速率加上重传速率)等于R/2。根据图3.46(b),在提供负载的这个值下,数据交付给接收应用程序的速率为R/3。因此,在0.5R单位的传输数据中,原始数据为0.333R字节/秒(平均),重传数据为0.166R字节/秒(平均)。 我们在这里看到拥塞网络的另一个开销:发送方必须执行重传,以补偿由于缓冲区溢出而丢失的数据包。
最后,让我们考虑这样一种情况:发送方可能提前超时并重新发送一个在队列中被延迟但尚未丢失的数据包。在这种情况下,原始数据包和重传数据包都可能到达接收方。当然,接收方只需要这个数据包的一个副本并将丢弃重传。在这种情况下,路由器在转发重传的原始数据包副本时所做的工作就被浪费了,因为接收方已经收到了这个数据包的原始副本。路由器最好使用链路传输容量来发送一个不同的数据包。这是拥塞网络的另一个开销,发送方在面对大的延迟时进行不需要的重传可能导致路由器使用它的链路带宽来转发一个不需要的数据包的副本。 图3.46 (c)显示了吞吐量与提供负载之间的关系,假设每个数据包被路由器转发(平均)两次。由于每个数据包被转发两次,当提供的负载接近R/2时,吞吐量将有一个渐近值R/4。
场景3:四个发送方,具有有限缓冲区的路由器和多跳路径
在我们最后的拥塞场景中,4台主机传输数据包,每台都在重叠的两跳路径上,如图3.47所示。我们再次假设每台主机使用超时/重传机制来实现可靠的数据传输服务,所有主机的λin值相同,所有路由器链路的容量为R字节/秒。
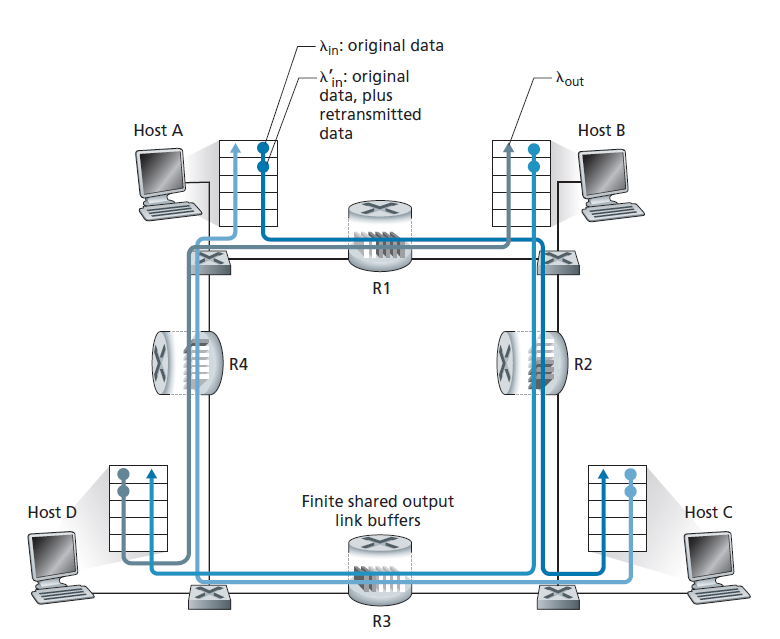
让我们考虑从主机A到主机C的连接,通过路由器R1和R2。A - C连接与D - B连接共享路由器R1,与B - D连接共享路由器R2。对于λin值非常小的情况,缓冲区溢出很少(如拥塞场景1和2),并且吞吐量大约等于提供负载。对于稍微大一点的λin值,相应的吞吐量也更大,因为更多的原始数据正在传输到网络并交付到目的地,溢出仍然很少。因此,对于小λin值,λin的增加会导致λout的增加。
考虑了极低流量的情况后,让我们接下来研究λin(因此 λin' 也很大)非常大的情况。考虑路由器R2。到达路由器R2的A - C流量(从R1转发后到达R2)在R2的到达速率最多为R,即从R1到R2的链路容量,无论λin值为多少。如果 λin' 对于所有连接(包括B-D连接)都非常大,那么B - D流量在R2的到达率就会远远大于A - C流量的到达率。因为A - C和B - D流量必须在路由器R2争夺有限的缓冲空间,成功穿过R2(也就是说,不因缓冲区溢出丢失)的A - C流量变得越来越小,B - D提供负载就变得越来越大。在极限情况下,当提供负载接近无穷大时,R2上的一个空缓冲区立即被一个B - D数据包填满,R2上A - C连接的吞吐量就会变为零。反过来,这意味着A - C端到端吞吐量在高流量的限制下为零。这些考虑导致了提供负载与吞吐量的权衡,如图3.48所示。
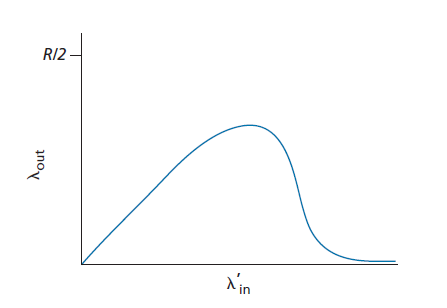
当考虑到网络所浪费的工作量时,随着提供负载的增加,吞吐量最终下降的原因是显而易见的。在上面提到的高流量场景中,每当一个数据包在第二跳路由器上被丢弃时,第一跳路由器在将数据包转发给第二跳路由器时所做的工作就被浪费了。如果第一个路由器只是简单地丢弃数据包并保持空闲状态,这个网络也会同样的好(更准确地说,同样的坏)。更重要的是,在第一个路由器上用于将数据包转发给第二个路由器的传输容量本可以更有效地用于传输不同的数据包。(例如,在选择要传输的数据包时,路由器最好给那些已经通过一些上游路由器的数据包更高的优先级。)这里我们看到了另一个由于拥塞而丢包的开销——当一个数据包在一个路径上被丢弃时,在每个上游链路上用来将该数据包转发到丢弃点的传输容量最终被浪费了。
3.6.2拥塞控制方法
在3.7节中,我们将详细研究TCP用于拥塞控制的具体方法。在这里,我们确定了在实践中采用的两种广泛的拥塞控制方法,并讨论了具体的网络架构和包含这些方法的拥塞控制协议。
在最高层次上,我们可以通过网络层是否为传输层提供明确的拥塞控制目的来区分各种拥塞控制方法:
端到端拥塞控制 。在拥塞控制的端到端方法中,网络层没有为传输层提供拥塞控制目的的明确支持。即使网络拥塞的存在也必须由终端系统仅根据观察到的网络行为(例如,丢包和延迟)推断出来。在第3.7.1节中,我们很快就会看到TCP采用这种端到端的方法来控制拥塞,因为IP层不需要向主机提供关于网络拥塞的反馈。TCP段丢失(如超时或收到三个重复确认)被视为网络拥塞的指示,TCP相应地减小其窗口大小。我们还将看到一个最近的TCP拥塞控制提议,它使用增加的往返段延迟作为增加的网络拥塞的指标。
Network-assisted拥塞控制 。在网络辅助的拥塞控制中,路由器向发送方和/或接收方提供关于网络拥塞状态的明确反馈。这种反馈可能像单个比特一样简单,表示链路上的拥塞,这种方法在早期IBM SNA [Schwartz 1982], DEC DECnet [Jain 1989;Ramakrishnan 1990],以及ATM [BlACK 1995]网络架构中采用。更复杂的反馈也是可能的。例如,在 ATM可用比特率 (ABR,Available Bite Rate)拥塞控制中,路由器通知发送方它(路由器)可以在输出链路上支持的最大主机发送速率。如上所述,internet默认版本的IP和TCP采用端到端方式实现拥塞控制。然而,在第3.7.2节中,我们将看到,最近,IP和TCP也可以选择性地实现网络辅助拥塞控制。
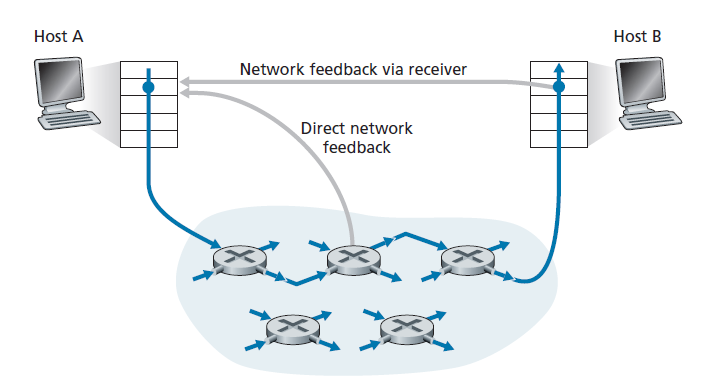
对于网络辅助的拥塞控制,拥塞信息通常以两种方式之一从网络反馈给发送方,如图3.49所示。直接反馈可以从网络路由器发送到发送方。这种形式的通知通常采用阻塞数据包(choke packet)的形式。第二种也是更常见的通知形式发生在路由器标记/更新从发送方到接收方的数据包中的字段,以表示拥塞。在收到一个标记的数据包后,接收方然后通知发送方拥塞指示。后一种形式的通知需要完整的往返时间。
3.7 TCP拥塞控制
在本节中,我们将回到TCP的研究。正如我们在3.5节中了解到的,TCP在运行在不同主机上的两个进程之间提供了可靠的传输服务。TCP的另一个关键组成部分是它的拥塞控制机制。在前面的小节中的,我们可以称之为经典TCP——在[RFC 2581]中标准化的版本,最近的[RFC 5681]版本——使用端到端拥塞控制而不是network-assisted拥塞控制,因为IP层没有向终端系统提供关于网络拥塞的明确反馈。我们将首先在第3.7.1节中深入讨论这个经典的TCP版本。在第3.7.2节中,我们将讨论使用网络层提供的显式拥塞指示,或者与经典TCP稍有不同的TCP新版本。然后,我们将讨论在必须共享拥塞链路的传输层流之间提供公平性的挑战。
3.7.1 经典TCP拥塞控制
TCP所采用的方法是让每个发送方根据感知到的网络拥塞来限制它向其连接发送流量的速率。如果TCP发送方认为在自己和目的地之间的路径上几乎没有拥塞,那么TCP发送方就会提高发送速率;如果发送方察觉到路径上有拥塞,那么发送方就会降低它的发送速率。但这种方法引发了三个问题。首先,TCP发送方如何限制它向其连接发送流量的速率?第二,TCP发送方如何感知到在自己和目的地之间的路径上有拥塞?第三,发送方应该使用什么算法来改变它发送速率关于感知到的端到端拥塞的函数?
让我们首先检查TCP发送方是如何限制它向其连接发送流量的速率的。在第3.5节中,我们看到了TCP连接的每一端都由一个接收缓冲区、一个发送缓冲区和几个变量(LastByteRead、rwnd等)组成。在发送方运行的TCP拥塞控制机制会跟踪一个额外的变量,即 拥塞窗口 (congestion window)。拥塞窗口,即cwnd,对TCP发送方向网络发送流量的速率施加了约束。具体来说,发送方未确认的数据量不能超过cwnd和rwnd中较小的值,即:
LastByteSent – LastByteACKed <= min{cwnd, rwnd}
为了专注于拥塞控制(而不是流量控制),我们假设TCP接收缓冲区非常大,以至于接收窗口约束可以被忽略;因此,发送方未确认的数据量仅受cwnd限制。我们还假设发送方总是有数据要发送,也就是说,拥塞窗口中的所有段都被发送。
上面的约束限制了发送方未确认数据的数量,因此间接地限制了发送方的发送速率。为了了解这一点,考虑一个丢包和传输延迟可以忽略不计的连接。然后,大约在每个RTT开始时,约束允许发送方发送cwnd字节的数据到连接;在RTT结束时,发送方收到对数据的确认。因此,发送方的发送速率大约是cwnd/RTT字节/秒。通过调整cwnd的值,发送方可以因此调整向其连接发送数据的速率。
接下来,让我们考虑TCP发送方是如何感知到自己和目的地之间的路径上存在拥塞的。让我们将TCP发送方的"丢包事件"定义为发生超时或接收方收到三个重复的ACK。(回想一下我们在第3.5.4节中对图3.33中超时事件的讨论,以及随后的修改,包括在收到三个重复的ACK时进行快速重传。)当出现过度拥塞时,沿着路径的一个(或多个)路由器缓冲区就会溢出,导致数据报(包含一个TCP段)被丢弃。丢弃的数据报反过来导致发送方出现丢包事件,要么是超时,要么是接收到三个重复的ACK,这被发送方认为是发送方到接收方路径上的拥塞迹象。
考虑了拥塞是如何检测的,接下来让我们考虑网络无拥塞时比较乐观的情况,即当丢包事件不发生时。在这种情况下,TCP发送方将收到之前未被确认的段的确认。我们会看到,TCP将把这些到达的确认作为一切正常的指示——传送到网络的段被成功地交付到目的地——并且将使用确认来增加其拥塞窗口的大小(从而增加其传输速率)。注意,如果确认到达的速度相对较慢(例如,如果端到端路径有较高的延迟或包含一个低带宽的链路),那么拥塞窗口将以一个相对较慢的速度增加。另一方面,如果确认到达的速率较高,则拥塞窗口会增加得更快。因为TCP使用确认来触发(或clock)拥塞窗口大小的增加,所以TCP被称为 自同步 (self-clocking)。
给出了调整cwnd值来控制发送速率的机制,关键的问题仍然存在:TCP发送方应该如何确定它应该发送的速率?如果TCP发送者们一起快速发送,他们会阻塞网络,导致我们在图3.48中看到的拥塞崩溃类型。事实上,我们即将研究的TCP版本是在早期TCP版本下,针对观察到的互联网拥塞崩溃而开发的[Jacobson 1988]。然而,如果TCP发送者过于谨慎和发送太慢,他们可能会对网络带宽利用不足;也就是说,TCP发送方可以在不阻塞网络的情况下以更高的速率发送。那么,TCP发送方如何确定它们的发送速率,以使它们在不拥塞网络的同时利用所有可用带宽?或者是否存在一种分布式方法,使TCP发送方可以仅根据本地信息设置其发送速率?TCP使用以下指导原则回答了这些问题:
- 一个丢失的段意味着拥塞,因此,当一个段丢失时,TCP发送方的速率应该降低 。回忆我们在3.5.4节的讨论,一个超时事件或一个给定段的四个确认(一个原始ACK和三个重复ACK)的收据被解释为隐式的丢包事件,指示该给定段后面的段,触发丢失段的重传。从拥塞控制的角度来看,问题是TCP发送方应该如何减少其拥塞窗口大小,从而降低其发送速率,以响应这个推断的丢包事件。
- 确认的段表明网络正在将发送方的段发送给接收方,因此,当之前未确认的段收到ACK时,发送方的速率可以提高。 确认的到达隐式的意味着一切都好——段被成功地从发送方交付给接收方,因此网络没有拥塞。因此拥塞窗口的大小可以增加。
- 带宽探针 倘若ACK指示源到目的地无拥塞,丢包事件指示路径拥塞,TCP的调整策略是提高传输速率以响应到达的ACK直到丢包事件发生,此时传输速率降低。因此,TCP发送方提高其传输速率,以探测拥塞开始的速率,然后从该速率后退,然后再次开始探测,以查看拥塞开始的速率是否发生了变化。TCP发送方的行为可能类似于请求(并得到)越来越多的糖果的孩子,直到最后他/她被告知“不!”,稍微后退一点,但不久之后又开始提出要求。请注意,网络没有明确的拥塞状态信号——ACK和丢包事件作为隐式信号——每个TCP发送方都异步地处理来自其他TCP发送方的本地信息。
鉴于TCP拥塞控制的概述,我们现在可以考虑著名的 TCP拥塞控制算法 的细节,该算法在[Jacobson 1988]中首次描述,并在[RFC 5681]中标准化。该算法有三个主要组成部分:(1)慢启动,(2)拥塞避免,(3)快速恢复。慢启动和拥塞避免是TCP的强制组件,不同的是它们如何增加拥塞窗口的大小来响应收到的ACK。我们很快就会看到,慢启动比拥塞避免更快(别管名字!)地增加了cwnd的大小。对于TCP发送方,建议快速恢复,但不是必需的。
慢启动
当TCP连接开始时,cwnd的值通常被初始化为一个很小的值:1 MSS [RFC 3390],导致初始发送速率大致为MSS/ RTT。例如,如果MSS = 500字节和RTT = 200 msec,那么初始发送速率只有大约20 kbps。由于TCP发送方的可用带宽可能比MSS/RTT大得多,所以TCP发送方希望快速找到可用带宽的数量。因此,在 慢启动(slow-start) 状态下,cwnd的值从1 MSS开始,并在每次发送的段首次确认时增加1 MSS。在图3.50的例子中,TCP将第一个段发送到网络并等待确认。当这个确认到达时,TCP发送方将拥塞窗口增加一个MSS,并发送两个最大长度的段。然后这些段被确认,发送方为每个确认的段增加1 MSS的拥塞窗口,给出4 MSS的拥塞窗口,以此类推。这个过程导致每次RTT发送速率翻倍。因此,TCP的发送速率启动缓慢,但在慢启动阶段呈指数级增长。
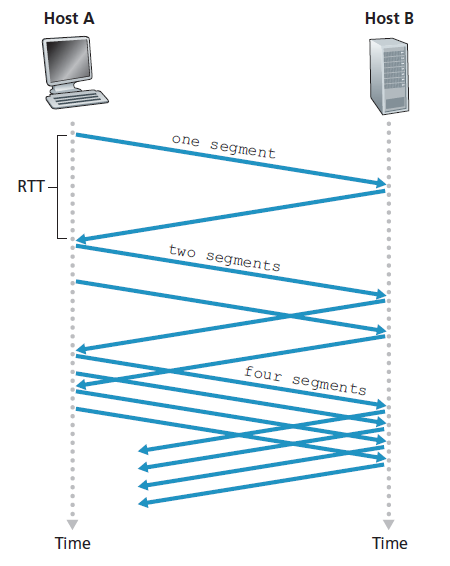
但这种指数增长何时结束呢?慢启动为这个问题提供了几个答案。首先,如果有一个由超时指示的丢包事件(即拥塞),TCP发送方将cwnd的值设置为1,并重新开始慢启动进程。它还将第二个状态变量:ssthresh的值(slow start threshold)设置为cwnd/2,即检测到拥塞时拥塞窗口值的一半。慢启动结束的第二种方式直接与ssthresh的值相关。由于在最后一次检测到拥塞时,ssthresh是cwnd值的一半,所以当cwnd值达到或超过ssthresh时,继续翻倍可能有点鲁莽!因此,当cwnd的值等于ssthresh时,慢启动结束,TCP进入拥塞避免模式。正如我们将看到的,TCP在拥塞避免模式下更谨慎地增加拥塞限制。慢启动结束的最后一种方式是检测到三个重复的ack,此时TCP进行快速重传(参见3.5.4节)并进入快速恢复状态,如下所述。图3.51中FSM对TCP拥塞控制的描述概括了TCP慢启动时的行为。慢启动算法可以追溯到[Jacobson 1988];类似于慢启动的方法也在[Jain 1986]中独立提出。
拥塞避免
在进入拥塞避免状态时,cwnd的值大约是上次遇到拥塞时其值的一半——拥塞可能就在拐角处!因此,TCP采用更保守的方法,每一个RTT只增加一个MSS,而不是每一个RTT将cwnd值加倍[RFC 5681]。这可以通过几种方式实现。对于TCP发送方来说,一种常见的方法是每当有新的确认到达时,将cwnd增加MSS×(MSS/cwnd)。例如,如果MSS是1460字节,cwnd是14600,然后在RTT内发送10个段。每收到一个ACK(假设每个段有一个ACK),拥塞窗口的大小就增加1/10 MSS,因此,当所有10个段都收到ACK后,拥塞窗口的值将增加1 MSS。
但是什么时候结束拥塞避免的线性增加(每RTT增加1 MSS)?TCP的拥塞避免算法在超时时的行为与慢启动时的行为相同:cwnd的值设置为1MSS,当丢包事件发生时,ssthresh的值更新为cwnd值的一半。但是,请记住,丢包事件也可以由三个重复的ACK事件触发。
在这种情况下,网络继续从发送方向接收方发送一些段(由收到重复的ACK收据表示)。所以TCP这种类型的丢包事件的行为比超时指示(timeout-indicated)丢包事件少些极端:TCP将cwnd值减半(由于接收到三个重复ACK,导致增加了3个MSS)且当接受到三个重复ACK时记录cwnd的半值到ssthresh。随后进入快速恢复状态。
案例之——TCP拆分:优化云服务性能
对于搜索、电子邮件和社交网络等云服务,最好是提供高水平的响应能力,理想情况下,给用户一种服务运行在他们自己的终端系统(包括智能手机)中的错觉。这可能是一个主要的挑战,因为用户通常远离负责提供与云服务相关的动态内容的数据中心。实际上,如果终端系统远离数据中心,那么RTT将很大,可能会由于TCP慢启动响应时间过长而导致性能较差。
作为一个案例研究,考虑接收一个搜索查询响应的延迟。通常,服务器在慢启动到交付响应期间需要三个TCP窗口[Pathak 2010]。因此从当系统启动TCP连接,直到时间结束接收到最后一个数据包响应时,大约是4 * RTT (1RTT设置TCP连接+ 3 RTT的三个窗口的数据)+数据中心的处理时间。这些RTT延迟会导致在返回大部分查询的搜索结果时出现明显的延迟。此外,在接入网络中可能会出现严重的丢包,从而导致TCP重传和更大的延迟。
缓解这一问题并提高用户感知性能的一种方法是(1)将前端服务器部署在离用户更近的地方,(2)在前端服务器上通过断开(breaking)TCP连接,即 TCP分离(TCP splitting) 。使用TCP分离,客户端建立一个TCP连接到附近的前端,且前端使用一个非常大的TCP拥塞窗口维护一个到数据中心的持久TCP连接,[Tariq 2008, Pathak 2010, Chen 2011]。使用这种方法,响应时间大致变成4 * RTTFE + RTTBE +处理时间,其中RTTFE是客户端和前端服务器之间的往返时间,RTTBE是前端服务器和数据中心(后端服务器)之间的往返时间。如果前端服务器接近客户端,那么这个响应时间大约变成RTT加上处理时间,因为RTTFE可以忽略不计,而RTTBE大约是RTT。综上所述,TCP分离可以将网络延迟大致从4 * RTT减少到RTT,显著提高用户感知性能,特别是对于远离最近的数据中心的用户。TCP分离还有助于减少由于接入网络的丢包而导致的TCP重传延迟。谷歌和Akamai在接入网络中广泛使用了他们的CDN服务器(回想一下我们在章节2.6中的讨论),对他们支持的云服务执行TCP分离[Chen 2011]。
快速恢复
在快速恢复中,对于导致TCP进入快速恢复状态的丢失的段,每收到一个重复的ACK, cwnd的值就增加1 MSS。最终,当一个丢失的段的ACK到达时,TCP在收缩拥塞窗口后进入拥塞避免状态。如果发生超时事件,在执行与慢启动和拥塞避免相同的操作后,快速恢复转换到慢启动状态:将cwnd的值设置为1MSS,将ssthresh的值设置为cwnd值的一半。
建议使用快速恢复,但不是必需的。有趣的是,早期版本的TCP,即 TCP Tahoe ,无条件地将其拥塞窗口削减到1 MSS,并在超时指示或三个重复ACK指示丢包事件后进入慢启动阶段。TCP的新版本, TCP Reno ,合并了快速恢复。
图3.52说明了TCP拥塞窗口在Reno和Tahoe上的演化。在该图中,阈值最初等于8 MSS。对于前八轮传输,Tahoe和Reno采取相同的行动。拥塞窗口在慢启动时呈指数级增长,并在第四轮传输时达到阈值。然后拥塞窗口线性上升,直到第8轮传输后出现三次重复ACK事件。注意,当这个丢包事件发生时,拥塞窗口是12 MSS。然后将ssthresh的值设置为0.5 * cwnd = 6 MSS。在TCP Reno下,拥塞窗口被设置为cwnd = 9 MSS,然后线性增长。在TCP Tahoe下,拥塞窗口被设置为1MSS,并呈指数增长,直到达到ssthresh的值,此时拥塞窗口线性增长。
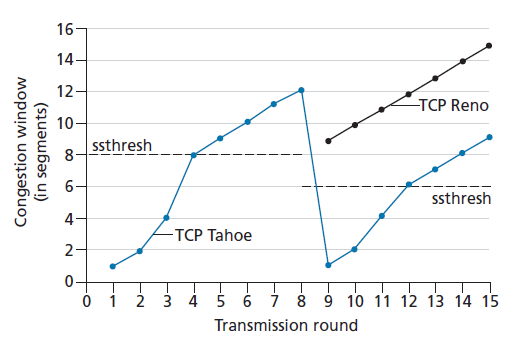
图3.51给出了对TCP拥塞控制算法的完整FSM描述:慢启动、拥塞避免和快速恢复。该图还指示在何处可以发生新段或重传段的传输。尽管区分TCP错误控制/重传和TCP拥塞控制很重要,但理解TCP的这两个方面是如何不可分割地联系在一起的也很重要。
TCP拥塞控制:回溯
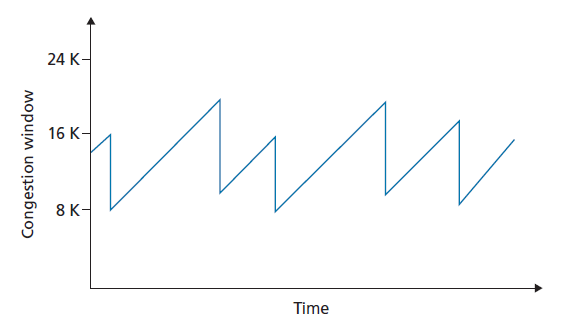
在深入研究了慢启动、拥塞避免和快速恢复的细节后,现在有必要退一步,从树木看森林。忽略连接开始时初始的慢启动期,并假设丢包是由三个重复的ACK指示的,而不是超时,TCP拥塞控制由:每个RTT将cwnd线性增加1MSS(加),和在一个三个重复ACK事件上将cwnd减半(减)。出于这个原因,TCP拥塞控制通常被称为一种 可加可减(AIMD,additive-increase, multiplicative decrease) 形式的拥塞控制。AIMD拥塞控制产生了如图3.53所示的锯齿状行为,这也很好地说明了我们之前对TCP带宽探测的直觉——TCP线性地增加它的拥塞窗口大小(以及它的传输速率),直到发生三次重复ACK事件。然后,它将拥塞窗口的大小减半,然后再次开始线性增加,探测是否有额外的可用带宽。
TCP的AIMD算法是在大量工程研究和操作网络拥塞控制实验的基础上发展起来的。TCP发展十年后,理论分析表明,TCP的拥塞控制算法作为一种分布式异步优化算法,导致用户和网络性能的几个重要方面同时得到优化[Kelly 1998]。此后出现了丰富的拥塞控制理论[Srikant 2012]。
TCP Cubic
考虑到TCP Reno在拥塞控制中采用的加法增加、乘法减少的方法,人们自然会想,这是否是探测刚好低于触发丢包阈值的数据包发送速率的最佳方法。实际上,将发送速率降低一半(或者更糟,将发送速率降低到每个RTT一个数据包,就像早期版本的TCP(即TCP Tahoe)中那样),然后随着时间的推移缓慢增加,可能过于谨慎。如果发生丢包的拥塞链路的状态变化不大,那么可能最好更快地提高发送速率,使其接近丢包前的发送速率,然后谨慎地探测带宽。这种洞察力是TCP的核心,即TCP CUBIC [Ha 2008, RFC 8312]。
TCP CUBIC与TCP Reno只有细微的区别。同样,拥塞窗口只在收到ACK时增加,慢启动和快速恢复阶段保持不变。CUBIC只改变拥塞避免阶段,如下所示:
- 设Wmax为上次检测到丢包时TCP拥塞控制窗口的大小,K为TCP CUBIC窗口大小再次达到Wmax的未来某个时刻点,假设没有丢包。几个可调的(tunable)CUBIC参数决定了K值,即协议的拥塞窗口大小达到Wmax的速度。
- CUBIC以当前时间t和K之间距离的立方的函数来增加拥塞窗口,因此,当t远离K时,拥塞窗口大小的增长远远大于当t接近K时,立方迅速加大TCP发送速率以接近丢包前(pre-loss)的速率Wmax,只有当带宽接近Wmax时才会谨慎地探测带宽。
- 当t比K大时,且当t仍接近K时根据立方规则意味着CUBIC的拥塞窗口的增加很小,(如果链路的拥堵没造成多少丢包)然后迅速增加的t超过K(立方可以更快地找到一个新的操作点如果链路的拥堵程度造成的丢包很严重)。
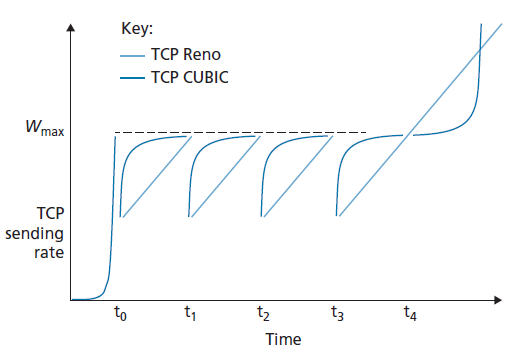
在这些规则下,TCP Reno和TCP CUBIC的理想性能比较如图3.54所示,改编自[Huston 2017]。我们看到慢启动阶段结束于t0。然后,当t1、t2和t3发生拥塞丢包时,CUBIC更快地上升到接近Wmax(因此比TCP Reno享有更多的总吞吐量)。我们可以从图形上看到TCP CUBIC是如何尽可能长时间地保持流量低于(发送方未知的)拥塞阈值的。注意,在t3时,拥塞程度可能已经明显下降,允许TCP Reno和TCP CUBIC都达到比Wmax更高的发送速率。
TCP CUBIC最近得到了广泛的部署。同时测量了大约2000个流行的Web服务器表明,几乎所有服务器都运行TCP Reno的某些版本(Padhye 2001),最近测量的近5000个最流行的Web服务器表明,近50%的服务器运行TCP CUBIC版本[Yang 2014],这也是Linux操作系统中默认使用的TCP版本。
TCP Reno吞吐量的宏观描述
考虑到TCP Reno的锯齿状行为,很自然地要考虑一个TCP Reno长连接的平均吞吐量(即平均速率)可能是多少。在此分析中,我们将忽略超时事件之后出现的慢启动阶段。(这些阶段通常非常短,因为发送方在这个阶段以指数级的速度增长。)在一个特定的往返间隔期间,TCP发送数据的速率是拥塞窗口和当前RTT的函数。当窗口大小为w字节,且往返时间为RTT秒时,则TCP的传输速率大致为w/RTT。然后TCP通过每个RTT增加1 MSS来探测额外的带宽,直到出现丢包事件。用W表示丢包事件发生时w的值。假设RTT和W在连接持续时间内近似恒定,则TCP传输速率的取值范围为W/(2*RTT) ~ W/RTT。
这些假设导致了TCP稳态行为(steadystate behavior)的一个高度简化的宏观模型。当速率增加到W/RTT,网络从连接中丢包时;速率将减半,然后在每个RTT中增加MSS/RTT,直到再次达到W/RTT。这个过程一遍又一遍地重复。因为TCP的吞吐量(即速率)在两个极值之间线性增长,我们有:
连接平均吞吐量 = 0.75 * W / RTT
网络辅助的显式拥塞通知和基于延迟的拥塞控制
因为慢启动和拥塞避免是在19世纪80年代标准化的(RFC 1122),TCP实现了我们在章节3.7.1中所研究的端到端拥塞控制的形式:TCP发送方没有接受到来自网络层的显式拥塞迹象,而通过观察丢包推断拥塞。最近,对IP和TCP的扩展[RFC3168]被提出、实现和部署,允许网络显式地向TCP发送方和接收方发送拥塞信号。此外,已经提出了许多TCP拥塞控制协议的变体,它们使用测量的数据包延迟来推断拥塞。在本节中,我们将研究网络辅助(network-assisted)的拥塞控制和基于延迟的拥塞控制。
显式拥塞通知
Explicit Congestion Notification[RFC 3168]是Internet内执行的网络辅助拥塞控制的形式。如图3.55所示,TCP和IP都涉及到。在网络层,IP数据报头(我们将在4.3节讨论)的Type of Service字段中的两比特(总体上有四个可能的值)被用于ECN。
路由器使用ECN比特的一种设置来表示其正在经历拥塞。这个拥塞指示随后以IP数据报标记的形式交付给目标主机,然后目标主机通知发送主机,如图3.55所示。RFC 3168没有提供路由器拥塞的定义;这个决定是由路由器供应商和网络运营商做出的配置选择。然而,直觉上,拥塞指示比特可以设置为在实际丢包发生之前向发送方发出拥塞开始的信号。第二种ECN比特的设置是由发送主机用来通知路由器发送方和接收方有ECN能力,从而能够对ECN指示的网络拥塞采取行动。
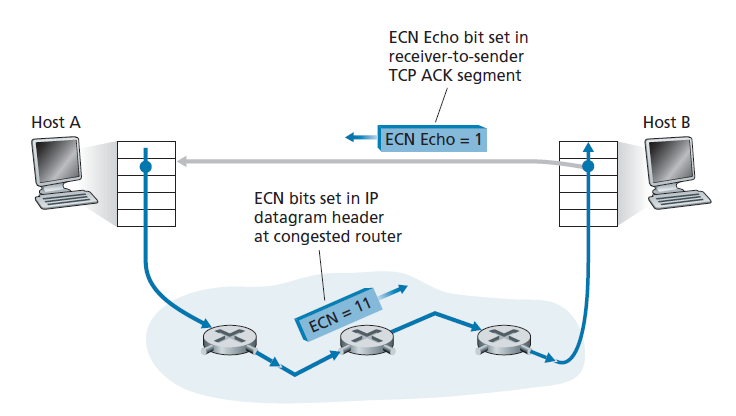
如图3.55所示,当接收主机接收到ECN的TCP拥塞指示(通过接收到的数据报),接收主机的TCP通过在接收方到发送方的TCP ACK段中设置ECE(ECN Echo)比特来通知发送主机(见图3.29)。TCP发送方,相应地,通过将拥塞窗口减半来响应ACK,因为它会使用快速重传来响应丢失的段,并在发送方到接收方的下一个传输的TCP段头中设置CWR(Congestion Window Reduced)比特。
除了TCP之外,其他传输层协议也可以利用网络层信号的(networklayer-signaled)ECN。数据报拥塞控制协议(DCCP,Datagram Congestion Control Protocol) [RFC 4340]提供了一种低开销、拥塞控制的类似UDP的使用ECN的不可靠服务。DCTCP(Data Center TCP) [Alizadeh 2010, RFC 8257]和DCQCN(Data Center Quantized Congestion Notification)[Zhu 2015]专为数据中心网络设计,也使用了ECN。最近的互联网测量显示,ECN功能在流行服务器以及通往这些服务器的路由器上的部署越来越多[Kühlewind 2013]。
Delay-based拥塞控制
在我们上面的ECN讨论中,一个拥塞的路由器可以设置拥塞指示比特,在填满缓冲区导致数据包在该路由器被丢弃之前,向发送方发出拥塞开始的信号。这允许发送方更早地降低发送速率,最好是在丢包之前,从而避免开销高昂的丢包和重传。第二种拥塞避免方法采用基于延迟的方法,也在丢包发生之前主动检测拥塞发生。
在TCP Vegas [Brakmo 1995]中,发送方测量源到目的地路径所有已确认的数据包的RTT。设RTTmin为这些测量值的最小值;这种情况发生在路径上没有拥塞和数据包经历最小的排队延迟时。如果TCP Vegas拥塞窗口大小为cwnd,则无拥塞吞吐量速率为cwnd/RTTmin。TCP Vegas背后的直觉是,如果实际的发送方测量的吞吐量接近这个值,那么TCP发送速率可以提高,因为(根据定义和测量)路径上还没有拥塞。然而,如果实际发送方测量的吞吐量明显低于未拥塞的吞吐量速率,则路径会拥塞,Vegas TCP发送方会降低其发送速率。详情见[Brakmo 1995]。
TCP Vegas执行的判断是,TCP发送方应该“Keep the pipe just full, but no fuller”[Kleinrock 2018]。“Keeping the pipe full”意味着链路(特别是限制连接吞吐量的瓶颈链路)一直忙于传输,做有用的工作;“but no fuller”意味着,如果在管道被填满的情况下允许建立大型队列,那么没有任何好处(除了增加的延迟!)。
BBR拥塞控制协议[Cardwell 2017]建立在TCP Vegas的思想上,并结合了允许其与TCP非BBR发送方公平竞争的机制(见章节3.7.3)。[Cardwell 2017]报告称,2016年,谷歌开始在其私有B4网络[Jain 2013]上对所有TCP流量使用BBR,该网络连接谷歌数据中心,取代CUBIC。它也被部署在谷歌和YouTube的Web服务器上。其他基于延迟的TCP拥塞控制协议包括用于数据中心网络的TIMELY协议[Mittal 2015],以及用于高速和长途网络的Compound TCP (CTPC) [Tan 2006]和FAST [Wei 2006]。
3.73 公平
考虑K个TCP连接,每个都有不同的端到端路径,但都通过一个传输速率为R bps的瓶颈链路。(所谓瓶颈链路,是指对于每个连接,该连接路径上的所有其他链路都没有拥塞,且与瓶颈链路的传输能力相比,具有更大的传输能力。)假设每个连接都在传输一个大文件,并且没有UDP流量通过瓶颈链路。当每个连接的平均传输速率大约为R/K时,拥塞控制机制被认为是公平的;也就是说,每个连接都得到相同份额的链路带宽。
TCP的AIMD算法公平吗?特别是考虑到不同的TCP连接可能在不同的时间开始,因此在给定的时间点可能有不同的窗口大小。[Chiu 1989]给出了一个优雅而直观的解释,解释了为什么TCP拥塞控制会收敛,从而在竞争的TCP连接之间提供均等的共享瓶颈链路带宽。
让我们考虑两个TCP连接共享一条链路的简单情况,传输速率为R,如图3.55所示。假设两个连接有相同的MSS和RTT(因此,如果它们有相同的拥塞窗口大小,那么它们有相同的吞吐量),它们有大量的数据要发送,并且没有其他TCP连接或UDP数据报经过这个共享链路。另外,忽略TCP的慢启动阶段,假设TCP连接一直在CA模式(AIMD)下运行。
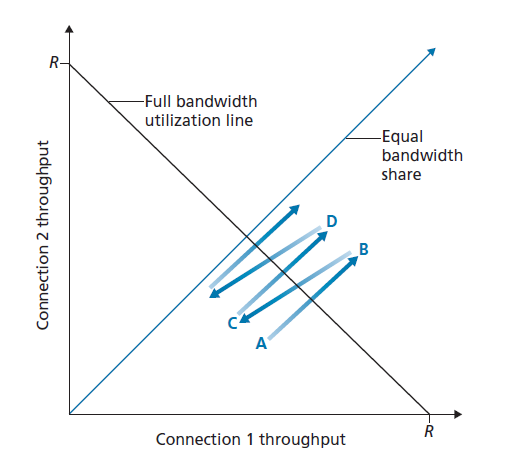
图3.56绘制了两个TCP连接实现的吞吐量。如果TCP要在两个连接之间平均共享链路带宽,然后实现的吞吐量应该沿着从原点发出的45度箭头(Equal bandwidth share)上升(图3.57)。理想情况下,两个吞吐量的和应该等于R。(当然,每个连接接受相等的,非0的链路容量份额不是一个理想的情况!)因此,目标应该是使实现的吞吐量落在图3.57中Equal bandwidth share线和Full bandwidth utilization line线的交点附近。
假设TCP窗口大小是这样的,在给定的时间点,连接1和连接2实现图3.57中点A所示的吞吐量。由于两个连接共同消耗的链路带宽小于R,因此不会发生丢包,并且由于TCP的拥塞避免算法,两个连接的窗口每个RTT都会增加1 MSS。因此,两个连接的联合吞吐量从A点开始沿45度线(两个连接都等额增加)进行,最终两个连接共同消耗的链路带宽将大于R,最终出现丢包。假设连接1和连接2在实现B点指示的吞吐量时经历了丢包。连接1和连接2将它们的窗口减小到原来的一半。最终实现的吞吐量是在点C。因为在C点的联合带宽使用小于R,两个连接再次从点C沿45度线增加吞吐量。最终,丢包将再次发生。例如,在点D,两个连接再次减半窗口大小,等等。您应该说服自己,两个连接实现的带宽最终会沿着相等的带宽共享线波动。您还应该说服自己,无论它们在二维空间中的哪个位置,这两个连接都将汇聚到这种行为中!尽管这个场景背后有许多理想化的假设,但它仍然提供了一种直观的感觉,即为什么TCP会导致连接之间平均共享带宽。
在我们的理想场景中,我们假设只有TCP连接通过瓶颈链路,这些连接具有相同的RTT值,并且只有一个TCP连接与主机-目的地对关联。在实践中,这些条件通常得不到满足,因此客户端-服务器应用程序可以获得非常不均的链路带宽。特别是,当多个连接共享一个共同的瓶颈链路时,那些具有较小RTT的会话能够更快地获取该链路上的可用带宽,因为它变得自由(也就是说,更快地打开它们的拥塞窗口),因此将比那些具有较大RTT的连接享有更高的吞吐量[Lakshman 1997]。
公平和UDP
我们已经看到了TCP拥塞控制如何通过拥塞窗口机制来调节应用程序的传输速率。许多多媒体应用程序,如Internet电话和视频会议,通常不通过TCP运行,正是因为这个原因,即使网络非常拥挤,它们也不希望传输速率受到限制。相反,这些应用程序更喜欢在UDP上运行,因为UDP没有内置的拥塞控制。当在UDP上运行时,应用程序可以以恒定的速率将其音频和视频输入网络,偶尔会丢包,而不是在拥塞时将其速率降低到公平水平,而不丢包。从TCP的角度来看,在UDP上运行的多媒体应用是不公平的,它们不能与其他连接进行协作,也不能适当地调整传输速率。由于TCP拥塞控制会在拥塞(丢包)增加的情况下降低其传输速率,而UDP源则不需要,因此UDP源有可能挤出TCP流量。许多拥塞控制机制已经被提出,以阻止UDP流量带来互联网的吞吐量戛然而止[Floyd 1999;Floyd 2000; Kohler 2006; RFC 4340].。
TCP连接的公平性和并行性
但是,即使我们能够迫使UDP流量公平地运行,公平问题仍然不会完全解决。这是因为没有什么可以阻止基于TCP的应用程序使用多个并行连接。例如,Web浏览器经常使用多个并行TCP连接来传输Web页面中的多个对象。(在大多数浏览器中,多个连接的确切数量是可配置的。)当一个应用程序使用多个并行连接时,它在拥塞的链路中获得更大的带宽份额。例如,考虑一条速率为R的链路,它支持9个正在进行的客户端-服务器应用程序,每个应用程序使用一个TCP连接。如果一个新的应用程序出现,并且也使用一个TCP连接,那么每个应用程序的传输速率大约是R/10。但是,如果这个新应用程序使用11个并行TCP连接,那么这个新应用程序将得到一个大于R/2的不公平配额。由于Web流量在Internet中非常普遍,多个并行连接并不少见。
3.8 传输层功能的演变
在本章中,我们对特定Internet传输协议的讨论主要集中在UDP和TCP——这两个Internet传输层主力(work horses)上。然而,正如我们所看到的,使用这两个协议三十年的经验已经确定了两种协议都不适合的情况,因此传输层功能的设计和实现继续发展。
在过去的十年里,我们已经看到了TCP使用的丰富演变。在第3.7.1节和3.7.2节中,我们了解到,除了TCP的经典版本(如TCP Tahoe和Reno)外,现在还有几个较新的TCP版本,它们已经被开发、实现、部署,并在今天得到了广泛的应用。其中包括TCP CUBIC、DCTCP、CTCP、BBR等。事实上,[Yang 2014]的测量表明,CUBIC(及其前身,BIC [Xu 2004])和CTCP在Web服务器上的部署比经典的TCP Reno更广泛;我们也看到BBR被部署在谷歌的内部B4网络,以及谷歌的许多面向公众的服务器。
而且还有更多的TCP版本!有一些版本的TCP专门设计用于无线链路、高RTT大带宽的路径、数据包重排的路径,以及严格用于数据中心内的短路径。在竞争瓶颈链路带宽的TCP连接中,有不同版本的TCP实现了不同的优先级,对于在不同的源-目标路径上并行发送的TCP连接。还有一些TCP变体,它们处理数据包确认和TCP会话建立/关闭,与我们在第3.5.6节中研究的方式不同。事实上,它甚至可能不再是正确的TCP协议;也许这些协议唯一的共同特征是它们使用了我们在图3.29中研究过的TCP段格式,并且它们在面对网络拥塞时应该公平地相互竞争!关于TCP多种类型的调查,请参见[Afanasyev 2010]和[Narayan 2018]。
QUIC 快速UDP互联网连接
如果应用程序需要的传输服务不太适合UDP或TCP服务模型——可能应用程序需要比UDP提供的服务更多的,但不需要TCP附带的所有特定功能,或者可能需要与TCP提供的服务不同的服务——应用程序设计人员总是可以在应用层构建自己的(roll their own)协议。这是QUIC(Quick UDP Internet Connections)协议[Langley 2017, QUIC 2020]中采用的方法。具体来说,QUIC是一种全新的应用层协议,旨在提高安全HTTP传输层服务的性能。QUIC已经被广泛部署,尽管作为互联网RFC (QUIC 2020)仍处于标准化的过程中。谷歌已经在其许多面向公众的Web服务器上部署了QUIC,如移动视频流YouTube应用程序、Chrome浏览器、Android的谷歌搜索应用程序。如今超过7%的互联网流量是QUIC [Langley 2017],我们需要仔细研究。我们对QUIC的研究也将成为我们对传输层研究的一个很好的高潮,因为QUIC使用了许多可靠的数据传输、拥塞控制和连接管理的方法,这些我们在本章中已经学习过。
如图3.58所示,QUIC是一个应用层协议,使用UDP作为其底层的传输层协议,并被设计用于简化并改进HTTP/2版本之上的接口。在不久的将来,HTTP/3将会与QUIC合并[HTTP/3 2020]。QUIC的一些主要功能包括:
- 面向连接和安全(Connection-Oriented and Secure) 像TCP一样,QUIC是两个端点之间的面向连接的协议。这需要端点之间的握手来设置QUIC连接状态。连接状态的两个部分是源连接ID和目标连接ID。所有的QUIC数据包都是加密的,如图3.58所示,QUIC结合了建立连接状态所需的握手和认证与加密所需的握手(传输层安全主题,我们将在第8章中研究),因此提供了比图3.58(a)中协议栈更快的建立,其需要多个RTT先建立一个TCP连接,然后再通过TCP连接建立一个TLS连接。
- 流(Streams) QUIC允许多个不同的应用级“流”通过一个QUIC连接进行多路复用,并且一旦建立了一个QUIC连接,新的流就可以快速添加。流是两个QUIC端点之间可靠的、按顺序的双向数据交付的抽象。在HTTP/3坏境中,Web页面中的每个对象都有不同的流。每个连接都有一个连接ID,连接中的每个流都有一个流ID;这两个id都包含在一个QUIC数据包头中(以及其他头信息)。来自多个流的数据可能包含在一个单一的QUIC段中,它是通过UDP进行的。流控传输协议(SCTP)是一个早期的可靠的、面向消息的协议,它开创了通过单个SCTP连接多路复用多个应用级流的概念。我们将在第7章中看到SCTP被用于4G/5G蜂窝无线网络的控制平面协议。
- 可靠、TCP友好、拥塞控制的数据传输(Reliable, TCP-friendly congestion-controlled data transfer) 如图3.59(b)所示,QUIC分别向每个QUIC流提供可靠的数据传输。图3.59(a)显示了HTTP/1.1在单个TCP连接上发送多个HTTP请求的情况。由于TCP提供了可靠的、按顺序的字节交付,这意味着多个HTTP请求必须在目标HTTP服务器上按顺序交付。因此,如果一个HTTP请求的字节丢失了,那么剩下的HTTP请求将无法被交付,直到这些丢失的字节被HTTP服务器的TCP重传并正确接收,也就是我们在2.2.5节中遇到的所谓的HOL(Head of Line)阻塞问题。由于QUIC在逐流(per-stream)的基础上提供了一个可靠的按顺序的交付,一个丢失的UDP段只影响那些承载该数据的段的流;其他流中的HTTP消息可以继续被接收并交付给应用程序。QUIC通过类似于TCP的确认机制提供可靠的数据传输,如[RFC 5681]所述。
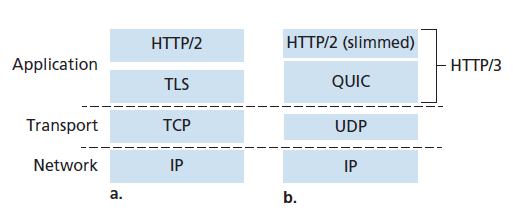
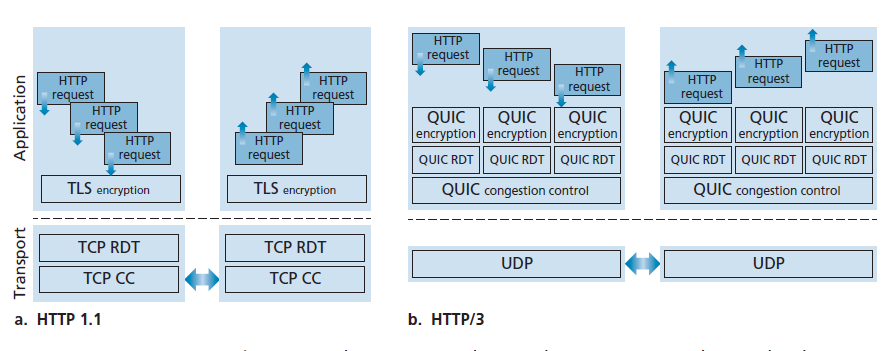 图3.59 (a) HTTP/1.1:单连接的客户端和服务器使用应用级TLS加密的TCP的可靠数据传输(RDT)和拥塞控制(CC)
图3.59 (a) HTTP/1.1:单连接的客户端和服务器使用应用级TLS加密的TCP的可靠数据传输(RDT)和拥塞控制(CC)
(b)HTTP/3:一个多流(multi-stream)客户端和服务器使用QUIC的加密,可靠的数据传输和拥塞控制的UDP不可靠数据报服务
QUIC的拥塞控制基于TCP NewReno [RFC 6582],对我们在3.7.1节中研究的TCP Reno协议进行了轻微的修改。QUIC的草案规范[QUIC-recovery 2020]说明“熟悉TCP丢失检测和拥塞控制的读者会发现这里的算法与TCP的非常相似”。由于我们已经在第3.7.1节中仔细研究了TCP的拥塞控制,我们读QUIC的拥塞控制算法规范草案的细节就像在家里一样!
最后,值得再次强调的是,QUIC是一种应用层协议,在两个端点之间提供可靠的、拥塞控制的数据传输。QUIC [Langley 2017]的作者强调,这意味着QUIC可以以应用程序更新时标“application-update timescales”做出改变,也就是说,比TCP或UDP更新时标更快。
3.9 总结
在本章开始时,我们研究了传输层协议可以为网络应用程序提供的服务。在一种极端情况下,传输层协议可以非常简单,为应用程序提供无装饰(no-frills)的服务,仅为通信进程提供多路复用/解复用功能。因特网的UDP协议就是这样一个简单的传输层协议的例子。在另一个极端情况下,传输层协议可以为应用程序提供各种保证,例如可靠的数据传递、延迟保证和带宽保证。然而,传输协议所能提供的服务常常受到底层网络层协议的服务模型的限制。如果网络层协议不能为传输层段提供延迟或带宽保证,那么传输层协议就不能为进程之间发送的消息提供延迟或带宽保证。
我们在第3.4节中了解到,即使底层网络层不可靠,传输层协议也可以提供可靠的数据传输。我们看到,提供可靠的数据传输有许多微妙之处,但是可以通过仔细组合确认、计时器、重传和序列号来完成任务。
虽然我们在本章中讨论了可靠的数据传输,但我们应该记住,可靠的数据传输可以由链路协议、网络协议、传输协议或应用层协议提供。协议栈的上面四层中的任何一层都可以实现确认、计时器、重传和序列号,并向上面一层提供可靠的数据传输。事实上,多年来,工程师和计算机科学家已经独立地设计和实现了链路、网络、传输和应用层协议,这些协议提供了可靠的数据传输(尽管其中许多协议已经悄然消失)。
在第3.5节中,我们详细介绍了TCP,一种面向Internet连接的可靠的传输层协议。我们了解到TCP是复杂的,包括连接管理、流控制、往返时间估计以及可靠的数据传输。事实上,TCP实际上比我们的描述更复杂——我们有意没有讨论各种各样的TCP补丁、修复和改进,它们在各种TCP版本中广泛实现。然而,所有这些复杂性对网络应用程序是隐藏的。如果一台主机上的客户端希望可靠地向另一台主机上的服务器发送数据,它只需向服务器打开一个TCP套接字,并将数据泵入该套接字。客户端-服务器应用程序很幸运地不知道TCP的复杂性。
在第3.6节中,我们从一个广泛的角度研究了拥塞控制,在第3.7节中,我们展示了TCP如何实现拥塞控制。我们了解到拥塞控制对于网络的健康发展是必不可少的。如果没有拥塞控制,网络很容易陷入僵局,端到端很少或根本没有数据传输。在3.7节中,我们了解到经典的TCP实现了端到端拥塞控制机制,当TCP连接的路径被判断为无拥塞时,加性增加了它的传输速率,当丢包发生时,成倍地降低了它的传输速率。这种机制也努力让每个通过拥塞链路的TCP连接共享链路带宽。我们还研究了TCP拥塞控制的几个更新的变体,它们试图比传统TCP更快地确定TCP的发送速率,使用基于延迟的方法或显式的网络拥塞通知(而不是基于丢包的方法)来确定TCP的发送速率。我们还深入研究了TCP连接建立和慢启动对延迟的影响。我们观察到,在许多重要的场景中,连接建立和慢启动显著地导致端到端延迟。我们再次强调,尽管TCP拥塞控制在过去几年中已经有所发展,但它仍然是一个需要深入研究的领域,并可能在未来几年继续发展。为了结束本章,在第3.8节中,我们研究了使用QUIC协议实现传输层许多功能的最新进展:可靠的数据传输、拥塞控制、连接建立等。