第一章 计算机网络与Internet
第一章 计算机网络与Internet
今天的互联网可以说是人类有史以来创造的最大的工程系统,有数亿台连接在一起的计算机、通信链路和交换机;数十亿用户通过笔记本电脑、平板电脑和智能手机连接;以及一系列新的联网产品,包括游戏机、监控系统、手表、眼镜、恒温器和汽车。考虑到互联网如此之大,有如此多不同的组件和用途,是否有希望了解它是如何工作的?有没有指导原则和结构可以为理解如此庞大和复杂的系统提供基础?如果是这样的话,学习计算机网络是不是非常有趣?幸运的是,所有这些问题的答案都是响亮的“是”!事实上,这正是本书的目的,为您提供计算机网络的动态领域的现代介绍,给您规范和切实可行的见解,您不仅需要了解如今的网络,还有未来的网络。
1.1 什么是Internet
Internet是一个计算机网络,它连接着全世界数十亿台计算设备。这些设备叫做主机(hosts)或端系统(end systems),如图所示:
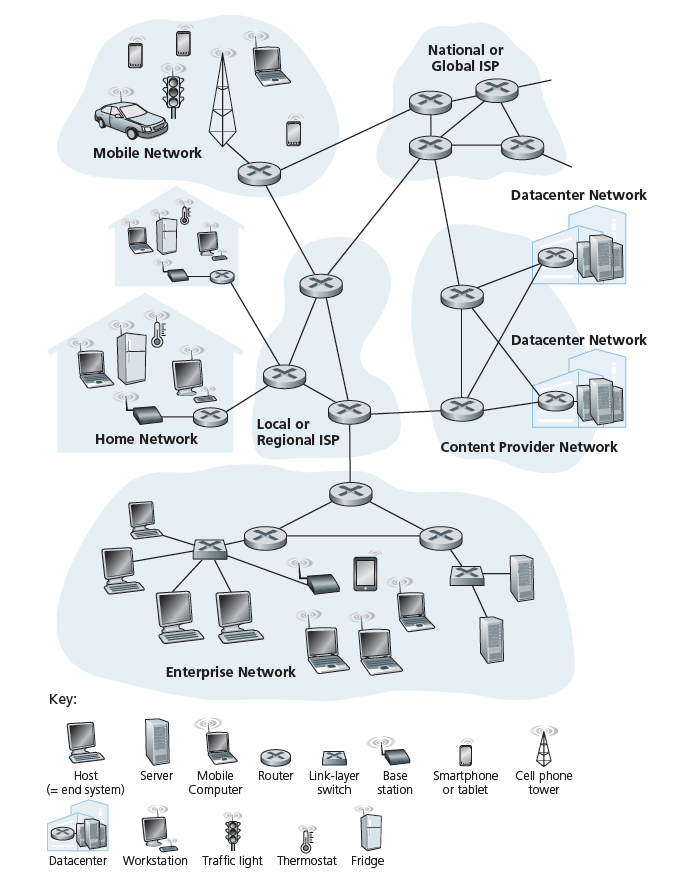
端系统由 通信链路(communication links) 和 数据包交换机(packet switches) 组成的网络连接在一起。在第1.2节中,我们将看到有许多类型的通信链路,它们是由不同类型的物理介质组成的,包括同轴电缆、铜线、光纤和无线电频谱。不同的链路可以以不同的速率传输数据,链路的 传输速率 以比特/秒为单位。当一个端系统有数据要发送到另一个端系统时,发送端系统将数据分段,并在每个段中添加头字节。由此产生的数据包,在计算机网络的行话中称为 数据包(packets) ,然后通过网络发送到目标端系统,在那里它们被重新组装成原始数据。
数据包交换机接受一条传入通信链路上的数据包,并在传出通信链路上转发该数据包。数据包交换机有许多形状和样式,但今天Internet中最突出的两种是 路由器 (routers)和 链路层交换机 (link-layer switches)。这两种类型的交换机都将数据包转发到它们的最终目的地。链路层交换机通常用于接入网络,而路由器通常用于网络核心。一个数据包从发送端系统到接收端系统所经过的通信链路和数据包交换机的顺序被称为通过网络的 路由(route) 或 路径(path) 。思科预测,到2022年,全球每年的IP流量将达到近5 zettabytes (1021!bytes)。
数据包交换机网络(它传输数据包)在许多方面类似于高速公路、公路和十字路口(它传输车辆)的运输网络。例如,一个工厂需要将大量货物运到位于数千公里以外的目的地仓库。在工厂里,货物被分成几部分,装上一队卡车。然后,每一辆卡车独立地通过高速公路、道路和十字路口到达目的地仓库。在目的地仓库,货物被卸下,并与来自同一批货物的其他货物组合在一起。因此,在许多方面,数据包类似于卡车,通信链路类似于高速公路和道路,数据包交换机类似于十字路口,端系统类似于建筑物。就像一辆卡车通过运输网络走一条路一样,一个数据包通过计算机网络也要走一条路。
端系统通过 互联网服务提供商 (ISP,Internet Service Providers)访问互联网,包括住宅ISP,如当地有线或电话公司;企业互联网服务提供商;大学互联网服务提供商;在机场、酒店、咖啡店等公共场所提供WiFi接入的互联网服务商;以及蜂窝数据ISP,为我们的智能手机和其他设备提供移动接入。每个ISP本身就是由数据包交换机和通信链路组成的网络。ISP为端系统提供各种类型的网络接入,包括住宅宽带接入,如有线调制解调器或DSL,高速局域网接入,以及移动无线接入。ISP也提供到内容提供商的互联网接入,将服务器直接连接到互联网。互联网就是把端系统相互连接起来,所以这些较低的ISP通过国内和国际的上层ISP相互连接,而这些上层ISP直接相互连接。一个上层ISP由高速路由器组成,这些路由器与高速光纤链路相互连接。每个ISP网络,无论是上层还是下层,都是独立管理的,运行IP协议(见下文),并符合特定的命名和地址约定。我们将在1.3节中更深入地研究ISP及其互连。
端系统、数据包交换机和Internet的其他部分运行控制Internet内信息发送和接收的协议。 传输控制协议(TCP,Transmission Control Protocol) 和 互联网协议(IP,Internet Protocol) 是Internet上两个最重要的协议。IP协议指定路由器和端系统之间发送和接收数据包的格式。Internet的主要协议统称为 TCP/IP 。我们将在本介绍性章节开始研究协议。但这只是一个开始——本书的大部分内容都是关于网络协议的!
鉴于协议对Internet的重要性,每个人对每个协议的作用达成一致是很重要的,这样人们就可以创建互操作的系统和产品。这就是标准发挥作用的地方。互联网标准是由互联网工程任务组(IETF,Internet Engineering Task Force) [IETF 2020]制定的。IETF标准文档称为 requests for comments(RFC) 。RFC一开始只是一般的征求意见(因此得名),以解决互联网前身所面临的网络和协议设计问题[Allman 2011]。RFC往往要有技术性和细节性。它们定义了TCP、IP、HTTP(用于Web)和SMTP(用于电子邮件)等协议。目前有近9000个RFC。其他机构还指定了网络组件的标准,尤其是网络链路的标准。例如,IEEE 802 LAN标准委员会[IEEE 802 2020]规定了以太网和无线WiFi的标准。
1.1.2 服务
我们上面的讨论已经确定了互联网的许多组成部分。但我们也可以从一个完全不同的角度来描述互联网——即作为一个为应用程序提供服务的基础设施。除了传统的应用程序,如电子邮件和网页浏览,互联网应用程序包括移动智能手机和平板电脑应用程序,包括互联网消息,实时道路交通信息地图,音乐流媒体电影和电视流媒体,在线社交媒体,视频会议,多人游戏,以及基于位置的推荐系统。这些应用程序被称为 分布式应用程序 ,因为它们涉及到相互交换数据的多个端系统。重要的是,Internet应用程序运行在端系统上——而不是运行在网络核心的数据包交换机上。尽管数据包交换机促进了端系统之间的数据交换,但它们并不关心作为数据源或数据槽的应用程序。
让我们进一步探讨一下为应用程序提供服务的基础设施的含义。为此,假设您有一个关于分布式Internet应用程序的令人兴奋的新想法,这个新想法可能会极大地造福人类,也可能只是让您变得富有和出名。如何将这个想法转化为实际的Internet应用程序呢?因为应用程序运行在端系统上,所以您将需要编写在端系统上运行的程序。例如,您可以用Java、C或Python编写程序。现在,由于您正在开发一个分布式Internet应用程序,在不同的端系统上运行的程序将需要相互发送数据。这里我们得到了一个中心问题,这个问题导致了另一种描述互联网为应用程序平台的方式。一个在一端系统上运行的程序如何指示Internet将数据传送到另一端系统上运行的另一个程序?
连接到Internet的端系统提供一个 套接字接口(socket interface) ,该接口指定在一系统上运行的程序如何要求Internet基础设施将数据传递到另一端系统上运行的特定目标程序。这个Internet套接字接口是发送程序必须遵循的一组规则,以便Internet能够将数据交付给目标程序。我们将在第二章详细讨论Internet套接字接口。现在,让我们用一个简单的比喻,一个我们在本书中经常使用的比喻。假设Alice想用邮政服务给Bob寄一封信。当然,Alice不能只是写一封信(数据),然后把信扔出窗口。相反,邮政部门要求Alice把信放在信封里;在信封中间写上Bob的全名、地址和邮政编码;密封信封;在信封的右上角贴上邮票;最后,把信封放进官方邮政服务的邮箱里。因此,邮政服务有自己的邮政服务接口,或一组规则,Alice必须遵循这些规则才能让邮政服务将她的信件发送给Bob。以类似的方式,Internet有一个套接字接口,发送数据的程序必须遵循该接口,以便Internet将数据交付给将接收数据的程序。
当然,邮政服务为其客户提供多种服务。它提供快递、接收确认、普通使用等多种服务。以类似的方式,Internet为其应用程序提供多种服务。当您开发Internet应用程序时,您也必须为您的应用程序选择一个Internet服务。我们将在第二章介绍Internet的服务。
我们刚刚给出了互联网的两种描述;一个是硬件和软件组件,另一个是为分布式应用程序提供服务的基础设施。但也许你仍然对Internet是什么感到困惑。什么是数据包交换和TCP/IP?路由器是什么?互联网上有哪些通信链路?什么是分布式应用程序?如何将恒温器或体重秤连接到互联网上?如果您现在感到有点不知所措,不要担心,这本书的目的是向您介绍互联网的螺母和螺栓,以及如何管理和为什么它会起作用。我们将在接下来的章节中解释这些重要的术语和问题。
1.1.3 什么是协议
现在我们已经对Internet有了一点感觉,让我们考虑计算机网络中另一个重要的流行词: 协议 。什么是协议?协议是做什么的?
一个人类的比喻
首先考虑一些人类的类比,可能最容易理解计算机网络协议的概念,因为我们人类一直在执行协议。考虑一下当你想问某人一天的时间时,你会怎么做。一个典型的交换如图1.2所示。人类礼仪(或良好的礼仪)指示人们首先用一个问候(下图中的第一个Hi)来开始与他人的交流。对Hi的典型响应是返回的Hi消息。然后,一个人含蓄地将一个亲切的Hi回应作为一个指示,他可以继续并询问时间。对第一个Hi的不同回应(例如Don’t bother me!或我不会说英语,或一些不宜发表的回复)可能表示不愿意或无法交流。在这种情况下,人类的协议将是不询问时间。有时,一个人对一个问题没有任何回应,在这种情况下,一个人通常放弃问那个人时间。请注意,在我们的人工协议中,有我们发送的特定消息,以及我们响应接收到的应答消息或其他事件(如在给定时间内没有应答)所采取的特定操作。显然,传输和接收的消息,以及在发送或接收这些消息或发生其他事件时所采取的行动,在人类协议中发挥着核心作用。如果人们运行不同的协议(例如,如果一个人有礼貌而另一个人没有,或者如果一个人理解时间的概念而另一个人不理解),协议就无法相互操作,也就无法完成任何有用的工作。在网络中也是如此,它需要两个(或更多)通信实体运行相同的协议来完成一个任务。
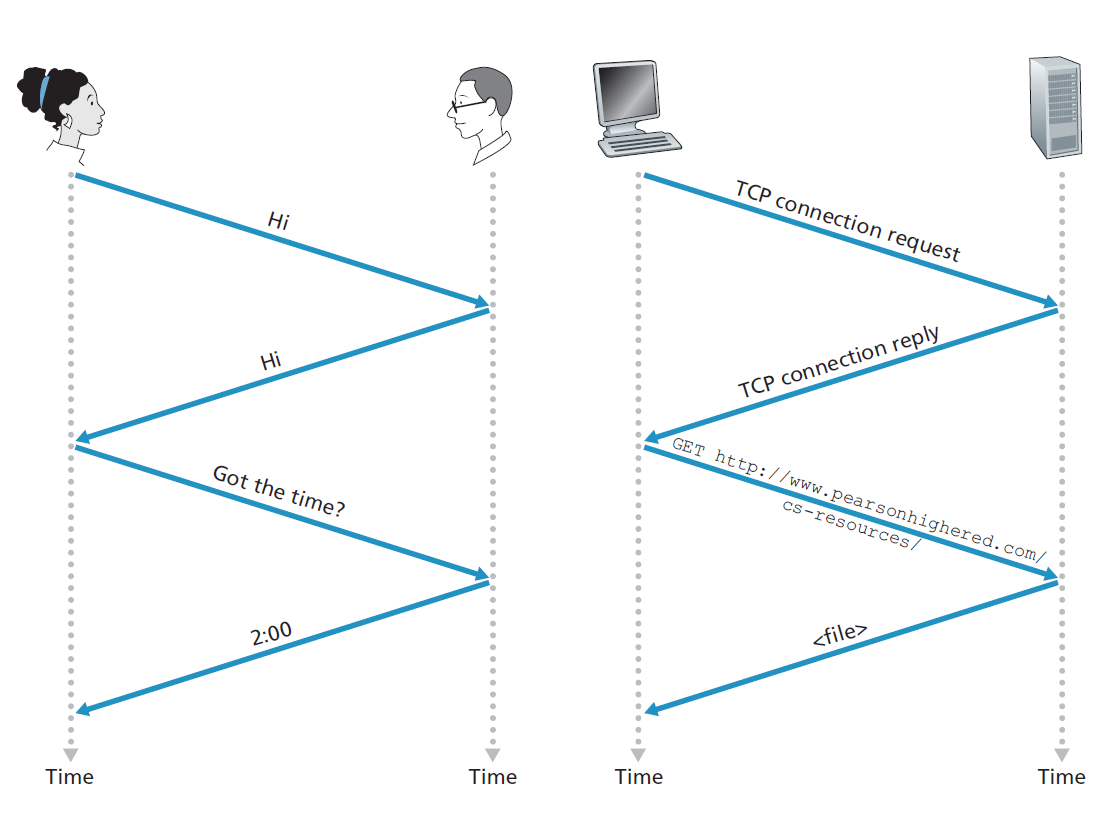
让我们考虑第二个人类类比。假设您在大学的一门课上(例如,计算机网络课)老师唠唠叨叨地讲规程,你感到很困惑。老师停下来问,有什么问题吗?(传递给所有不睡觉的学生,并由他们接收)。你举手(向老师传递一个隐含的信息)。你的老师微笑着承认你,说“yes”……(传递信息鼓励你问你的问题老师喜欢被问问题),然后你再问你的问题(即传递你的信息给你的老师)。你的老师听到你的问题(接收你的问题信息)和答案(发送一个答复给你)。再一次,我们看到信息的传输和接收,以及在发送和接收这些信息时所采取的一系列常规操作,是这个问答协议的核心。
网络协议
除了交换消息和采取行动的实体是某些设备(例如,计算机、智能手机、平板电脑、路由器或其他具有网络能力的设备)的硬件或软件组件外,网络协议与人类协议类似。Internet中涉及两个或多个远程通信实体的所有活动都由协议管理。例如,两个物理连接的计算机中的硬件实现的协议控制两个网络接口卡之间导线上的比特流;端系统中的拥塞控制协议控制数据包在发送方和接收方之间传输的速率;路由器中的协议决定数据包从源到目的地的路径。Internet上协议无处不在,因此本书的大部分内容都是关于计算机网络协议的。
作为您可能熟悉的计算机网络协议的一个示例,考虑一下向Web服务器发出请求时发生的情况,即在Web浏览器中输入Web页面的URL时。该场景在上图的右半部分中进行了说明。首先,您的计算机将向Web服务器发送连接请求消息并等待应答。Web服务器最终将收到您的连接请求消息并返回连接应答消息。知道现在可以请求Web文档了,计算机就会在GET消息中发送它想从该Web服务器获取的Web页面的名称。最后,Web服务器将Web页面(文件)返回到您的计算机。根据上面的人员和网络示例,在发送和接收这些消息时,消息的交换和所采取的操作是协议的关键:
协议定义了两个或多个通信实体之间交换的消息的格式和顺序,以及在传输或接收消息或其他事件时所采取的动作。
Internet和一般的计算机网络广泛地使用协议。不同的协议被用来完成不同的通信任务。当你阅读这本书的时候,你会了解到一些协议是简单和直接的,而另一些是复杂和深刻的。掌握计算机网络领域等同于理解网络协议的内容、原因和方式。
1.2 网络边缘
在前一节中,我们简要介绍了Internet和网络协议。现在我们将更深入地研究互联网的组成部分。我们从网络的边缘开始,看看我们最熟悉的组件——也就是我们日常使用的电脑、智能手机和其他设备。在下一节中,我们将从网络边缘转移到网络核心,并研究计算机网络中的交换和路由。
回想一下前面的部分,在计算机网络术语中,连接到Internet的计算机和其他设备通常被称为端系统。之所以被称为端系统,因为它们位于Internet的边缘,如下图所示。因特网的端系统包括台式电脑(如台式电脑、mac和Linux机顶盒)、服务器(如Web和电子邮件服务器)和移动设备(如笔记本电脑、智能手机和平板电脑)。此外,越来越多的非传统事物作为端系统连接到Internet。
端系统也被称为 主机(host) ,因为它们承载(即运行)应用程序,如Web浏览器程序、Web服务器程序、电子邮件客户端程序或电子邮件服务器程序。在本书中,我们将交替使用术语主机和端系统;即host = end system。主机有时可以进一步分为两类: 客户端 和 服务器 。非正式地说,客户端往往是台式机、笔记本电脑、智能手机等,而服务器往往是存储和分发Web页面、流视频、转发电子邮件等功能更强大的机器。今天,我们接收搜索结果、电子邮件、网页、视频和移动应用程序内容的大部分服务器都位于大型 数据中心 。例如,截至2020年,谷歌在四大洲拥有19个数据中心,总共包含几百万台服务器。图1.3包括两个这样的数据中心,Case History侧栏更详细地描述了数据中心。
小案例之:数据中心和云计算
互联网公司如谷歌,微软,亚马逊和阿里巴巴已经建立了大量的数据中心,每个数据中心容纳数万到数十万主机。这些数据中心不仅连接到Internet,而且在内部还包括连接数据中心主机的复杂计算机网络。数据中心是我们日常使用的互联网应用程序背后的引擎。
一般来说,数据中心有三个目的,为了具体化,我们在Amazon上下文中描述了这些目的。首先,它们向用户提供亚马逊电子商务页面,例如描述产品和购买信息的页面。其次,它们作为大型并行计算基础设施,用于特定于amazon的数据处理任务。第三,他们为其他公司提供 云计算 。事实上,如今计算领域的一个主要趋势是,公司使用像Amazon这样的云服务提供商来处理几乎所有的IT需求。例如,Airbnb和许多其他基于互联网的公司并不拥有和管理自己的数据中心,而是在亚马逊云上运行它们的所有基于网络的服务,即亚马逊网络服务(AWS)。
数据中心中的工蜂就是主机。它们提供内容(例如,Web页面和视频),存储电子邮件和文档,并共同执行大规模分布式计算。数据中心中的主机,称为刀片(blade),类似于披萨盒,通常是包括CPU、内存和磁盘存储的商品主机。主机被堆放在机架中,每个机架通常有20到40个刀片。然后使用复杂的、不断发展的数据中心网络设计来互连机架。数据中心网络将在第6章中更详细地讨论。
1.2.1 接入网络
考虑到应用程序和端系统在网络的边缘,接下来让我们考虑接入网络——将端系统物理连接到从端系统到任何其他远端系统路径上的第一个路由器(也称为“边缘路由器”)的网络。图1.4显示了几种类型的接入,粗线的网络和使用它们的设置(家庭、企业和广域移动无线)。
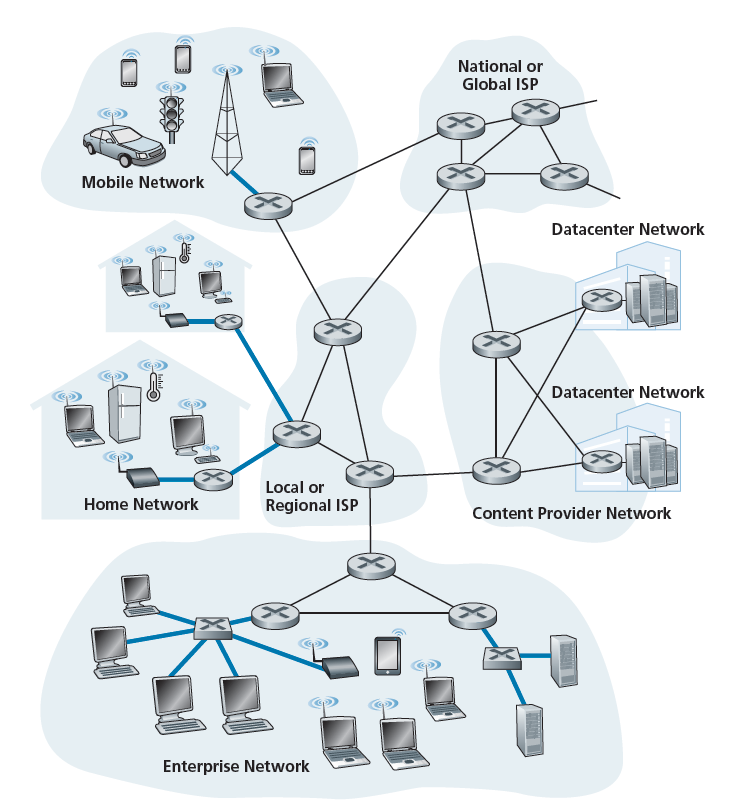
家庭接入:DSL,电缆,FTTH和5G固定无线
截至2020年,欧洲和美国超过80%的家庭拥有互联网接入[Statista 2019]。鉴于家庭接入网络的广泛使用,让我们从考虑家庭如何连接到互联网开始我们对接入网络的概述。
如今,两种最普遍的宽带住宅接入类型是 数字用户线(DSL,digital subscriber line) 和电缆。住宅通常从提供有线本地电话接入的同一家本地电话公司(telco)获得DSL Internet接入。因此,在使用DSL时,客户的电信公司也是其ISP。如图1.5所示,每个客户的DSL调制解调器使用现有的电话线交换数据,并使用位于电信公司当地中央办公室(CO)的数字用户线访问多路复用器(DSLAM)。家中的DSL调制解调器接收数字数据,并将其转换为高频音调(high- frequency tones),通过电话线传输到CO;来自许多这样的房子的模拟信号在DSLAM被转换回数字格式。
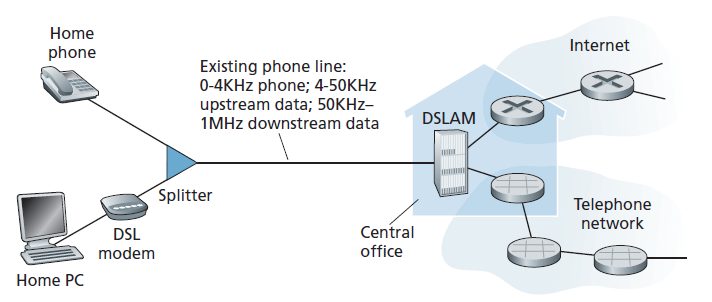
住宅电话线同时携带数据和传统电话信号,这些信号被编码在不同的频率上:
- 高速下行信道,在50kHz到1MHz频段内
- 中速上行信道,在4khz至50khz频段内
- 普通的双向电话信道,在0到4千赫频段
这种方法使单个DSL链路看起来好像有三个独立的链路,以便电话和Internet连接可以在以下位置同时共享DSL链路。(我们将在1.3.1节描述这种频分多路复用技术。)在客户端,分离器(splitter)将到达家庭的数据和电话信号分开,并将数据信号转发给DSL调制解调器。在telco端,CO中,DSLAM将数据和电话信号分离,并将数据发送到Internet。数百甚至数千个家庭连接到一个DSLAM。
DSL标准定义了多种传输速率,包括下行传输速率为24mbs和52mbs,上行传输速率为3.5 Mbps和16Mbps;最新标准规定上行加下行的总速率为1 Gbps [ITU 2014]。因为下行和上行的速率不同,所以称之为不对称访问。实际实现的下行和上行传输速率可能小于上述速率,因为DSL提供商可能在提供分级服务(不同速率,以不同价格提供)时有意限制住宅速率。最大速率也受限于家庭和CO之间的距离,双绞线的规格和电气干扰的程度。工程师们明确设计了DSL用于家庭和CO之间的短距离;一般来说,如果住所不在CO的5到10英里范围内,住宅必须采用另一种形式的互联网接入。
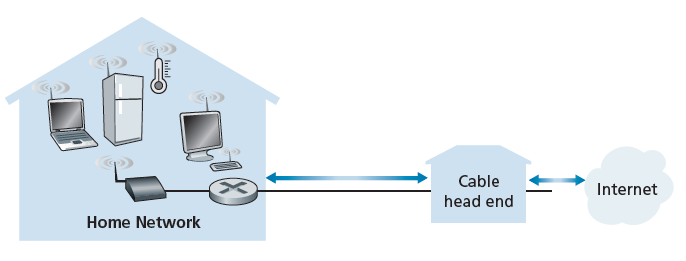
DSL利用电信公司现有的本地电话基础设施,而 有线互联网接入(Cable internet access) 利用有线电视公司现有的有线电视基础设施。一个住宅从提供有线电视的同一家公司获得有线互联网接入。如图1.6所示。光纤将电缆头端(cable head end)连接到社区级连接处,传统的同轴电缆用于到达单独的住宅和公寓。每个社区接壤处通常能容纳500到5000户家庭。由于在该系统中既使用光纤又使用同轴电缆,通常称为混合光纤同轴电缆(HFC)。
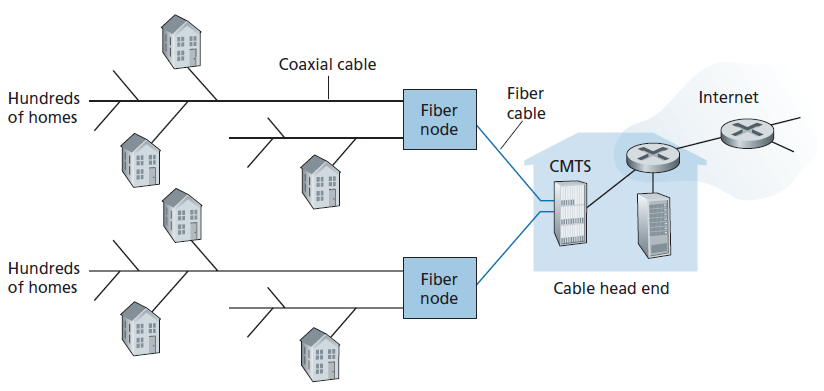
有线互联网接入需要特殊的调制解调器,称为有线调制解调器(cable modems)。与DSL调制解调器一样,有线调制解调器通常是一个外部设备,通过以太网端口连接到家庭PC。(我们将在第6章详细讨论以太网。)在电缆头端,有线调制解调器终端系统(CMTS)的功能类似于DSL网络的DSLAM——将下行的许多家庭的有线调制解调器发送的模拟信号转换成数字格式。有线调制解调器将HFC网络划分为两个信道,一个下行信道和一个上行信道。与DSL一样,访问通常是不对称的,下行信道通常分配比上行信道更高的传输速率。DOCSIS 2.0和3.0标准分别规定下行比特率为40 Mbps和1.2 Gbps,上行比特率为30 Mbps和100 Mbps。在DSL网络的情况下,由于较低的合同数据率或媒体损害,可能无法实现可实现的最大速率。
有线互联网接入的一个重要特点是它是一种共享的广播媒体。特别地,由头端发送的每个数据包在每条链路上下行到达每个家庭,或反之。因此,如果多个用户同时在下行信道上下载一个视频文件,每个用户接收其视频文件的实际速率将明显低于有线下行的总速率。另一方面,如果只有少数活跃用户,而且他们都在Web冲浪,那么每个用户实际上都可能以完整的有线下行速率接收Web页面,因为用户很少会在完全相同的时间请求一个Web页面。因为上行信道也是共享的,所以需要一个分布式的多访问协议来协调传输和避免冲突。(我们将在第6章详细讨论这个冲突问题。)
尽管DSL和有线网络目前代表了美国大部分家庭宽带接入,但一种提供更高速度的新兴技术是 光纤到户(FTTH,fiber to the home) [光纤宽带2020]。顾名思义,FTTH的概念很简单——提供一条从CO直接送到家里。FTTH可以提供千兆比特每秒的互联网接入速率。
从CO到家庭的光学分发有几种竞争技术。最简单的光纤分配网络被称为导向光纤(direct fiber),每个家庭都有一根光纤离开CO。更常见的是,离开CO的每一根光纤实际上都被许多家庭共享;直到光纤相对接近家庭,它才被分解成单独的客户专用光纤。有两种竞争的光学分发网络架构执行这种分离:分为主动光网络(AONs)和被动光网络(PONs)。AON本质上是交换以太网,将在第6章中讨论。
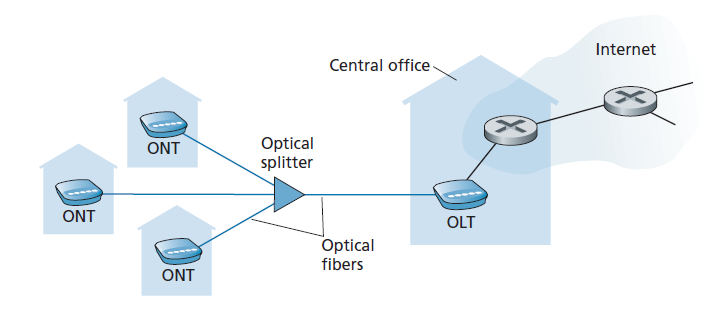
在这里,我们简要讨论了在Verizon的FiOS服务中使用的PON。图1.7显示了使用PON分发架构的FTTH。每个家庭都有一个光网络终止器(ONT optical network terminator),它通过专用光纤连接到社区分离器。分离器将许多家庭(通常少于100户)组合到一个单一的共享光纤上,该光纤连接到telco公司CO的光线路终止器(OLT optical line terminator)。OLT提供光信号和电信号之间的转换,通过telco路由器连接到互联网。在家里,用户将一个家庭路由器(通常是无线路由器)连接到ONT,并通过这个家庭路由器接入互联网。在PON体系结构中,从OLT发送到分离器的所有数据包都在分离器上复制(类似于电缆头端)。
除了DSL、Cable和FTTH, 5G固定无线也开始部署。5G固定无线网络不仅保证了高速的家庭接入,而且不会安装从telco公司CO到家庭的昂贵且易故障的电缆。在5G固定无线通信中,利用波束形成技术,可以将数据从移动通信公司的基站无线传输到家中的调制解调器上。一个WiFi无线路由器连接到调制解调器(可能捆绑在一起),类似于一个WiFi无线路由器连接到电缆或DSL调制解调器。第7章将介绍5G蜂窝网络。
企业(和家庭)的接入:以太网和WiFi
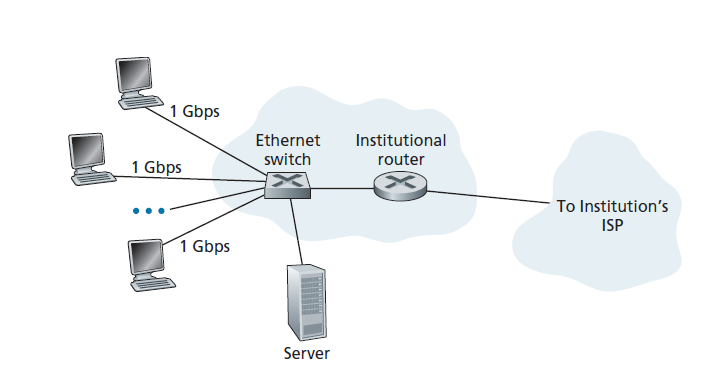
在公司和大学校园,在家庭环境中,越来越多的地方,一个局域网(LAN)用于连接终端系统到边缘路由器。虽然局域网技术有很多种,但以太网是目前公司、大学和家庭网络中最流行的接入技术。如图1.8所示。以太网用户使用双绞线连接到以太网交换机,在第6章中详细讨论了该技术。以太网交换机,或由这样的相互连接的交换机组成的网络,然后依次连接到更大的Internet。使用以太网访问,用户通常有100 Mbps到几十Gbps的以太网接入,而服务器可能只有1 Gbps到10 Gbps的接入。
然而,越来越多的人通过笔记本电脑、智能手机、平板电脑和其他设备无线接入互联网。在无线局域网设置中,无线用户向连接到企业网络(很可能使用有线以太网)的接入点发送/接收数据包,而企业网络又连接到有线互联网。无线局域网用户通常必须在接入点的几十米范围内。基于IEEE 802.11技术的无线局域网接入,更通俗的说法是WiFi,现在几乎无处不在,大学,商务办公室,咖啡馆,机场,家庭,甚至飞机上。正如在第7章中详细讨论的,今天的802.11提供了超过100 Mbps的共享传输速率。
尽管以太网和WiFi接入网最初部署在企业(企业、大学)环境中,但它们也是家庭网络的常见组件。许多家庭将宽带住宅接入(即有线调制解调器或DSL)与这些廉价的无线局域网技术结合起来,创建强大的家庭网络。图1.9显示了一个典型的家庭网络。这个家庭网络包括一台漫游笔记本电脑、多台联网家电以及一台有线PC;一个基站(无线接入点),与家中的无线PC和其他无线设备进行通信;以及将无线接入点和任何其他有线家庭设备连接到互联网的家庭路由器。该网络允许家庭成员使用宽带接入互联网,一个成员从厨房到后院再到卧室漫游。
广域无线接入:3G和LTE 4G和5G
像iphone和Android这样的移动设备正在被用于发送信息、在社交网络上分享照片、进行移动支付、观看电影、流媒体音乐等。这些设备使用与蜂窝电话相同的无线基础设施,通过由蜂窝网络提供商操作的基站发送/接收数据包。与WiFi不同的是,用户只需要距离基站几十公里(而不是几十米)。
电信公司在所谓的第四代(4G)无线技术上投入了大量资金,这种技术提供了高达60Mbps的真实下载速度。但即使是高速的广域接入技术——第五代广域无线网络(5G)——也已经在部署中。我们将在第7章中涵盖无线网络和移动的基本原则,以及WiFi、4G和5G技术(以及更多!)
1.2.2 物理媒介
在前一小节中,我们概述了Internet中一些最重要的网络接入技术。在描述这些技术时,我们还指出了所使用的物理介质。例如,我们说过HFC使用光纤电缆和同轴电缆的组合。我们说过DSL和以太网使用铜线。我们说过移动接入网络使用无线电频谱。在这一小节中,我们提供了这些和其他在互联网中通常使用的传播媒体的简要概述。
为了定义什么是物理媒介,让我们回顾一下比特短暂的生命历程:从一个端系统,通过一系列的链路和路由器,到达另一个端系统。这个可怜的家伙被踢来踢去,传播了很多很多次!源端系统首先传输比特,此后不久,该系列中的第一个路由器接收该比特;然后,第一个路由器发送该比特,不久之后,第二个路由器接收该比特;等等。因此,我们的比特在从源传输到目的地时,要经过一系列的收发器对(transmitter-receiver pair)。对于每一对发射器-接收器,比特是通过通过物理介质传播电磁波或光脉冲发送的。物理介质可以有多种形状和形式,而且对于路径上的每一对发射器-接收器来说,它们的类型不必相同。物理介质的例子包括双绞线、同轴电缆、多模光纤电缆、地面无线电频谱和卫星无线电频谱。物理媒介分为两类: 有线媒介(guided media) 和 无线媒介(unguided media) 。在有线媒介的情况下,波沿着固体媒介被引导,如光纤电缆、双绞线铜线或同轴电缆。在无线媒介中,电波在大气和外层空间中传播,例如在无线局域网或数字卫星频道中。
但在我们进入各种媒介类型的特点之前,让我们先说一下它们的成本。与其他网络成本相比,物理链路(铜线、光纤电缆等)的实际成本通常相对较小。特别是,与安装物理环节相关的人工成本可能比材料成本高几个数量级。因此,许多建筑商在建筑物的每个房间都安装双绞线、光纤和同轴电缆。即使最初只使用一种媒介,在不久的将来也很有可能使用另一种媒介,因此不必在未来铺设额外的电线,从而节省了资金。
双绞铜线
最便宜和最常用的有线传输媒介是双绞线铜线。一百多年来,它一直被用于电话网络。事实上,从电话听筒到本地电话交换机的有线连接有99%以上使用双绞线。我们大多数人在家里(或父母或祖父母的家里)和工作环境中都见过双绞线。双绞线由两根绝缘铜线组成,每根大约1毫米厚,呈规则的螺旋状排列。这些电线绞在一起,以减少附近类似导线对其产生电干扰。通常情况下,将多对线缆用防护罩包裹在一起,形成一根电缆。一对导线组成一个通信链路。 非屏蔽双绞线(UTP,Unshielded twisted pair) 通常用于建筑物内的计算机网络,即局域网。目前使用双绞线的局域网的数据速率从10Mbps到10gbps不等。可以实现的数据速率取决于导线的厚度以及发射方和接收方之间的距离。
当光纤技术在20世纪80年代出现时,许多人因为其相对较低的比特率而贬低双绞线。有些人甚至觉得这种光纤技术将完全取代双绞线。但双绞线并没有轻易放弃。现代双绞线技术,如6a电缆,可以在100米的距离内实现10gbps的数据传输速率。最后,双绞线已经成为高速局域网网络的主要解决方案。
如前所述,双绞线也常用于住宅互联网接入。我们看到拨号调制解调器技术能够以高达56kbps的速率接入。我们还看到,DSL(数字用户线)技术使住宅用户可以通过双绞线(当用户居住在靠近ISP中心办公室的地方时)以数十Mbps的速度接入互联网。
同轴电缆
与双绞线一样,同轴电缆由两个铜导体组成,但这两个铜导体是同心的而不是平行的。由于这种结构和特殊的绝缘屏蔽,同轴电缆可以实现较高的数据传输速率。同轴电缆在有线电视系统中很常见。正如我们之前看到的,有线电视系统最近已经与有线调制解调器相结合,为住宅用户提供百兆比特/秒的互联网接入。在有线电视和有线互联网接入中,发射方(transmitter)将数字信号转移到特定的频带,产生的模拟信号从发射方发送到一个或多个接收方。同轴电缆可用作有线 共享媒介(shared medium) 。具体来说,许多端系统可以直接连接到电缆上,每一个端系统接收另一个端系统发送的任何信息。
光纤
光纤是一种薄而灵活的介质,它可以传导光脉冲,每个脉冲代表一个比特。单根光纤可以支持巨大的比特率,高达每秒数十甚至数百千兆比特。它们对电磁干扰免疫,有非常低的信号衰减,可达100公里,而且很难被挖掘。这些特点使光纤成为首选的远程有线传输媒介,特别是跨洋链路。美国和其他地方的许多长途电话网络现在只使用光纤。光纤在互联网的主干中也很普遍。然而,光学设备(如发射器、接收器和交换机)的高成本阻碍了它们用于短程传输的部署,例如在局域网中或在住宅接入网中进入家庭。光载波(OC,Optical Carrier)标准链路速度范围从51.8Mbps到39.8Gbps;这些规范通常被称为OC-n,其中链路速度等于n倍51.8Mbps。目前使用的标准包括OC-1、OC-3、OC-12、OC-24、OC-48、OC-96、OC-192、OC-768。
地面广播频道
无线电信道携带电磁波谱中的信号。它们是一种有吸引力的媒介,因为它们不需要安装物理电线,可以穿透墙壁,为移动用户提供连接,并有可能将信号长距离传输。无线电信道的特性在很大程度上取决于传播环境和传输信号的距离。环境因素决定了路径损耗和阴影衰落(当信号通过一段距离和周围/通过障碍物时,信号强度降低),多径衰落(由于干扰物体的信号反射)和干扰(由于其他传输和电磁信号)。
地面无线电信道大致可分为三类:一类是在非常短的距离(如1米或2米)上运行的信道;那些在本地活动的,通常跨度从10米到几百米;还有那些在广阔的区域活动,跨越几十公里。个人设备,如无线耳机、键盘和医疗设备,可以短距离操作;第1.2.1节所述的无线局域网技术使用本地无线电信道;蜂窝接入技术使用广域无线电信道。我们将在第7章详细讨论广播信道。
卫星广播信道
一个通信卫星连接两个或两个以上的地面微波发射器/接收器,称为地面站。卫星在一个频段接收传输,使用中继器重新生成信号(下文讨论),并在另一个频率上传输信号。两种类型的卫星被用于通信: 地球同步卫星(geostationary satellites) 和 低地球轨道卫星(LEO,low-earth orbiting) 。
地球同步卫星永远停留在地球上同一地点的上空。这是通过将卫星放置在距离地球表面36000公里的轨道上而实现的。从地面站到卫星再到地面站的这一巨大距离带来了280毫秒的信号传播延迟。尽管如此,卫星链路,可以以数百Mbps的速率运行,经常在没有DSL或有线互联网接入的地区使用。
低轨道卫星的位置离地球更近,不会永久停留在地球上的某个地方。它们围绕着地球旋转(就像月球一样),并且可以相互通信,也可以与地面站通信。为了对一个地区提供连续的覆盖,需要将许多卫星放置在轨道上。目前有许多低空通信系统正在开发中。近地轨道卫星技术将来可能用于互联网接入。
1.3 网络核心
在了解了因特网的边缘之后,现在让我们更深入地研究网络核心——即连接因特网端系统的数据包交换机和链路。图1.10用粗的阴影线突出了网络核心。
1.3.1 数据包交换
在网络应用程序中,端系统相互交换消息。消息可以包含应用程序设计人员想要的任何内容。消息可以执行控制功能(例如,图1.2中握手示例中的Hi消息)或包含数据,如电子邮件消息、JPEG图像或MP3音频文件。为了从源端系统向目标端系统发送消息,源将长消息分成称为 数据包(packets) 的更小的数据块。在源和目标之间,每个数据包通过通信链路和 数据包交换机 (其中有两种主要类型, 路由器 和 链路层交换机 )旅行。数据包在每个通信链路上的传输速率等于该链路的全部传输速率。因此,如果源端系统或数据包交换机在传输速率为R比特/秒的链路上发送一个L比特的数据包,则该数据包的传输时间为L / R秒。
存储转发传输
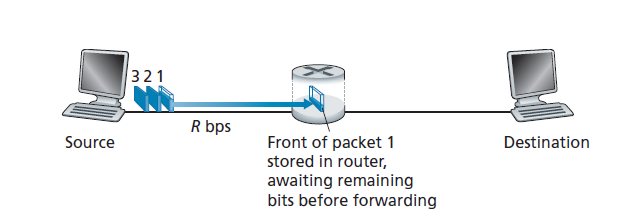
大多数数据包交换机在链路的输入端使用 存储-转发传输(store-and-forward transmission) 。存储-转发传输意味着数据包交换机必须在开始将数据包的第一个比特传输到出站链路之前接收整个数据包。为了更详细地研究存储和转发传输,考虑一个由单个路由器连接的两端系统组成的简单网络,如图1.11所示。路由器通常会有许多入射(incident)链路,因为它的工作是将一个入站数据包交换换到一个出站链路上;在这个简单的例子中,路由器有一个相当简单的任务,就是将一个数据包从一个(输入)链路传输到唯一的另一个附加链路。在这个例子中,源端有三个数据包,每个数据包由L 比特组成,发送到目的地。在图1.11所示的时间快照中,源已经传输了数据包1的一部分,数据包1的前端已经到达路由器。因为路由器使用存储转发,在这个时刻,路由器不能传输它所接收到的比特;相反,它必须首先缓冲(即存储)数据包的比特。只有在路由器接收到数据包的所有比特之后,它才能开始将数据包发送(即转发)到出站链路上。为了深入了解存储-转发传输,现在让我们计算从源开始发送数据包到目标接收整个数据包所经过的时间。(这里我们将忽略传播延迟——比特以接近光速的速度通过导线所需要的时间——这将在1.4节中讨论。)源在时间0开始传输;在L/R秒时,源已经传输了整个数据包,并且整个数据包已经被接收并存储在路由器上(因为没有传播延迟)。在L/R秒时,由于路由器刚刚接收到整个数据包,它可以开始将数据包发送到出站链路上,向目的地发送;在2L/R时,路由器已经发送了整个数据包,并且整个数据包已经被目的地接收。因此,总延迟为2L/R。如果比特一到达就立即转发(而不是首先接收整个数据包),那么总延迟将是L/R,因为比特不会在路由器上被占用。但是,正如我们将在1.4节讨论的,路由器需要在转发之前接收、存储和处理整个数据包。
现在让我们计算从源端开始发送第一个数据包到目标端收到所有三个数据包所经过的时间。和以前一样,在L/R时间,路由器开始转发第一个数据包。但同时在L/R时刻,源将开始发送第二个数据包,因为它刚刚发送完第一个数据包。因此,在时间2L/R时,目的地已经接收到第一个数据包,而路由器已经接收到第二个数据包。类似地,在3L/R时刻,目的地已经接收到前两个数据包,路由器已经接收到第三个数据包。最后,在时间4L/R时,目的地已经接收到所有三个数据包。
现在让我们考虑一个一般的情况,将一个数据包通过从源发送到目的地,由N条链路组成的路径,每条链路的速率为R(因此,在源和目的地之间有N-1个路由器)。应用与上面相同的逻辑,我们看到端到端延迟是:
delay = N * (L/R)
现在,您可能想要尝试确定通过N条链路发送的P个数据包的延迟是多少。
排队延迟和丢包
每个数据包交换机都有多条连接到它的链路。对于每个附加的链路,数据包交换机都有一个 输出缓冲区 (output buffer,也称为输出队列—— output queue ),它存储路由器将要发送到该链路的数据包。输出缓冲区在数据包交换中起着关键作用。如果一个到达的数据包需要传输到链路上,但发现链路上正忙于传输另一个数据包,那么到达的数据包必须在输出缓冲区中等待。因此,除了存储和转发延迟外,数据包还会受到输出缓冲区 排队延迟 的影响。这些延迟是可变的,取决于网络拥塞的程度。由于缓冲区的空间是有限的,一个到达的数据包可能会发现缓冲区已经被其他等待传输的数据包完全填满了。在这种情况下,将发生 丢包 ——到达的数据包或已经排队的数据包中的一个将被丢弃。
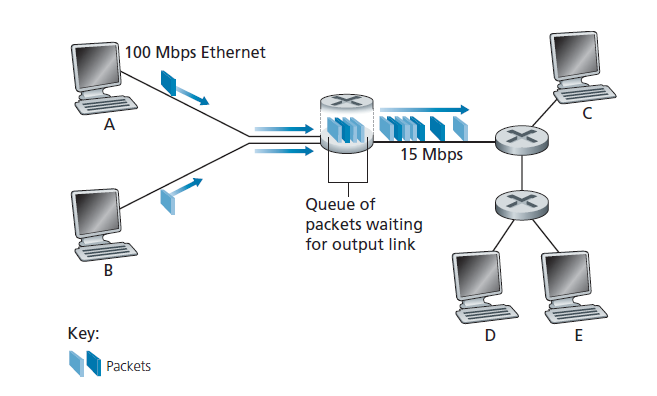
图1.12说明了一个简单的数据包交换网络。如图1.11所示,数据包由三维板表示。板的宽度表示数据包中的比特数。在这个图中,所有的数据包都有相同的宽度,因此也有相同的长度。假设主机A和主机B向主机E发送数据包,主机A和主机B首先将它们的数据包沿100Mbps以太网链路发送到第一个路由器。然后路由器将这些数据包导向15Mbps链路。如果在很短的时间间隔内,数据包到达路由器的速率(换算为比特/秒)超过15Mbps,则在路由器上发生拥塞,因为数据包在传输到链路之前,将在链路的输出缓冲区中排队。例如,如果主机A和主机B同时连续发送5个数据包,那么这些数据包中的大多数将花费一些时间在队列中等待。事实上,这种情况完全类似于日常生活中的许多常见情况,例如,当我们排队等待银行出纳员或在收费亭前等待。我们将在1.4节中更详细地研究这种排队延迟。
转发表和路由协议
前面,我们说过,路由器接收一个到达它的一个附加通信链路上的数据包,并将该数据包转发到它的另一个附加通信链路上。但是路由器如何决定它应该将数据包转发到哪一个链路呢?在不同类型的计算机网络中,数据包转发实际上是以不同的方式进行的。在这里,我们简要描述如何在互联网上完成。
在互联网中,每个端系统都有一个地址,称为IP地址。当源端系统向目标端系统发送数据包时,源端在数据包的头中包含目标端的IP地址。与邮政地址一样,该地址具有层次结构。当一个数据包到达网络中的一台路由器时,路由器检查数据包的目标地址的一部分,并将数据包转发给相邻的一台路由器。更具体地说,每个路由器都有一个 转发表(forwarding table) ,它将目标地址(或部分目标地址)映射到该路由器的出站链路。当一个数据包到达路由器时,路由器检查这个地址,并使用这个目标地址搜索它的转发表,以找到合适的出站链路。然后路由器将数据包导向这个出站链路。
端到端路由过程类似于汽车司机,他们不使用地图,而是更喜欢询问方向。例如,假设Joe从费城开车到佛罗里达州奥兰多湖畔路156号。Joe先开车到附近的加油站,询问如何去佛罗里达州奥兰多市湖滨大道156号。加油站工作人员提取了地址佛罗里达的部分,并告诉Joe,他需要进入州际高速公路I-95南,这有一个入口就在加油站旁边。他还告诉Joe,一旦他进入佛罗里达,他应该问那里的其他人。然后Joe乘I-95向南行驶,直到他到达佛罗里达州的杰克逊维尔,在那里他向另一个加油站的服务员问路。服务员摘录了地址的奥兰多部分,告诉Joe他应该继续沿着I-95到代托纳海滩,然后问其他人。在代托纳海滩,另一个加油站的工作人员也提取了地址的奥兰多部分,并告诉Joe,他应该直接乘坐I-4到奥兰多。Joe在I-4号公路上,在奥兰多出口下车。Joe走到另一个加油站的工作人员那里,这一次工作人员提取了湖滨路的地址,并告诉Joe他必须走哪条路才能到达湖滨路。当Joe到达湖畔大道时,他问一个骑自行车的孩子怎么去他的目的地。那孩子取出了地址的156部分,指向了那所房子。Joe终于到达了他的最终目的地。在上面的类比中,加油站服务员和骑自行车的孩子就好比路由器。
我们刚刚知道,路由器使用数据包的目标地址来索引转发表,并确定适当的出站链路。但这句话引出了另一个问题:如何设置转发表?它们是在每个路由器中手工配置的,还是互联网使用自动化的程序?这一问题将在第五章深入研究。但是为了激发您的兴趣,我们现在要注意Internet有许多特殊的路由协议,它们用于自动设置转发表。例如, 路由协议 可以确定从每个路由器到每个目的地的最短路径,并使用最短路径的结果在路由器中配置转发表。
1.3.2 线路交换
在由链路和交换机组成的网络中移动数据有两种基本方法: 线路交换(circuit switching) 和 数据包交换 。在前面的小节中已经讨论了数据包交换网络,现在我们把注意力转向线路交换网络。
在线路交换网络中,为端系统之间的通信提供的沿路所需的资源(缓冲区、链路传输速率)在端系统之间的通信会话期间被保留。在数据包交换网络中,这些资源并不保留;会话的消息按需使用资源,因此,可能必须等待(即排队)才能访问通信链路。作为一个简单的类比,考虑两个餐馆,一个需要预订,另一个既不需要也不接受预订。对于需要预订的餐馆,我们在离家前不得不经历打电话的麻烦。但当我们到达餐厅时,原则上我们可以立即就座并点餐。如果是不需要预定的餐厅,就不需要预定座位。但是当我们到达餐厅时,我们可能要等一张桌子才能就座。
传统的电话网络就是线路交换网络的例子。考虑一下当一个人想要通过电话网络向另一个人发送信息(声音或传真)时会发生什么。在发送方发送信息之前,网络必须在发送方和接收方之间建立连接。这是一个真实的连接,在发送方和接收方之间的路径上的交换机为该连接保持连接状态。在电话行话中,这种连接叫做 线路(circuit) 。当网络建立线路时,它也在连接期间在网络的链路中保留一个恒定的传输速率(表示每个链路传输能力的一部分)。由于为这个发送端到接收端连接保留了一个给定的传输速率,发送端可以以保证的恒定速率将数据传输给接收端。
图1.13展示了线路交换网络。在这个网络中,四个线路交换机由四条链路连接在一起。每个链路有四个线路,因此每个链路可以支持四个同时连接。主机(例如,pc机和工作站)直接连接到其中一个交换机。当两台主机需要通信时,网络会在两台主机之间建立专用的 端到端连接(end-to-end connection) 。因此,为了使主机A与主机B通信,网络必须首先在两条链路的每一条上预留一个线路。在本例中,专用端到端连接在第一链路中使用第二线路,在第二链路中使用第四线路。由于每条链路有4条线路,因此对于端到端连接所使用的每条链路,连接在连接期间将获得链路总传输能力的四分之一。因此,例如,如果相邻交换机之间的每条链路的传输速率为1Mbps,那么每个端到端线路交换机连接的专用传输速率为250kbps。
相反,考虑一下当一台主机想要通过数据包交换网络(如Internet)向另一台主机发送数据包时,会发生什么情况。与线路交换一样,数据包是在一系列通信链路上传输的。但与线路交换不同的是,数据包被发送到网络中而不保留任何链路资源。如果由于其他数据包需要同时在链路上传输而导致其中一条链路拥塞,那么数据包将不得不在传输链路发送端的缓冲区中等待,并遭受延迟。Internet尽其最大努力及时地传递数据包,但它不做任何保证。
线路交换网络中的多路复用
链路中的线路采用 频分多路复用 (FDM frequency-division multiplexing)或 时分多路复用 (TDM time-division multiplexing)实现。使用FDM,链路的频谱(frequency spectrum)在链路上建立的连接之间划分。具体地说,该链路在连接期间为每个连接指定一个频带(frequency band)。在电话网络中,这个频带的宽度通常为4千赫(即4000赫兹或4000周期每秒)。不出所料,这个频带的宽度被称为 带宽 。FM电台也使用FDM来共享88 MHz到108 MHz之间的频谱,每个电台被分配一个特定的频带。
对于TDM链路,时间被划分为持续时间固定的帧,每帧被划分为固定数量的时隙(time slots)。当网络在一条链路上建立一个连接时,网络在每一帧中为这个连接贡献一个时隙。这些时隙是专为连接单独使用的,每帧只能有一个时隙用来传输连接的数据。
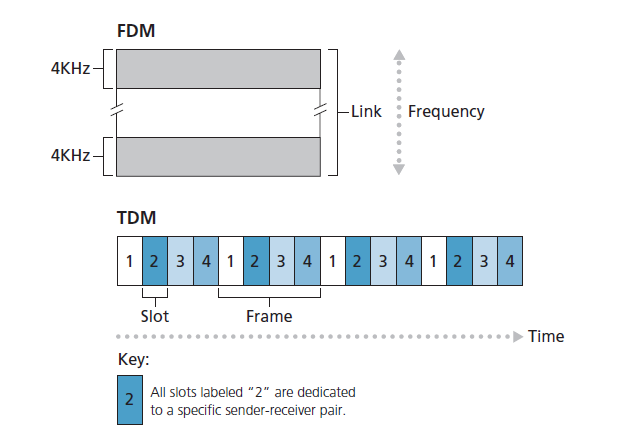
图1.14说明了支持四个线路的特定网络链路的FDM和TDM。对于FDM,频域被分割成四个频带,每个频带的带宽为4khz。对于TDM,时域被分割成帧,每帧中有四个时隙;每个线路在TDM帧中分配相同的专用时隙。对于TDM,线路的传输速率等于帧速率乘以一个时隙中的比特数。例如,如果链路每秒传输8000帧,每个时隙由8比特组成,那么每个线路的传输速率为64kbps。
数据包交换的支持者总是认为线路交换是浪费的,因为在 静默期间(silent periods) 专用线路是空闲的。例如,当通话中的一个人停止通话时,其他正在进行的连接无法使用空闲的网络资源(该连接路径上链路的频带或时隙)。作为这些资源如何得到充分利用的另一个例子,考虑一个放射科医生使用线路交换网络远程访问一系列x射线。放射科医生建立一个连接,请求一个图像,考虑接受图像,然后请求一个新的图像。网络资源被分配给连接,但在放射科医生的考虑期间没有使用(即浪费)。数据包交换的支持者也乐于指出,建立端到端线路和保留端到端传输能力是复杂的,并且需要复杂的信令(signaling)软件来协调交换机沿端到端路径的操作。
在我们结束线路交换的讨论之前,让我们通过一个数值示例来进一步了解这个主题。让我们考虑一下通过线路交换网络从主机a发送一个64万比特的文件到主机B需要多长时间。假设网络中的所有链路都使用24个时隙的TDM,比特率为1.536 Mbps。也假设在主机A开始传输文件之前,需要500 msec来建立一个端到端线路。发送文件需要多长时间?每个线路的传输速率为(1.536 Mbps)/24 = 64 kbps,所以需要(64万比特)/(64 kbps) = 10秒来传输文件。在这10秒中,我们添加了线路建立时间,给了10.5秒来发送文件。请注意,传输时间与链路数无关:如果端到端线路通过一条链路或100条链路,传输时间为10秒。(实际的端到端延迟还包括传播延迟;参见1.4节)。
数据包交换VS线路交换
在描述了线路交换和数据包交换之后,让我们比较一下两者。数据包交换的批评者经常认为,数据包交换不适合实时服务(例如,电话和视频会议电话),因为它的可变和不可预测的端到端延迟(主要是由于可变和不可预测的排队延迟)。数据包交换的支持者认为:(1)它比线路交换提供更好的传输容量共享;(2)它比线路交换更简单、更高效、成本更低。关于数据包交换与线路交换的一个有趣的讨论是[Molinero- Fernandez 2002]。一般来说,不喜欢为餐馆预订而烦恼的人更喜欢数据包交换而不是线路交换。
为什么数据包交换更有效?让我们看一个简单的例子。假设用户共享一个1Mbps的链路。还假设每个用户在活动期间(用户以恒定的100 kbps的速率生成数据)和不活动期间(用户不生成数据)之间交替。再假设一个用户只有10%的时间是活跃的(并且在剩下的90%时间里无所事事地喝咖啡)。对于线路交换,必须在任何时候为每个用户预留100kbps。例如,在线路交换时分复用(TDM)中,如果一秒的帧被分成10个时隙,每个时隙为100毫秒,那么每一帧将分配给每个用户一个时隙。
因此,线路交换链路只能同时支持10个(= 1Mbps / 100kbps)用户。使用数据包交换,特定用户活动的概率是0.1(即10%)。如果有35个用户,那么同时有11个或更多活跃用户的概率大约是0.0004。(作业习题P8概述了如何得到这个概率。)当同时有10个或更少的活跃用户时(这种情况发生的概率为0.9996),数据的总到达率小于或等于1Mbps,即链路的输出速率。因此,当有10个或更少的活跃用户时,用户信息流本质上无延迟通过链路,就像线路交换一样。当同时有10个以上的活跃用户时,数据包的总到达率超过链路的输出容量,输出队列将开始增长。(它会继续增长,直到回落到1Mbps以下,此时队列的长度将开始减少。)由于在本例中同时拥有10个以上活跃用户的可能性很小,所以数据包交换提供了与线路交换本质上相同的性能,但同时允许超过三倍的用户数量。
现在让我们考虑第二个简单示例。假设有10个用户,其中一个用户突然生成了一千个1,000比特的数据包,而其他用户保持静止,不生成数据包。在每帧10个时隙、每个时隙为1000比特的TDM线路交换模式下,活跃用户每帧只能使用自己的一个时隙来传输数据,而每帧中其余9个时隙处于空闲状态。所有活跃用户的100万比特的数据将在10秒后全部传送。在数据包交换的情况下,由于没有其他用户生成数据包与活跃用户的数据包多路复用,活跃用户可以以1Mbps的全链路速率连续发送其数据包。在这种情况下,将在1秒内传送所有活跃用户的数据。
上述例子说明了数据包交换的性能优于线路交换的两种方式。他们还强调了在多个数据流之间共享链路传输速率的两种形式之间的关键区别。线路交换预先分配传输链路的使用,而不考虑需求,分配但不需要的链路时间不使用。另一方面,数据包交换按需分配链路使用。只有那些有需要在链路上传输数据包的用户,才会在数据包的基础上共享链路传输能力。
虽然数据包交换和线路交换在今天的电信网络中都很普遍,但数据包交换的趋势是必然的。甚至今天的许多线路交换电话网络也在慢慢地向数据包交换转移。特别是,电话网络在那些海外昂贵的电话呼叫中使用数据包交换。
1.3.3 网络的网络
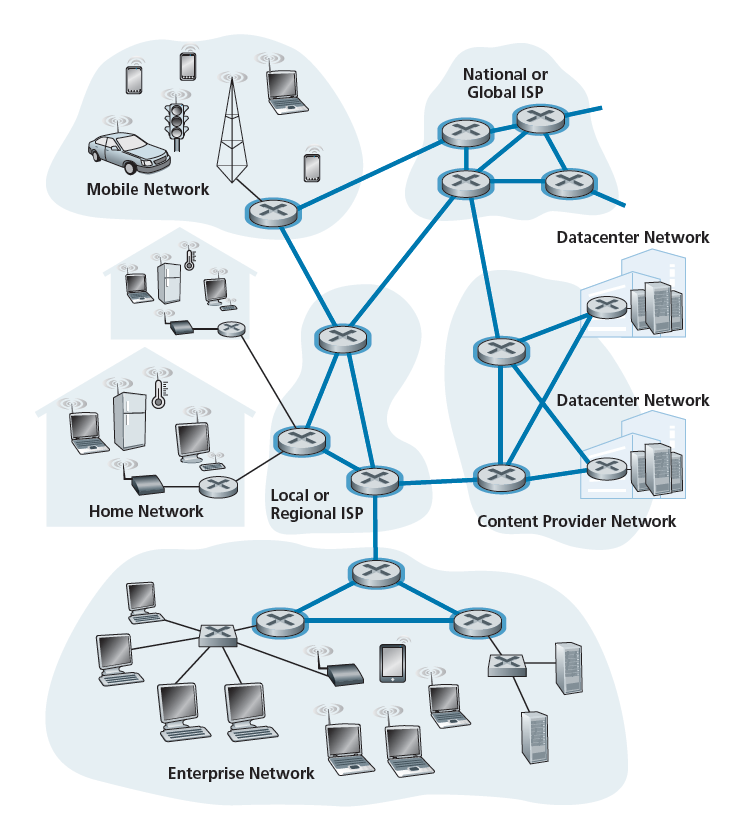
我们在前面看到,端系统(pc、智能手机、Web服务器、邮件服务器等等)通过访问ISP连接到Internet。接入ISP可以提供有线或无线连接,使用一系列接入技术,包括DSL、电缆、FTTH、Wi-Fi和蜂窝网络。请注意,接入ISP不一定是电信公司或电缆公司;相反,它可以是,例如,一所大学(为学生、员工和教职员工提供互联网接入),或者一家公司(为其员工提供互联网接入)。但是,将端用户和内容提供商连接到一个接入ISP只是解决连接构成互联网的数十亿端系统的难题的一小部分。要完成这个难题,接入ISP本身必须是互联的。这是通过创建一个网络的网络来实现的,理解这个短语是理解互联网的关键。
多年来,构成互联网的网络已经演变成一个非常复杂的结构。这种演变在很大程度上是由经济和国家政策驱动的,而不是由业绩考虑驱动的。为了了解今天的Internet网络结构,让我们逐步构建一系列的网络结构,每一个新的结构都是我们今天拥有的复杂Internet的更好的近似。回想一下,总体目标是将接入ISP互连,以便所有终端系统可以彼此发送数据包。一种简单的方法是让每个接入ISP直接连接到每个其他接入ISP。当然,这样的网状设计对于接入ISP来说太昂贵了,因为它需要每个接入ISP都有一个单独的通信链路到世界上成千上万的其他接入ISP。
我们的第一个网络结构,Network Structure 1,通过一个单一国际交换ISP(single global transit ISP)结构互连所有的接入ISP。我们的(想象中的)国际交换ISP结构是一个路由器和通信链路的网络,它不仅跨越全球,而且在数十万个接入ISP附近至少有一个路由器。当然,对于国际ISP来说,建立这样一个广泛的网络是非常昂贵的。为了盈利,它自然会向每个接入ISP收取连接费用,价格反映(但不一定是成正比的)接入ISP与国际ISP交换的流量。由于接入ISP向国际交换ISP结构付费,因此接入ISP被称为 客户(customer) ,而国际交换ISP结构被称为 提供商(provider) 。
现在,如果一些公司建立和运营一个国际交换ISP结构是有利可图的,那么自然有其他公司建立自己的国际交换ISP结构,并与原来的国际交换ISP结构竞争。这就引出了Network Structure 2,它由成千上万的接入ISP和多个国际交换ISP组成。接入ISP当然更喜欢Network Structure 2而不是Network Structure 1,因为他们现在可以在竞争的国际交换提供商中选择他们的定价和服务。但是,请注意,国际交换ISP结构本身必须相互连接:否则连接到其中一个国际交换提供商的接入ISP将无法与连接到其他国际交换提供商的接入ISP通信。
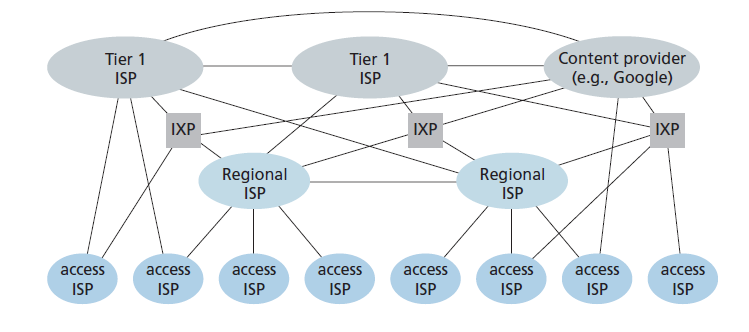
Network Structure 2,如上所述,是一个两层的层次结构,国际交换提供商位于顶层,接入ISP位于底层。这假定国际交换ISP不仅能够访问每个接入ISP,而且认为这样做在经济上是可取的。事实上,尽管一些ISP确实有令人印象深刻的全球覆盖,并直接与许多接入ISP连接,但没有一个ISP在世界上的每个城市都存在。相反,在任何给定的区域,可能有一个 区域ISP(regional ISP) ,该区域的接入ISP连接到该ISP。然后,每个区域ISP连接到 一级ISP(tier-1 ISP) 。一级ISP类似于我们(想象中的)国际交换ISP结构;但事实上确实存在的一级ISP,并不是在世界上每个城市都有存在。大约有12家一级ISP,包括Level 3 Communications、AT&T、Sprint和NTT。有趣的是,没有正式的组织批准一级状态;俗话说,如果你要问自己是不是一个团体的成员,你很可能不是。
回到这个网络的网络,不仅有多个竞争的一级ISP,在一个区域可能有多个竞争的区域ISP。在这种层次结构中,每个接入ISP向其连接的区域ISP支付费用,每个区域ISP向其连接的一级ISP支付费用。(接入ISP也可以直接与一级ISP连接,并向一级ISP支付费用)。因此,在层次结构的每个级别上都存在客户-提供商关系。请注意,一级ISP不向任何人支付费用,因为他们处于等级的顶端。更复杂的是,在一些地区,可能有一个较大的区域ISP(可能跨越整个国家),该地区较小的区域ISP连接到该地区;较大的区域ISP然后连接到一级ISP。例如,在中国,每个城市都有接入ISP,这些ISP连接省级ISP,省级ISP再连接全国ISP,最终连接一级ISP[田2012]。我们将这种多层的层次结构称为Network Structure 3,它仍然只是今天Internet的一个粗略的近似。
为了构建一个更接近当今Internet的网络,我们必须添加存在点(PoPs, points of presence)、多宿主(multi-homing)、peering和Internet交换点(IXPs,Internet exchange points)到分层Network Structure 3。pop存在于层次结构的所有级别中,除了底层(接入ISP)级别。PoP只是提供商网络中一个或多个路由器(在同一位置)的一组,客户ISP可以连接到提供商ISP。如果要将客户网络连接到提供商的PoP,可以从第三方通信公司租赁高速链路,将其路由器直接连接到PoP的路由器。任何ISP(除了一级ISP)都可以选择multi-home,即连接到两个或多个ISP提供商。因此,例如,一个接入ISP可以与两个区域ISP multi-home,或者它可以与两个区域ISP multi-home,也可以与一个一级ISP multi-home。类似地,一个区域性ISP可以使用多个一级ISP进行multi-home。当一个ISP multi-home时,它可以继续向互联网发送和接收数据包,即使其中一个提供商出现故障。
正如我们刚刚了解到的,客户ISP付钱给他们的提供商ISP以获得全球互联网互连。客户ISP支付给提供商的金额ISP反映了它与提供商交换的流量。为了降低这些成本,位于同一层次的两个相邻ISP可以peer,也就是说,它们可以直接将它们的网络连接在一起,这样它们之间的所有流量都通过直接连接,而不是通过上行中间体。当两个ISP peer时,通常是无结算的,也就是说,两个ISP都不向另一个支付费用。如前所述,一级ISP之间也相互peer,无需结算。关于peer和客户-提供商关系的可读讨论,见[Van der Berg 2008]。沿着这些相同的路线,第三方公司可以创建Internet Exchange Point (IXP),它是多个ISP可以相互peer的交汇点。ipx通常位于独立建筑中,有自己的交换机[Ager 2012]。现在互联网上有超过600个ixp [PeeringDB 2020]。我们将这种由接入ISP、区域ISP、一级ISP、PoPs、multi-home、peer互联和IXPs组成的生态系统称为Network Structure 4。
现在我们终于到了描述当今互联网的“Network Structure 5”。如图1.15所示,Network Structure 5在Network Structure 4的基础上添加了 内容提供者网络(content-provider networks) 。谷歌是目前这种内容提供网络的一个主要例子。在撰写本文时,谷歌有19个主要的数据中心分布在北美、欧洲、亚洲、南美洲和澳大利亚,每个数据中心都有数万或数十万台服务器。此外,谷歌有更小的数据中心,每个数据中心有几百台服务器;这些较小的数据中心通常位于IXP中。谷歌的数据中心都是通过谷歌的私有TCP/IP网络连接的,该网络虽然跨越全球,但与公共互联网是分开的。重要的是,谷歌专用网络只承载来往于谷歌服务器的流量。如图1.15所示,谷歌私有网络试图通过与下级ISP对等接入(免支付)来绕过互联网的上层,要么直接连接它们,要么通过在IXPs上连接它们[Labovitz 2010]。然而,由于许多接入ISP仍然只能通过一级网络中转到达,谷歌网络也连接到一级ISP,并向这些ISP支付它与它们交换的流量。通过建立自己的网络,内容提供商不仅减少了对上层ISP的支付,而且还能更好地控制其服务最终如何交付给端用户。谷歌的网络基础设施在2.6节中有更详细的描述。
1.4 数据包交换网络中的延迟、丢失和吞吐量
在第1.1节中,我们说过Internet可以被看作是为运行在端系统上的分布式应用程序提供服务的基础设施。理想情况下,我们希望互联网服务能够在任何两个端系统之间瞬间移动尽可能多的数据,而不会丢失任何数据。唉,这是一个崇高的目标,一个在现实中无法实现的目标。相反,计算机网络必然限制端系统之间的吞吐量(每秒可以传输的数据量),在端系统之间引入延迟,实际上可能会丢包。一方面,不幸的是,现实中的物理定律引入了延迟和损失,并限制了吞吐量。另一方面,由于计算机网络存在这些问题,围绕着如何处理这些问题有许多令人着迷的争论(issues),这些争论足以填满一门计算机网络课程,激发数千篇博士论文!在本节中,我们将开始研究和量化计算机网络中的延迟、丢失和吞吐量。
1.3.1 数据包交换网络中的延迟概述
回忆一下,数据包从主机(源)开始,经过一系列路由器,并在另一个主机(目的地)结束它的旅程。当数据包沿着这条路从一个节点(主机或路由器)传送到之后的节点(主机或路由器)时,数据包在路上的每个节点上都会遭受几种类型的延迟。这些延迟中最重要的是 节点处理延迟(nodal processing delay)、排队延迟(queuing delay)、传输延迟(transmission delay)和传播延迟(propagation delay) ;这些延迟加在一起就产生了一个 总节点延迟(total nodal delay) 。许多Internet应用程序(如搜索、Web浏览、电子邮件、地图、即时消息传递和voice-over-IP)的性能都受到网络延迟的很大影响。为了深入了解数据包交换和计算机网络,我们必须了解这些延迟的性质和重要性。
延迟类型
让我们在图1.16的背景下研究这些延迟。源和目的地之间的端到端路线,从上行节点发送数据包通过路由器A到路由器B。我们的目标是描述在路由器A处的节点延迟。注意,路由器A有一个出站链路通向路由器B,这个链路之前是一个队列(也称缓冲区)。当数据包从上行节点到达路由器A时,路由器A检查数据包的头,以确定数据包的适当的出站链路,然后将数据包导向此链路。在这个例子中,数据包的出站链路就是通向路由器B的那条链路。只有当链路上没有其他正在传输的数据包,并且队列中没有在它之前的数据包时,才可以在链路上传输数据包。如果当前链路繁忙或如果已经有其他数据包排队等待,那么新到达的数据包将加入队列。
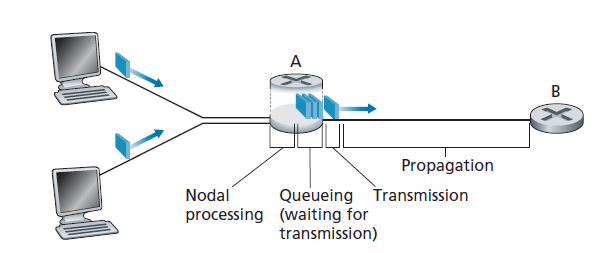
处理延迟
检查数据包头并确定将数据包引导到何处所需的时间是处理延迟(processing delay)的一部分。处理延迟还可以包括其他因素,例如检查数据包中发生的比特级错误所需的时间,这些错误是在将数据包的比特从上行节点传输到路由器A时发生的。高速路由器的处理延迟通常为几微秒或更少。在这个节点处理之后,路由器将把这个数据包引导到连接到路由器B的链路之前的队列(在第四章中,我们将研究路由器如何工作的细节)。
排队延迟
在队列中,数据包在等待传输到链路上时经历了排队延迟。特定数据包的排队延迟时间取决于排队等待传输到链路上的较早到达数据包的数量。如果队列是空的,并且当前没有传输其他数据包,那么我们的数据包的排队延迟将为零。另一方面,如果流量很大,同时有许多其他数据包也在等待传输,则排队延迟时间会很长。在实践中,排队延迟从微秒到毫秒不等。
传输延迟
假设数据包以先到先服务的方式传输(这在数据包交换网络中很常见),我们的数据包只能在所有在之前到达的数据包都被传输之后才能传输。若数据包的长度为L比特,从路由器A到路由器B的链路传输速率为R比特/秒。例如,对于一个10Mbps的以太网链路,速率是R = 10Mbps;对于一个100 Mbps的以太网链路,速率是R = 100 Mbps。传输延迟为L/R。这是将(即,传输)所有数据包的比特推入链路所需的时间。在实践中,传输延迟通常是微秒到毫秒的量级。
传播延迟
一旦一个比特被推入链路,它就需要传播到路由器B。从链路开始传播到路由器B所需要的时间就是传播延迟。比特以链路的传播速度传播。传播速度取决于链路的物理介质(即光纤、双绞线等),且在:
2 * 10 8 米/秒 ~ 3 * 10 8 米/秒
范围内,等于或者略小于光速。传输延迟是两个路由器之间的距离除以传输速度。即传播延迟为d/s,其中d为路由器A到路由器B的距离,s为链路的传播速度。一旦数据包的最后一个比特传播到节点B,它和数据包的前面所有比特都存储在路由器B中。然后,整个过程继续,现在路由器B执行转发。在广域网络中,传播延迟是毫秒量级的。
比较传输延迟和传播延迟
计算机网络领域的新手有时很难理解传输延迟和传播延迟之间的区别。两者之间的区别很微妙,但很重要。传输延迟是路由器推出数据包所需的时间量;这是数据包长度和链路传输速率的函数,与两台路由器之间的距离无关。另一方面,传播延迟是指比特从一个路由器传播到另一个路由器所花费的时间;它是两个路由器之间距离的函数,与数据包的长度或链路的传输速率无关。
打个比方也许可以阐明传输和传播延迟的概念。考虑一条高速公路,每100公里有一个收费站,如图1.17所示。你可以把收费站之间的高速公路看作链路,收费站看作路由器。假设汽车在高速公路上以100公里/小时的速度行驶(即传播)(也就是说,当汽车离开收费站时,它立即加速到100公里/小时,并在收费站之间保持这个速度)。假设接下来有10辆车组成一个车队,以固定的顺序彼此跟随。你可以把每辆车想象成一个比特,把车队想象成一个数据包。还假设每个收费站服务一辆车的速度是12秒,在高速公路上行驶的车辆只有该车队。最后,假设当车队的第一辆车到达收费站时,它在入口处等待,直到其他九辆车到达并在它后面排队。(因此,整个车队必须储存在收费站之前,才可以开始转发。)收费站将整个车队推上高速公路所需的时间是(10辆车)/(5辆车/分钟)= 2分钟。这个时间类似于路由器中的传输延迟。汽车从一个收费站出口到另一个收费站的时间是100公里/(100公里/小时)= 1小时。这个时间类似于传播延迟。因此,从车队被储存在收费站前到车队被储存在下一个收费站前的时间是传输延迟和传播延迟的总和,在本例中为62分钟。
让我们进一步探讨这个类比。如果车队的收费站服务时间大于汽车在收费站之间运行的时间,会发生什么?例如,假设汽车以1,000公里/小时的速度行驶,收费站服务车辆的速度为每分钟一辆车。那么两个收费站之间的运输延迟是6分钟,服务车队的时间是10分钟。在这种情况下,车队的前几辆车会在车队的最后一辆车离开第一个收费站之前到达第二个收费站。这种情况也出现在数据包交换网络中,当分组中的第一个比特到达路由器时,分组中的许多剩余比特仍在等待由前一个路由器传送。
如果我们让dproc、dqueue、dtrans和dprop表示处理延迟、排队延迟、传输延迟和传播延迟,则总节点延迟为:
dnodel = dproc + dqueue + dtrans + dprop (1.1)
这些延迟分量的贡献可能有很大的不同。例如,对于连接同一大学校园中的两台路由器的链路,dprop可以忽略不计(例如,几微秒);然而,dprop对于由地球同步卫星链路连接的两台路由器来说是可达几百毫秒,并且可以是节点的主要延迟。类似地,dtrans可大可小。对于10Mbps或更高的传输速率(例如,局域网),其延迟通常可以忽略不计;然而,通过低速拨号调制解调器链路发送的大型Internet数据包可能需要数百毫秒。处理延迟dproc通常可以忽略不计;但是,它强烈地影响路由器的最大吞吐量,即路由器转发数据包的最大速率。
排队延迟和丢包
节点延迟最复杂和有趣的组成部分是排队延迟,dqueue。事实上,排队延迟在计算机网络中是如此重要和有趣,以至于已经有成千上万的论文和大量的书籍写过它[Bertsekas 1991;Kleinrock 1975, Kleinrock 1976]。我们在这里只给出一个高层次的,直观的排队延迟讨论;更好奇的读者可能会想要浏览一些书(甚至最终写一篇关于这个主题的博士论文)与其他三种延迟不同,排队延迟可以因数据包而异。例如,如果同时有10个数据包到达一个空队列,则发送的第一个数据包将没有排队延迟,而发送的最后一个数据包将有一个比较大的排队延迟(它等待其他9个数据包发送)。因此,在刻画排队延迟时,通常使用统计度量,如平均排队延迟、排队延迟的方差、排队延迟超过某一指定值的概率。
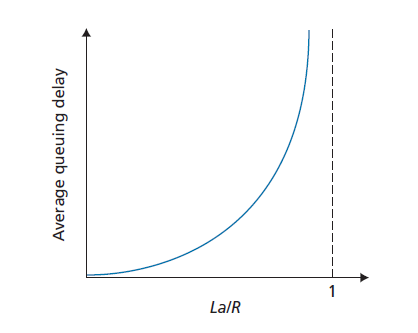
什么时候排队延迟大,什么时候不重要?这个问题的答案取决于流量到达队列的速率,链路的传输速率,以及到达流量的性质,即流量是周期性到达还是突发到达。为了更深入地了解,让a表示数据包到达队列的平均速率(a的单位是数据包/秒)。R表示传输速率;也就是说,它是比特从队列中推出的速率(以比特/秒为单位)。为了简单起见,还假设所有数据包都由L比特组成。那么比特到达队列的平均速率是La 比特/秒。最后,假设队列非常大,因此它基本上可以容纳无限个比特。La/R,即流量强度(traffic intensity),在估计排队延迟的程度时起着重要的作用。如果La/R > 1,则比特到达队列的平均速率超过比特从队列传输的速率。在这种不幸的情况下,队列将趋向于无限制地增加,排队延迟将接近无穷大!
现在考虑La/R <= 1的情况。在这里,到达的流量的性质影响排队延迟。例如,如果数据包定期到达,即每L/R秒到达一个数据包,那么每个数据包到达一个空队列,就不会有排队延迟。另一方面,如果数据包是断断续续的到达,那么就会有很大的平均排队延迟。例如,假设每(L/R)N秒有N个数据包同时到达。则所传输的第一个数据包不具有排队延迟;所传输的第二个数据包有L/R秒的排队延迟,一般来说,发送的第n个数据包的排队延迟为(n - 1)L/R秒。在本例中,我们将计算平均排队延迟留给您作为练习。
上面描述的两个周期性到达的例子有点学术性。通常,到达队列的过程是随机的;也就是说,到达不遵循任何模式,数据包之间的间隔是随机的。在这种更现实的情况下,数量La/R通常不足以充分描述排队延迟统计信息。尽管如此,它对于直观地了解排队延迟的程度还是很有用的。特别是,如果流量强度接近于零,那么数据包到达的次数很少,而且间隔很长,一个到达的数据包不太可能在队列中找到另一个数据包。因此,平均排队延迟将接近于零。另一方面,当流量强度接近1时,会有一段时间(由于数据包到达率的变化)到达率超过传输能力,在这段时间内会形成一个队列;当到达率小于传输容量时,队列长度会缩小。然而,当流量强度接近1时,平均排队长度变得越来越大。平均排队延迟对流量强度的定性依赖如图1.18所示。
丢包
在上面的讨论中,我们假设队列能够容纳无限多个数据包。实际上,在链路之前的队列的容量是有限的,尽管队列的容量很大程度上取决于路由器的设计和成本。因为队列容量是有限的,所以当流量强度接近1时,数据包延迟并不会真正接近无穷大。相反,一个数据包到达后会发现队列已满。如果没有地方存储这样的数据包,路由器就会丢弃这个数据包;也就是说,数据包将会丢失。当流量强度大于1时,在交互动画(官网上)中可以再次看到队列溢出。
从端系统的视角来看,丢包看起来就像是一个已经传输到网络核心但从未从目的地网络中出现的数据包。随着流量强度的增加,丢包的比例也会增加。因此,一个节点的性能通常不仅用延迟来衡量,还用丢包的概率来衡量。正如我们将在后续章节中讨论的,丢失的数据包可能会在端到端基础上重新传输,以确保所有数据最终都从源传输到目的地。
1.4.3 端到端延迟
到目前为止,我们的讨论集中在节点延迟上,即单个路由器的延迟。现在让我们考虑从源到目的地的总延迟。为了理解这个概念,假设在源主机和目标主机之间有N - 1个路由器,同时也假设网络不拥堵(这样排队延迟可以忽略不计),每个路由器和源主机的处理延迟为dproc,每个路由器和源主机的传输速率为R比特/秒,每个链路的传播延迟为dprop。那么端到端的延迟为:
dend-end = N(dproc + dtrans + dprop) (1.2)
其中,dtrans = L/R,其中L是数据包大小。注意,方程1.2是方程1.1的推广,方程1.1没有考虑处理和传播延迟。我们把等式1.2推广到节点上的各种延迟和每个节点上存在平均排队延迟的情况。
路由跟踪
为了亲身体验计算机网络中的端到端延迟,我们可以使用Traceroute程序。Traceroute是一个可以在任何互联网主机上运行的简单程序。当用户指定一个目标主机名时,源主机中的程序向该目标发送多个特殊的数据包。当这些数据包向目的地移动时,它们会经过一系列路由器。当一台路由器收到其中一个特殊的数据包时,它就向源发送一条包含了路由器的名称和地址的短消息。
更具体地说,假设在源和目的地之间有N - 1个路由器。然后,源将发送N个特殊数据包到网络中,每个数据包的地址都指向最终目的地。这N个特殊的数据包被标记为1到N,第一个数据包标记为1,最后一个数据包标记为N。当第N个路由器收到标记为N的第N个数据包时,路由器不把数据包转发到目的地,而是向源发送一条消息。当目标主机接收到第n个数据包时,它也将消息返回给源。源记录当它发送一个数据包和当它收到相应的返回消息之间经过的时间;它还记录返回消息的路由器(或目标主机)的名称和地址。通过这种方式,源可以重建数据包从源到目的地所经过的路由,并且可以确定到所有中间路由器的往返延迟。Traceroute实际上重复了刚才描述的实验三次,所以源实际上发送了3n个数据包到目的地。RFC 1393详细描述了Traceroute。
这是路由跟踪程序的输出的一个例子,从源主机gaia.cs.umass.edu大学(马萨诸塞州)到巴黎索邦大学的计算机科学系(以前被称为UPMC大学)的路由追踪。输出有六列:第一列是上面描述的n值,即沿途路由器的编号;第二列是路由器的名称;第三列是路由器的地址(形式为xxx.xxx.xxx.xxx);最后三列是三个实验的往返延迟。如果源从任何给定路由器接收不到三条消息(由于网络中丢包),Traceroute会在路由器编号后面加一个星号,并报告该路由器的往返次数少于三次。
1 gw-vlan-2451.cs.umass.edu (128.119.245.1) 1.899 ms 3.266 ms 3.280 ms
2 j-cs-gw-int-10-240.cs.umass.edu (10.119.240.254) 1.296 ms 1.276 ms
1.245 ms
3 n5-rt-1-1-xe-2-1-0.gw.umass.edu (128.119.3.33) 2.237 ms 2.217 ms
2.187 ms
4 core1-rt-et-5-2-0.gw.umass.edu (128.119.0.9) 0.351 ms 0.392 ms 0.380 ms
5 border1-rt-et-5-0-0.gw.umass.edu (192.80.83.102) 0.345 ms 0.345 ms
0.344 ms
6 nox300gw1-umass-re.nox.org (192.5.89.101) 3.260 ms 0.416 ms 3.127 ms
7 nox300gw1-umass-re.nox.org (192.5.89.101) 3.165 ms 7.326 ms 7.311 ms
8 198.71.45.237 (198.71.45.237) 77.826 ms 77.246 ms 77.744 ms
9 renater-lb1-gw.mx1.par.fr.geant.net (62.40.124.70) 79.357 ms 77.729
79.152 ms
10 193.51.180.109 (193.51.180.109) 78.379 ms 79.936 80.042 ms
11 * 193.51.180.109 (193.51.180.109) 80.640 ms *
12 * 195.221.127.182 (195.221.127.182) 78.408 ms *
13 195.221.127.182 (195.221.127.182) 80.686 ms 80.796 ms 78.434 ms
14 r-upmc1.reseau.jussieu.fr (134.157.254.10) 78.399 ms * 81.353 ms在上面的跟踪中,在源和目的地之间有14个路由器。大多数路由器都有一个名字,而且它们都有地址。例如,Router 4的名字是core1-rt-et-5-2-0.gw.umass.edu,地址是128.119.0.9。查看为同一路由器提供的数据,我们发现在三个试验中的第一个试验中,源和路由器之间的往返延迟为0.351 msec。随后两次试验的往返延迟为0.392和0.380毫秒。这些往返延迟包括刚才讨论的所有延迟,包括传输延迟、传播延迟、路由器处理延迟和排队延迟。
由于排队延迟随时间而变化,因此数据包n发送到路由器n的往返延迟有时会大于数据包n+1发送到路由器n+1的往返延迟。事实上,我们在上面的例子中观察到了这个现象:到Router 12的延迟比到Router 11的延迟要小!还需要注意的是,从路由器7到路由器8的往返延迟大幅增加。这是由于7号和8号路由器之间的跨大西洋光纤链路,造成了相对较大的传播延迟。有许多免费软件程序为Traceroute提供图形界面;我们最喜欢的是PingPlotter [PingPlotter 2020]。
端系统、应用程序和其他延迟
除了处理、传输和传播延迟外,在端系统中还可能存在其他显著的延迟。例如,一个端系统想要将一个数据包传输到一个共享媒体(例如,在一个WiFi或有线调制解调器场景中),可能会有目的地延迟其传输,作为其与其他端系统共享媒体协议的一部分;我们将在第6章详细讨论这些协议。另一个重要的延迟是媒体分组延迟,它存在于VoIP (VoIP)应用中。在VoIP中,发送方必须先用编码的数字化语音填充数据包,然后再将数据包传送到互联网。这个时间将填充一个数据包——称为分组延迟(packetization delay)——可以显著影响用户感知VoIP呼叫的质量。这个问题将在本章最后的作业中进一步探讨。
1.4.4 计算机网络的吞吐量
除了延迟和丢包,计算机网络中另一个关键的性能度量是端到端吞吐量。为了定义吞吐量,考虑通过计算机网络将一个大文件从主机A传输到主机B。这种传输可能是,例如,从一台计算机到另一台计算机的一个大型视频剪辑。任何时刻的瞬时吞吐量是主机B接收文件的速率(以比特/秒为单位)。(许多应用程序在下载时在用户界面中显示瞬时吞吐量,也许你以前已经观察到这一点!你也许想试试使用speedtest应用程序(speedtest 2020)测量您和Internet上的服务器之间的端到端延迟和下载吞吐量。如果文件由F比特组成,主机B接收所有F比特需要T秒,则文件传输的平均吞吐量为F/T 比特/秒。对于某些应用程序(如Internet电话),希望具有较低的延迟和始终高于某个阈值的瞬时吞吐量(例如,对于某些Internet电话应用程序超过24 kbps,对于某些实时视频应用程序超过256 kbps)。对于其他应用程序,包括那些涉及文件传输的应用程序,延迟不是关键,但最好有尽可能高的吞吐量。
为了进一步了解吞吐量的重要概念,让我们考虑几个示例。图1.19(a)显示了两个端系统,一个服务器和一个客户端,由两条通信链路和一个路由器连接。考虑从服务器到客户端的文件传输的吞吐量。设Rs表示服务器到路由器之间的链路速率;Rc表示路由器与客户端之间的链路速率。假设整个网络中唯一被发送的比特是从服务器到客户端的。现在我们要问,在这个理想的场景中,服务器到客户端的吞吐量是多少?为了回答这个问题,我们可以把比特想象成流体,把通信链路想象成管道。很明显,服务器不能以高于Rs bps的速率泵入比特;路由器不能以比Rc bps更快的速率转发比特。如果Rs < Rc,那么服务器泵送的比特将直接通过路由器,并以Rs bps的速率到达客户端,从而获得Rs bps的吞吐量。另一方面,如果是Rs > Rc,那么路由器将不能像它接收比特那样快速地转发比特。在这种情况下,比特只会以Rc的速率离开路由器,提供一个Rc的端到端吞吐量。(还要注意,如果比特继续以Rs的速率到达路由器,并继续以Rc离开路由器,在路由器等待传输给客户端的积压比特将会增加,并产生最不受欢迎的情况!)
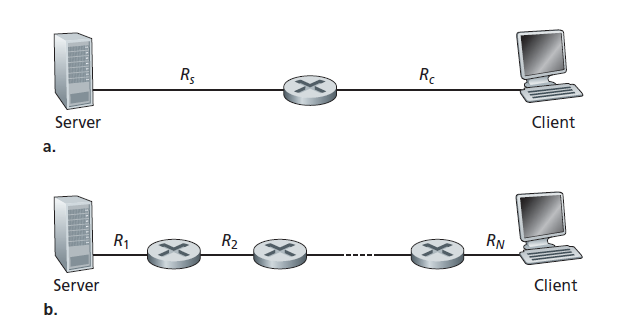
因此,对于这个简单的双链路网络,吞吐量是min{Rc, Rs},也就是说,瓶颈是链路传输速率。在确定了吞吐量之后,我们现在可以将一个F比特的大文件从服务器传输到客户端所需的时间近似为F/min{Rs, Rc}。举一个具体的例子,假设你正在下载一个F = 3200万比特的MP3文件,服务器的传输速率为Rs = 2Mbps,而你有一个Rc = 1Mbps的访问链路。传输文件所需的时间是32秒。当然,这些吞吐量和传输时间的表达式只是近似值,因为它们没有考虑存储和转发、处理延迟以及协议问题。
图1.19(b)现在显示了服务器和客户端之间有N条链路的网络,这N条链路的传输速率为R1、R2、...、RN。应用与双链路网络相同的分析,我们发现从服务器到客户端的文件传输吞吐量为min{R1, R2, ..., RN},这也是服务器和客户端之间的瓶颈链路的传输速率。
现在再考虑另一个受当今互联网推动的例子。图1.20(a)显示了连接到计算机网络的两个端系统,一个服务器和一个客户端。考虑从服务器到客户端的文件传输的吞吐量。服务器与网络之间的接入链路速率为Rs,客户端与网络之间的接入链路速率为Rc。现在假设通信网络核心的所有链路都有很高的传输速率,远高于Rs和Rc。事实上,如今互联网核心被高速链路充分供应,几乎不会发生拥塞。还假设整个网络中发送的唯一比特是那些从服务器到客户端的比特。因为在这个例子中,计算机网络的核心就像一条宽管道,比特从源流到目的地的速率也是Rs和Rc的最小值,也就是说,吞吐量= min{Rs, Rc}。因此,在当今的互联网中,限制吞吐量的因素通常是接入网。
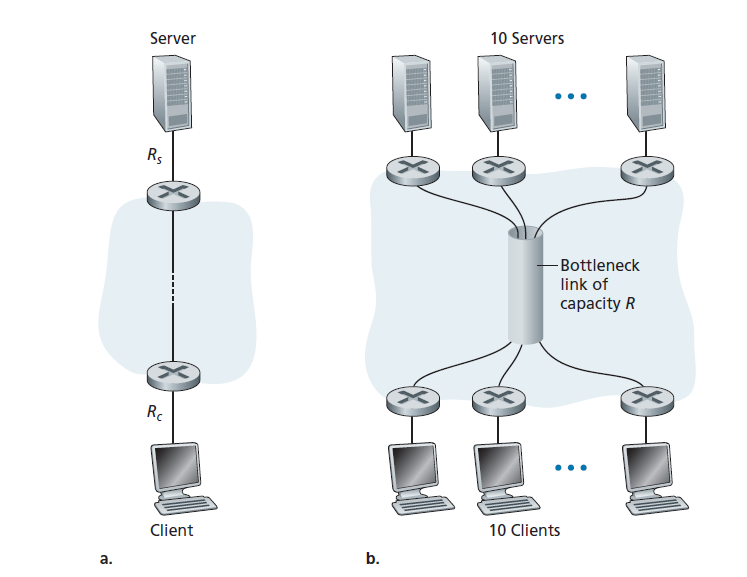
最后一个例子,考虑图1.20(b),其中有10个服务器和10个客户端连接到计算机网络的核心。在本例中,有10个同时进行的下载,涉及10个客户端-服务器对。假设这10次下载是当前网络中的唯一流量。如图所示,在核心中有一个链路,所有10个下载都要经过该链路。以R表示链路R的传输速率,假设所有服务器访问链路有相同的速率Rs,所有客户端访问链路有相同的速率Rc,和所有核心中的链路的传播速率R——远远大于Rs, Rc, R 。现在我们问,下载的吞吐量是多少?显然,如果公共链路的速率R很大,比如比R和Rc大100倍,那么每次下载的吞吐量将再次为min{Rs, Rc}。但如果公共链路的速率与R和Rc的数量级(order)相同呢?在这种情况下吞吐量是多少?让我们看一个具体的例子。假设Rs = 2Mbps, Rc = 1Mbps, R = 5Mbps,公共链路将其传输速率平均分配给10次下载。然后每次下载的瓶颈不再是接入网络,而是核心中的共享链路,它只提供500kbps的吞吐量。因此,每次下载的端到端吞吐量现在减少到500kbps。
图1.19和图1.20(a)中的例子表明吞吐量取决于数据流过的链路的传输速率。我们看到,当没有其他介入流量时,吞吐量可以简单地近似为源和目的地之间路径上的最小传输速率。图1.20(b)中的例子表明,更一般的情况下,吞吐量不仅取决于路径上链路的传输速率,还取决于其间的流量。特别是,如果许多其他数据流也通过该链路,那么具有高传输速率的链路就可能成为文件传输的瓶颈链路。我们将在作业问题和后续章节中更密切地检查计算机网络中的吞吐量。
1.5 协议层及其服务模型
从我们迄今为止的讨论来看,因特网显然是一个极其复杂的系统。我们已经看到因特网有许多部分:许多应用程序和协议、各种类型的端系统、数据包交换机和各种类型的链路级媒体。考虑到这种巨大的复杂性,是否有望组织一个网络架构,或者至少讨论一下网络架构?幸运的是,这两个问题的答案都是肯定的。
分层架构
在试图组织我们对互联网架构的想法之前,让我们来寻找一个人类的类比。事实上,在我们的日常生活中,我们一直在处理复杂的系统。想象一下,如果有人让你描述,例如,航空系统。您将如何找到结构来描述这个复杂的系统,它包含票务代理、行李检查人员、登机口人员、飞行员、飞机、空中交通管制和一个全球范围的飞机路由系统?描述这个系统的一种方法可能是描述您在乘坐航空公司时所采取的一系列行动(或其他人为您采取的行动)。你买了机票,检查你的行李,去登机口,最终上了飞机。飞机起飞并被安排到目的地。飞机降落后,您在登机口下飞机并领取您的行李。如果旅途不愉快,你向票务代理抱怨航班(你的努力没有得到任何回报)。此场景如图1.21所示。
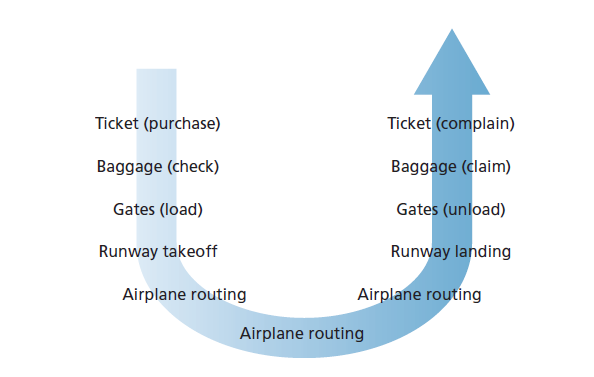
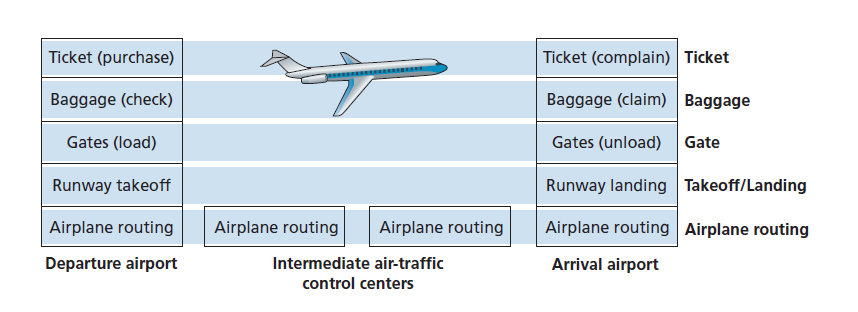
我们已经可以在这里看到一些计算机网络的类比:您将由航空公司从来源地运往目的地;在Internet中,数据包从源主机发送到目标主机。但这并不完全是我们想要的类比。我们正在图1.21中寻找一些结构。查看图1.21,我们注意到在两端都有一个票务功能;还有一个为已购票旅客提供的行李功能,以及一个为已购票和已托运行李旅客提供的登机口功能。对于已经通过登机口的乘客(即已经办理了购票、行李托运和通过登机口的乘客),有一个起飞和降落功能,在飞行中,有一个飞机出行功能。这表明我们可以以水平方式查看图1.21中的功能,如图1.22所示。
图1.22将航空公司功能划分为多个层,提供了一个框架,我们可以在其中讨论航空公司旅行。请注意,每一层与其下面的层结合起来,实现一些功能和一些服务。在票务层及其以下,完成一个人从一个航空公司柜台到另一个航空公司柜台的转移。在行李层及以下,完成从行李寄存到行李领取的人员和行李的转移。请注意,行李层只向已经订票的人提供这项服务。在登机口层,完成从登机口到到达登机口的人员和行李的转移。在起飞/降落层,跑道到跑道的人员和他们的行李转移已经完成。
分层架构允许我们讨论大型复杂系统中定义良好的特定部分。这种简化本身具有相当大的价值,因为它提供了模块化,可以更容易地更改由该层提供的服务的实现。只要该层向其上一层提供相同的服务,并使用其下一层的相同服务,那么当一个层的实现发生改变时,系统的其余部分将保持不变。(注意改变服务的实现与改变服务本身有很大的不同!)例如,如果改变了登机口的功能(例如,根据高度要求乘客登机和下机),航空系统的其余部分将保持不变,因为登机口层仍然提供相同的功能(乘客登机和下机);它只是在更改后以不同的方式实现该功能。对于不断更新的大型复杂系统,更改服务的实现而不影响系统的其他组件的能力是分层的另一个重要优势。
协议层
关于航空公司就说这么多。现在让我们把注意力转向网络协议。为了给网络协议的设计提供结构,网络设计者组织协议,网络硬件和软件分层地实现协议。每个协议都属于一个层,就像图1.22中的航空体系结构中的每个功能都属于一个层一样。我们再次感兴趣的是一个层在所谓的层的服务模型之上提供给另一个层的服务。就像在我们的航空公司示例中一样,每个层通过(1)在该层中执行某些操作以及(2)使用其下面的层的服务来提供其服务。例如,第n层提供的服务可能包括从网络的一端到另一端的可靠消息传递。这可以通过使用n - 1层的不可靠的边缘到边缘消息传递服务来实现,并添加n层功能来检测和重传丢失的消息。
协议层可以在软件、硬件或两者的结合中实现。应用层协议,如HTTP和SMTP,几乎总是在端系统的软件中实现;传输层协议也是如此。因为物理层和数据链路层负责处理特定链路上的通信,它们通常在与给定链路相关联的网络接口卡(例如,以太网或WiFi接口卡)中实现。网络层通常是硬件和软件的混合实现。还要注意,就像分层航空体系结构中的功能分布在组成系统的各个机场和飞行控制中心之间一样,n层协议也分布在组成网络的端系统、数据包交换机和其他组件之间。也就是说,在每个网络组件中通常都有一个层n个协议。
协议分层具有概念上和结构上的优点[RFC 3439]。正如我们所看到的,分层提供了一种结构化的方法来讨论系统组件。模块化使得更新系统组件更加容易。然而,我们提到,一些研究人员和网络工程师强烈反对分层[Wakeman 1992]。分层的一个潜在缺点是,一个层可能复制较低层的功能。例如,许多协议栈提供了基于每个链路和端到端两种基础的错误恢复。第二个潜在的缺点是,一层的功能可能需要只在另一层存在的信息(例如时间戳值);这违背了层分离的目标。
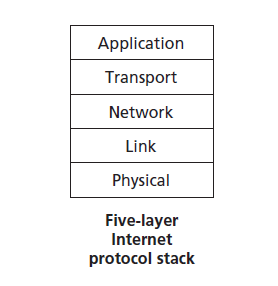
当把不同层的协议放在一起时,它们被称为协议栈。Internet协议栈由5层组成:物理层、链路层、网络层、传输层和应用层,如图1.23所示。如果您查看目录,您将看到我们使用互联网协议栈的各个层粗略地组织了这本书。我们采用自顶向下的方法,首先覆盖应用层,然后向下进行。
应用层
应用层是网络应用程序及其应用层协议所在的层。Internet的应用层包括许多协议,如HTTP协议(提供Web文档请求和传输)、SMTP协议(提供电子邮件消息的传输)和FTP协议(提供在两个端系统之间传输文件)。我们将看到某些网络功能,例如将Internet端系统的友好名称(如www.ietf.org)翻译为32位网络地址,也是在特定的应用层协议(即域名系统(DNS))的帮助下完成的。
应用层协议分布在多个端系统上,一端系统中的应用程序通过该协议与另一端系统中的应用程序交换数据包。我们将应用层的这个数据包称为 消息(message) 。
传输层
Internet的传输层在应用程序端点之间传输应用层消息。在Internet中,有两种传输协议,TCP和UDP,其中任何一种都可以传输应用层消息。TCP为其应用程序提供面向连接的服务。该服务包括有保障的应用层消息到目的地的传输和流量控制(即发送方/接收方速度匹配)。TCP还将长消息分成更短的段segment),并提供一种拥塞控制机制,以便在网络拥塞时,源控制其传输速率。UDP协议为其应用程序提供无连接的服务。这是一种不提供可靠性、流量控制和拥塞控制的简单服务。在本书中,我们将传输层数据包称为 段(segment) 。
网络层
因特网的网络层负责将称为 数据报(datagrams) 的网络层数据包从一台主机移动到另一台主机。源主机中的Internet传输层协议(TCP或UDP)将传输层段和目的地地址传递给网络层,就像您将带有目的地地址的信件交给邮政服务一样。然后网络层提供将段交付到目标主机中的传输层的服务。
因特网的网络层包括著名的IP协议,它定义了数据报中的字段以及端系统和路由器如何按照这些字段行事,所有具有网络层的Internet组件都必须运行IP协议。Internet的网络层还包含路由协议,这些协议决定数据报在源和目的地之间的路由。Internet有许多路由协议。正如我们在1.3节中看到的,Internet是一个网络的网络,在一个网络中,网络管理员可以运行任何需要的路由协议。虽然网络层包含IP协议和许多路由协议,但它通常被简单地称为IP层,反映了IP是将Internet粘合在一起的粘合剂这一事实。
链路层
因特网的网络层通过源和目的地之间的一系列路由器路由数据报。要将数据包从一个节点(主机或路由器)移动到路由中的下一个节点,网络层依赖于链路层的服务。特别是,在每个节点上,网络层将数据报向下传递给链路层,链路层将数据报传递给路由上的下一个节点。在下一个节点上,链路层将数据报传递给网络层。
链路层提供的服务依赖于链路上使用的特定链路层协议。例如,一些链路层协议提供可靠的传输,从传输节点经过链路到接收节点。请注意,这种可靠的交付服务不同于TCP的可靠交付服务,后者提供从一端系统到另一端系统的可靠交付。链路层协议的例子包括以太网、WiFi和有线接入网的DOCSIS协议。由于数据报通常需要遍历多条链路才能从源到达目的地,因此数据报可以在其路由的不同链路上由不同的链路层协议处理。例如,一个数据报可以在一条链路上由以太网处理,在另一条链路上由PPP处理。网络层将从每个不同的链路层协议接收不同的服务。在本书中,我们将把链路层数据包称为 帧(frames) 。
物理层
链路层的工作是将整个帧从一个网络单元移动到邻近的网络单元,而物理层的工作是将帧中的单个比特从一个节点移动到下一个节点。这一层的协议再次依赖于链路,并进一步依赖于链路的实际传输介质(如双绞线、单模光纤)。例如,以太网有许多物理层协议:一个用于双绞铜线,另一个用于同轴电缆,另一个用于光纤,等等。在每一种情况下,一个比特以不同的方式在链路上移动。
1.5.2 封装
图1.24显示了数据从发送端系统协议栈到中间链路层交换机和路由器协议栈的物理路径,然后在接收端系统的协议栈上。正如我们在本书后面讨论的,路由器和链路层交换机都是数据包交换机。与端系统类似,路由器和链路层交换机将它们的网络硬件和软件组织成层。但是路由器和链路层交换机并没有实现协议栈中的所有层;它们通常只实现底层。如图1.24所示,链路层交换机实现了第一层和第二层;路由器实现第1层到第3层。这意味着,例如,Internet路由器能够实现IP协议(一种第三层协议),而链路层交换机则不能。我们将在后面看到,虽然链路层交换机不能识别IP地址,但它们能够识别第2层地址,比如以太网地址。请注意,主机实现了所有五个层;这与Internet架构将其大部分复杂性置于网络边缘的观点是一致的。
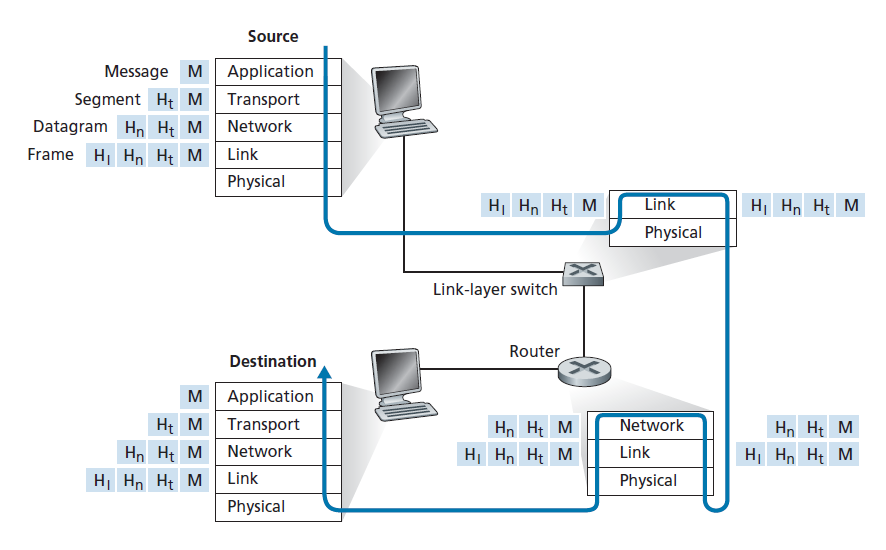
图1.24还说明了封装的重要概念。在主机上,一个 应用层消息 (图1.24中的M)被传递给传输层。在最简单的情况下,传输层接受消息并附加将被传输层接收端使用的附加信息(图1.24中所谓的传输层头信息,Ht)。应用层消息和传输层头信息共同构成 传输层段 。传输层段因此封装了应用层消息。添加的信息可能包括允许传输层接收方将消息传递到适当的应用程序的信息,以及允许接收方确定消息中的比特是否在路由中被更改的错误检测(error-detection)比特。然后传输层将这个段传递给网络层,网络层增加网络层头信息(图1.24中的Hn),如源端系统地址和目标端系统地址,创建一个 网络层数据报 。然后数据报被传递给链路层,链路层将添加它自己的链路层头信息,并创建一个 链路层帧 。因此,我们看到在每一层,一个数据包有两种类型的字段:头字段和 有效负载字段(payload field) 。负载字段通常是来自上面一层的一个数据包。
一个有用的类比是通过公共邮政服务将办公室间备忘录从一个公司分公司发送到另一个公司分公司。假设在一个分公司的Alice想要给在另一个分公司的Bob发送一份备忘录。备忘录类似于应用层消息。Alice把备忘录放在一个办公室间的信封里,信封的正面写着Bob的名字和所在部门。办公室间信封类似于传输层段,它包含头信息(Bob的姓名和部门号),并封装应用层消息(备忘录)。当发送分支机构收发室收到办公室间的信封时,它将办公室间的信封放入另一个适合通过公共邮政服务发送的信封中。发信收发室还将各发信分支机构的邮寄地址写在信封上。邮政信封与数据报类似,它封装传输层段(办公室间信封),传输层段封装原始消息(备忘录)。邮政业务将邮政信封递送到分社收发室。在那里,解封装的过程开始了。收发室提取办公室间的备忘录,并将其转发给Bob。最后,Bob打开信封并删除了备忘录。
封装过程可能比上面描述的更复杂。例如,一个大消息可以被划分为多个传输层段(每个传输层段本身可能被划分为多个网络层数据报)。在接收端,这样的段必须从它的组成数据报重建。
1.6 网络攻击
今天,互联网已经成为许多机构的关键任务,包括大公司和小公司、大学和政府机构。许多人还依赖互联网进行许多职业、社交和个人活动。数以亿计的东西,包括可穿戴设备和家庭设备,正在连接到互联网。但在所有这些实用和刺激的背后,也有黑暗的一面,一个坏家伙试图破坏我们的日常生活,通过破坏我们与互联网相连的电脑,侵犯我们的隐私,并使我们依赖的互联网服务无法运行。
网络安全领域是关于坏人如何攻击计算机网络,以及我们这些即将成为计算机网络专家的人如何保护网络免受这些攻击,或者更好的是,设计一开始就对这些攻击免疫的新架构。鉴于现有攻击的频率和种类,以及新的和更具破坏性的未来攻击的威胁,网络安全已成为计算机网络领域的中心话题。这本书的特点之一是,它把网络安全问题带到最前沿。
由于我们还没有计算机网络和因特网协议方面的专业知识,我们将在这里开始调查一些今天更普遍的安全相关问题。这将激发我们在接下来的章节中进行更实质性讨论的欲望。所以我们从这个简单的问题开始,怎么会出错?计算机网络为什么脆弱?今天比较普遍的攻击类型有哪些?
坏人可以通过互联网将恶意软件植入你的主机
我们将设备连接到互联网上,因为我们想从互联网接收/发送数据。这包括各种各样的好东西,包括Instagram帖子,互联网搜索结果,流媒体音乐、视频会议电话、流媒体电影等等。但是,不幸的是,伴随着这些好东西而来的是恶意软件,它们也可以进入并感染我们的设备。一旦恶意软件感染我们的设备,它可以做各种各样的狡猾的事情,包括删除我们的文件和安装收集我们的私人信息的间谍软件,例如!社会保险号(美)、密码和击键(keystrokes),然后把这些信息(当然是通过互联网!)发回给坏人。我们妥协的主机也可能卷入一个由数千个类似的被破坏设备组成的网络中,统称为僵尸网络(botnet),这些坏人控制并利用它来分发垃圾邮件或对目标主机进行分布式拒绝服务攻击(即将讨论)。
如今,很多恶意软件都是自我复制的:一旦它感染了一台主机,它就会从那台主机寻找进入互联网上其他主机的途径,并从新感染的主机中寻找进入更多主机的途径。通过这种方式,自我复制的恶意软件可以以指数级的速度传播。
坏人可以攻击服务器和网络基础设施
另一类广泛的安全威胁称为拒绝服务攻击。顾名思义,DoS攻击会使合法用户无法使用网络、主机或其他基础设施。Web服务器、电子邮件服务器、DNS服务器(在第二章中讨论)和机构网络都可能受到DoS攻击。Digital Attack Map网站允许使用可视化的世界范围内最严重的每日DoS攻击[DAM 2020]。大多数因特网DoS攻击可分为三类之一:
- 漏洞攻击 这涉及向目标主机上运行的脆弱应用程序或操作系统发送一些精心设计的消息。如果将正确的数据包序列发送到易受攻击的应用程序或操作系统,服务可能会停止,更糟的是,主机可能会崩溃。
- Bandwidth flooding 攻击者向目标主机发送大量的数据包,使目标主机的访问链路阻塞,使合法的数据包无法到达服务器。
- Connection flooding 攻击者在目标主机上建立大量的半打开或完全打开的TCP连接(TCP连接在第三章中讨论)。主机可能会陷入这些虚假连接的泥潭,从而停止接受合法连接。
现在让我们更详细地研究带宽洪水攻击。回顾我们在第1.4.2节中讨论的延迟和丢包分析,很明显,如果服务器的访问速率为R bps,那么攻击者将需要以大约R bps的速率发送流量才能造成破坏。如果R值非常大,单个攻击源可能无法产生足够的流量来伤害服务器。此外,如果所有流量来自单一源,上行路由器可能能够检测到攻击,并在流量接近服务器之前阻断来自该源的所有流量。在分布式DoS (DDoS)攻击中,如图1.25所示,攻击者控制了多个源,并且每个源爆破流量都锁定目标处。使用这种方法,所有受控源的聚合流量速率需要大约为R,才能削弱服务器。DDoS攻击利用成千上万个主机组成的僵尸网络,这在今天是常见的[DAM 2020]。DDos攻击比来自单个主机的DoS攻击更难检测和防御。
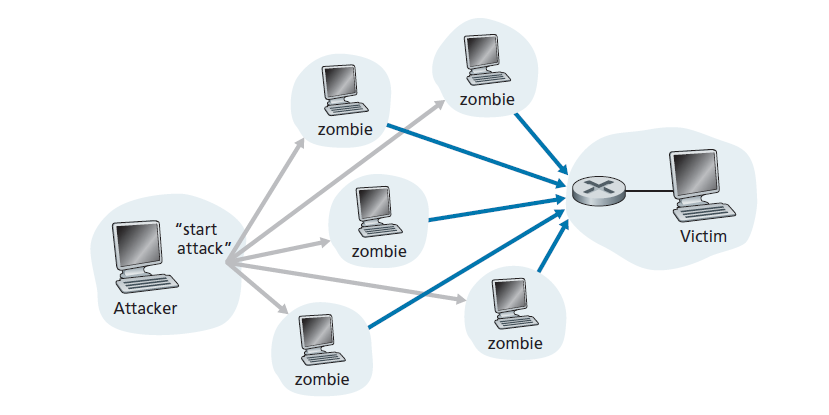
我们鼓励您在阅读本书时考虑以下问题:计算机网络设计师如何防范DoS攻击?我们将看到,三种类型的DoS攻击需要不同的防御。
坏人可以嗅探数据包
如今,许多用户通过无线设备接入互联网,如连接wifi的笔记本电脑或带有蜂窝网络连接的手持设备(见第7章)。虽然无处不在的互联网接入非常方便,并为移动用户带来奇妙的新应用程序,在无线发射器附近放置被动接收器也会造成重大的安全漏洞。接收器可以获得传输的每个数据包的副本!这些数据包可以包含各种敏感信息,包括密码、社会保障码、商业机密和私人信息。一个被动的接收器,记录每一个经过的数据包的副本,称为 数据包嗅探器 。
嗅探器也可以部署在有线环境中。在有线广播环境中,就像在许多以太网局域网中一样,数据包嗅探器可以获得通过局域网发送的广播数据包的副本。如第1.2节所述,有线接入技术也广播数据包,因此容易被嗅探。此外,如果一个坏人能够访问机构网络的接入路由器或链路,他可能会植入一个嗅探器,复制经过该组织的每个数据包。然后嗅探数据包可以离线分析敏感信息。
数据包嗅探软件可以在各种网站上免费获得,也可以作为商业产品获得。讲授网络课程的教授们经常布置实验练习,包括编写数据包嗅探和应用层数据重构程序。实际上,与本文相关的Wireshark [Wireshark 2020]实验室(见本章末尾介绍的Wireshark实验室)就使用了这种数据包嗅探器。
因为数据包嗅探器是被动的,也就是说,它们不会将包注入到难以检测到的信道中。因此,当我们向无线信道发送数据包时,我们必须接受这样的可能性,即某些坏人可能正在记录我们数据包的副本。正如您可能已经猜到的,针对数据包嗅探的一些最佳防御方法涉及到加密。我们将在第8章中研究密码学在网络安全中的应用。
坏人可以伪装成你信任的人
非常容易创建一个数据包和一个任意的源地址,数据包内容,和目的地地址,然后发送这个手工数据包到互联网,将数据包转发到目的地。想象一下,毫无怀疑的接收方(比如互联网路由器)收到这样一个数据包,认为(假的)源地址是真实的,然后执行嵌入到数据包内容中的一些命令(比如修改它的转发表)。将带有虚假源地址的数据包注入Internet的能力被称为 IP欺骗(IP spoofing) ,这只是一个用户可以伪装成另一个用户的许多方法之一。
为了解决这个问题,我们将需要 端点身份验证(end-point authentication) ,即一种允许我们确定消息是否来自我们认为它来自的地方的机制。在阅读本书的各个章节时,我们再次鼓励您考虑如何为网络应用程序和协议做到这一点。我们将在第8章探讨端点身份验证机制。
在结束这一节时,值得考虑一下互联网最初是如何变成这样一个不安全的地方的。从本质上说,答案是互联网最初就是这样设计的,基于一组相互信任的用户连接到透明网络的模型[Blumenthal 2001],在这个模型中(根据定义)没有安全的需要。原始互联网架构的许多方面深刻地反映了这种相互信任的概念。例如,默认情况下,一个用户向任何其他用户发送数据包的能力,而不是请求/授予的能力,并且默认情况下,用户身份采用声明的面值,而不是通过身份验证。
但今天的互联网肯定不全是“相互信任的用户”。尽管如此,当今用户仍然需要交流时不要完全信任对方,可能希望匿名通信,可能通过第三方间接通信(例如,Web缓存,我们会在第二章研究,或mobilityassisting代理,我们将在第7章研究),并可能不信任硬件,软件,甚至是它们交流的空气。随着本书的深入,我们现在面临着许多与安全相关的挑战:我们应该寻求针对嗅探、端点伪装、中间人攻击、DDoS攻击、恶意软件等的防御。我们应该记住,相互信任的用户之间的通信是例外而不是规则。欢迎来到现代计算机网络世界。
1.7 计算机网络和因特网的历史
第1.1至1.6节概述了计算机联网和因特网技术。现在你应该知道足够的知识来打动你的家人和朋友了!然而,如果你真的想在下一次的鸡尾酒会上大获成功,你应该在你的演讲中点缀一些关于互联网迷人历史的花絮(Segaller 1998)。
1.7.1 数据包交换的发展:1961 - 1972
计算机网络和今天的因特网的起源可以追溯到20世纪60年代初,当时电话网络是世界上占主导地位的通信网络。回想一下第1.3节,电话网使用线路交换将信息从发送方传输到接收方,这是一个适当的选择,因为发送方和接收方之间的声音传输速率是恒定的。考虑到20世纪60年代早期计算机的重要性日益增加,以及分时(timeshared)计算机的出现,考虑如何将计算机连接在一起,以便在地理位置上分布式的用户共享它们。此类用户产生的流量很可能是突发——间歇活跃的,比如向远程计算机发送命令,然后是等待响应或考虑接收到的响应时的不活动时间。
世界上有三个研究小组,每个小组都不知道其他小组的工作[Leiner 1998],他们开始发明数据包交换,作为线路交换的一种高效、可靠的替代方案。第一个发表的关于数据包交换技术的工作是Leonard Kleinrock的[Kleinrock 1961;Kleinrock 1964年],当时是麻省理工学院的研究生。利用排队论,Kleinrock的工作优雅地证明了数据包交换方法对突发流量源的有效性。1964年,兰德研究所的Paul Baran [Baran 1964]开始研究数据包交换在军事网络上的安全语音中的应用,而在英国的国家物理实验室,Donald Davies和Roger Scantlebury也在开发他们关于数据包交换的想法。
麻省理工学院、兰德公司和国家物理实验室的工作奠定了今天的互联网的基础。但是,互联网也有着悠久的“让它建造它并展示它”的历史,这种态度也可以追溯到20世纪60年代。J. C. R. Licklider[1990年12月]和Lawrence Roberts是Kleinrock在麻省理工学院的同事,他们后来在美国高级研究计划局(ARPA)领导了计算机科学项目。Roberts发表了ARPAnet的总体计划[Roberts 1967],这是第一个数据包交换计算机网络,也是今天公共因特网的直接祖先。1969年的劳动节,第一个数据包交换机在Kleinrock的监督下在加州大学洛杉矶分校安装,随后不久又在斯坦福研究所(SRI)、加州大学圣巴巴拉分校和犹他大学安装了另外三个数据包交换机(图1.26)。到1969年底,互联网的雏形已经有了四个节点。Kleinrock回忆起第一次使用该网络执行从UCLA到SRI的远程登录时,系统崩溃[Kleinrock 2004]。
到1972年,ARPAnet已经增长到大约15个节点,并由Robert Kahn首次公开演示。ARPAnet端系统之间的第一个主机到主机协议,被称为网络控制协议(NCP),已经完成[RFC 001]。有了端到端协议,现在就可以编写应用程序了。雷·汤姆林森在1972年编写了第一个电子邮件程序。
1.7.3 专有网络和互连:1972年1980年
最初的ARPAnet是一个单一的、封闭的网络。为了与一个ARPAnet主机通信,一个主机必须实际连接到另一个ARPAnet IMP。在20世纪70年代早期到中期,除了ARPAnet之外,附加的独立的数据包交换网络出现了:ALOHANet,一个微波网络,连接夏威夷群岛上的大学[Abramson 1970],以及DARPA的分组卫星[RFC 829]和分组无线电网络[Kahn 1978];Telenet, BBN的一种商业的基于ARPAnet技术的数据包交换网络;由Louis Pouzin首创的法国数据包交换网络Cyclades [Think 2012];分时网络,如Tymnet和GE信息服务网络等,在60年代末和70年代初[Schwartz 1977];IBM的SNA(1969年1974年),与ARPAnet的工作并行[施瓦茨1977年]。
网络的数量在增长。有了完美的后见之明,我们可以看到,开发一个将网络连接在一起的全面架构的时机已经成熟。互联网络的开创性工作(在美国国防高级研究计划局(DARPA)的赞助下),本质上是创造一个网络的网络,是由Vinton Cerf和Robert Kahn (Cerf 1974)完成的;人们创造了“internetting”这个词来描述这项工作。
这些体系结构原则体现在TCP中。但是,TCP的早期版本与现在的TCP有很大的不同。早期版本的TCP通过端系统重传(仍然是今天TCP的一部分)和转发功能(今天由IP执行)实现了可靠的、顺序的数据传输。早期对TCP的实验,结合对不可靠、非流量控制、端到端传输服务(如分组语音)的重要性的认识,导致了IP与TCP的分离和UDP协议的开发。我们今天看到的三个关键的互联网协议TCP、UDP和IP在20世纪70年代末概念上已经就位。
除了DARPA与互联网相关的研究,许多其他重要的联网活动也在进行中。在夏威夷,诺曼·艾布拉姆森(Norman Abramson)正在开发ALOHAnet,这是一种基于分组的无线网络,可以让夏威夷群岛上的多个远程站点相互通信。ALOHA协议[Abramson 1970]是第一个多访问协议,允许地理上分布的用户共享单一广播通信媒体(无线电频率)。梅特卡夫和博格斯在开发用于有线共享广播网络的以太网协议(梅特卡夫,1976年)时,建立在艾布拉姆森的多接入协议工作的基础上。有趣的是,Metcalfe和Boggs以太网协议的动机是需要连接多台pc、打印机和共享磁盘[Perkins 1994]。25年前,早在PC革命和网络爆炸之前,梅特卡夫和博格斯就为今天的PC局域网奠定了基础。
1.7.3 互联网的萌芽 1980–1990
到20世纪70年代末,大约有200台主机连接到ARPAnet。到20世纪80年代末,连接到公共互联网的主机数量达到10万台,这个网络联盟看起来很像今天的互联网。20世纪80年代是一个巨大增长的时期。
这一增长很大程度上是由于几个不同的成果,以创建连接各大学的计算机网络。BITNET提供东北几所大学之间的电子邮件和文件传输。CSNET(计算机科学网络)的成立是为了将无法访问ARPAnet的大学研究人员联系起来。1986年,美国国家科学基金网(NSFNET)成立,提供对美国国家科学基金资助的超级计算中心的访问。从最初56kbps的主干速度开始,NSFNET的主干将在这个十年结束时以1.5 Mbps的速度运行,并将作为连接区域网络的主要主干。
在ARPAnet社区中,今天的Internet架构的许多最后部分已经就位。1983年1月1日,TCP/IP正式部署,成为ARPAnet的新标准主机协议(取代NCP协议)。从NCP到TCP/IP的过渡[RFC 801]是一个标志日事件,所有主机都需要在那天转移到TCP/IP。在20世纪80年代末,对TCP进行了重要的扩展,以实现基于主机的拥塞控制[Jacobson 1988]。DNS,用来映射一个人类可读的互联网名称(例如,gaia.c.s.umass .edu)和它的32位IP地址,也被开发[RFC 1034]。
在开发ARPAnet(大部分是美国的努力)的同时,法国在20世纪80年代早期启动了Minitel项目,这是一个雄心勃勃的计划,将数据网络带入每个人的家庭。Minitel系统由法国政府赞助,由公共数据包交换网络(基于X.25协议套件)、Minitel服务器和内置低速调制解调器的廉价终端组成。1984年,当法国政府向每个想要一台Minitel终端的家庭免费赠送一台Minitel终端时,Minitel获得了巨大的成功。Minitel网站包括免费网站,如电话簿网站和私人网站,这些网站根据用户的使用情况收取费用。在20世纪90年代中期的鼎盛时期,它提供了2万多种服务,从家庭银行业务到专业研究数据库。Minitel在法国家庭中占很大比例!在大多数美国人还没有听说过互联网之前。
1.7.4 互联网的爆发:1990s
20世纪90年代伴随着一系列标志着互联网持续发展和即将到来的商业化的事件而到来。ARPAnet,因特网的鼻祖,不复存在。1991年,国家科学基金网络取消了对国家科学基金网络用于商业目的的限制。NSFNET本身将于1995年退役,互联网骨干流量由商业互联网服务提供商承载。
20世纪90年代的主要事件是万维网应用程序的出现,它把互联网带进了全世界数百万人的家庭和企业。Web作为一个平台,启用和部署了数百个我们今天认为理所当然的新应用程序,包括搜索(如谷歌和Bing)、互联网商务(如亚马逊和eBay)和社交网络(如Facebook)。
万维网是由Tim Berners-Lee在1989年到1991年之间在欧洲核子研究中心发明的(Berners-Lee 1989),基于Vannevar Bush (Bush 1945)和Ted Nelson (Xanadu 2012)在20世纪40年代早期关于超文本的研究成果。Berners-Lee和他的同事开发了HTML、HTTP、Web服务器和浏览器的初始版本,这是Web的四个关键组件。大约在1993年底,大约有200个Web服务器在运行,这些服务器的集合只是即将到来的一个先兆。大约在这个时候,一些研究人员正在开发带有GUI界面的网络浏览器,其中包括马克·安德森,他和吉姆·克拉克一起成立了马赛克通信公司,后来成为网景通信公司[Cusumano 1998;Quittner 1998]。到1995年,大学生每天都在使用网景浏览器上网。大约在这个时候,大大小小的公司开始运作Web服务器和通过Web进行商务交易。1996年,微软开始生产浏览器,这引发了网景和微软之间的浏览器战争,几年后微软赢得了这场战争[Cusumano 1998]。
20世纪90年代后半期是互联网飞速发展和创新的时期,大公司和数以千计的初创公司都在创造互联网产品和服务。到本世纪末,互联网支持了数百种流行的应用程序,其中包括四种杀手级应用程序:
- 电子邮件,包括附件和Web-accessible电子邮件
- 网络,包括网络浏览和互联网商务
- 带有联系人列表的即时消息传递
- 点对点文件共享mp3,由Napster开创
有趣的是,前两个杀手级应用来自于研究界,而后两个则是由一些年轻的企业家创造的。
从1995年到2001年,互联网在金融市场上的表现如同过山车。在它们甚至还没有盈利之前,数百家互联网初创公司进行了首次公开募股,并开始在股票市场上交易。许多公司的估值高达数十亿美元,却没有任何可观的收入来源。互联网股票在2000 - 2001年崩盘,许多初创公司倒闭。然而,一些公司在互联网领域成为了大赢家,包括微软、思科、雅虎、eBay、谷歌和亚马逊。
1.7.5 新千年
在21世纪的头20年里,也许没有任何一项技术比互联网和联网的智能手机更能改变社会。计算机网络方面的创新也在快速发展。在各个方面都取得了进展,包括在接入网和网络骨干网部署更快的路由器和更高的传输速度。但下面的事态发展值得特别注意:
- 自本世纪初以来,我们已经看到宽带互联网接入家庭的积极部署,不仅有线调制解调器和DSL,而且还有光纤到家庭,现在如第1.2节所讨论的5G固定无线。这种高速的互联网接入为丰富的视频应用程序奠定了基础,包括用户生成视频的分发(例如YouTube)、点播电影和电视节目流媒体(例如Netflix)和多人视频会议(例如Skype、Facetime和谷歌Hangouts)。
- 高速无线互联网接入的日益普及,不仅使人们在旅途中保持与外界的持续联系成为可能,也使Yelp、Tinder和Waz等新的定位应用程序成为可能。2011年连接到互联网的无线设备的数量超过了有线设备的数量。这种高速无线接入为手持电脑(iphone、android、ipad等)的迅速出现奠定了基础,这些电脑可以持续、不受限制地接入互联网。
- Facebook、Instagram、Twitter和微信(在中国非常流行)等在线社交网络在互联网上创建了大量的人际网络。这些社交网络中有许多被广泛用于消息传递和照片分享。如今,许多互联网用户主要生活在一个或多个社交网络中。通过他们的api,在线社交网络为新的网络应用创造了平台,包括移动支付和分布式游戏。
- 正如第1.3.3节所讨论的,在线服务提供商,如谷歌和Microsoft,已经部署了他们自己的广泛的私有网络,这些网络不仅将他们的全球分布式数据中心连接在一起,而且还被用来通过直接与较低级的ISP对等连接,尽可能地绕过Internet。因此,谷歌就像在自己的计算机上运行数据中心一样,几乎在瞬间提供搜索结果和电子邮件访问。
- 亚马逊的“EC2”、微软的“Azure”、阿里巴巴的“云”等,很多电子商务企业都在云上运行应用程序。许多公司和大学也将他们的互联网应用(如电子邮件和Web托管)迁移到云上。云计算公司不仅为应用程序提供可扩展的计算和存储环境,而且还为应用程序提供对其高性能私有网络的隐式访问。
1.8 总结
在本章中,我们已经讨论了大量的材料!我们已经了解了各种硬件和软件,它们组成了因特网(特别是Internet)和一般的计算机网络。我们从网络的边缘开始,查看端系统和应用程序,以及为运行在端系统上的应用程序提供的传输服务。我们还研究了接入网中常见的链路层技术和物理媒体。然后我们深入到网络内部,深入到网络核心,确定数据包交换和线路交换是通过电信网络传输数据的两种基本方法,并且我们检查了每种方法的优缺点。我们还研究了全球互联网的结构,了解到互联网是一个网络的网络。我们看到,互联网的等级结构,由更高一级和更低一级的ISP组成,使它能够扩展到包括数千个网络。
在本介绍性章节的第二部分中,我们研究了计算机网络领域的几个核心主题。我们首先检查了在数据包交换网络中延迟、吞吐量和丢包的原因。我们为传输、传播和排队延迟以及吞吐量开发了简单的定量模型;在本书的作业问题中,我们将广泛地使用这些延迟模型。接下来,我们讨论了协议分层和服务模型,这是网络中的关键架构原则,我们也将在本书中引用这些原则。我们还调查了互联网上一些更普遍的安全攻击。我们以计算机网络的简史结束了对网络的介绍。第一章本身包括一个关于计算机网络的小型课程。
这本书的路线图
在开始任何旅程之前,你都应该先看一下路线图,以便熟悉前方的主要道路和路口。对于我们即将踏上的旅程,最终的目的地是深刻理解计算机网络的方式、内容和原因。我们的路线图是本书各章的顺序:
- 计算机网络与因特网
- 应用程序层
- 传输层
- 网络层:数据平面
- 网络层:控制平面
- 链路层和局域网
- 无线及移动网络
- 计算机网络的安全
第二章到第六章是本书的五个核心章节。我们的旅程将从Internet协议栈的顶部开始,即应用层,并将向下工作。这种自上而下的过程背后的基本原理是,一旦我们理解了应用程序,我们就可以理解支持这些应用程序所需的网络服务。然后,我们可以依次检查网络体系结构实现这些服务的各种方式。尽早地介绍应用程序可以为本文的其余部分提供动力。
本书的后半部分第7章和第8章聚焦于现代计算机网络中两个极其重要(且有些独立)的主题。在第七章中,我们研究了无线和移动网络,包括无线局域网(包括WiFi和蓝牙),蜂窝网络(包括4G和5G),以及移动性。第8章,处理计算机网络的安全,首先看加密和网络安全的基础,然后我们检查基本理论是如何被广泛应用于互联网环境的。
Wireshark实验室
不闻不若闻之,闻之不若见之;见之不若知之,知之不若行之;学至于行而止矣 --荀子
通过观察网络协议的实际运行,观察两个协议实体之间交换的消息序列,钻研协议操作的细节,导致协议执行某些操作,人们对网络协议的理解通常会大大加深。观察这些行为及其后果。这可以在模拟场景或真实的网络环境(如Internet)中完成。教材网站上的交互式动画采用了第一种方法。在Wireshark实验室中,我们将采用后一种方法。您可以在各种场景中运行网络应用程序,在您的书桌上、家里或实验室中使用计算机。您将观察计算机中的网络协议,与Internet上其他地方执行的协议实体进行交互和交换消息。因此,你和你的电脑将成为这些活体实验室的组成部分。你会观察,你会从实践中学习。
用于观察执行协议实体之间交换的消息的基本工具称为包嗅探器。顾名思义,包嗅探器被动地复制(嗅探)计算机发送和接收的消息;它还显示这些捕获消息的各种协议字段的内容。Wireshark报文嗅探器的界面截图如图1.28所示。Wireshark是一个免费的数据包嗅探器,运行在Windows, Linux/Unix和Mac电脑上。在本书中,您将找到Wireshark实验室,它们允许您探索本章中研究的许多协议。在这个第一个Wireshark实验室中,您将获得并安装一个Wireshark的副本,访问一个Web站点,捕获并检查Web浏览器和Web服务器之间交换的协议消息。
您可以在www.pearson.com/cs-resources网站上找到关于第一个Wireshark实验室的详细信息(包括关于如何获取和安装Wireshark的说明)。