第13章 算法
第13章 算法
简介
迭代器的使用
迭代器类型
- 流迭代器
谓词的使用
算法概述
并行算法
建议
13.1 简介
一个数据结构,比如列表或向量,本身并不怎么有用。为了使用它们,我们需要执行基本操作,如添加和删除元素( list 和 vector 已经提供了这些功能)。此外,我们很少仅仅在容器中存储对象。我们还会对它们进行排序、打印、提取子集、移除元素、搜索对象等操作。因此,标准库除了提供最常见的容器类型外,还为容器提供了最常用的算法。例如,我们可以简单而高效地对一个 Entry 向量进行排序,并将每个唯一的向量元素复制到一个 列表 中:
void f(vector<Entry>& vec, list<Entry>& lst)
{
sort(vec.begin(), vec.end());// 使用 < 进行排序
unique_copy(vec.begin(), vec.end(), lst.begin());// 不复制相邻的相等元素
}为了使上述代码工作, Entrys 必须定义 < 和 == 。例如:
bool operator<(const Entry& x, const Entry& y)
{
return x.name < y.name;// 按照Entries的名字进行排序
}标准算法是针对元素序列来表达的。一个 序列 由一对迭代器表示,这两个迭代器分别指定序列的第一个元素和超出最后一个元素的位置。
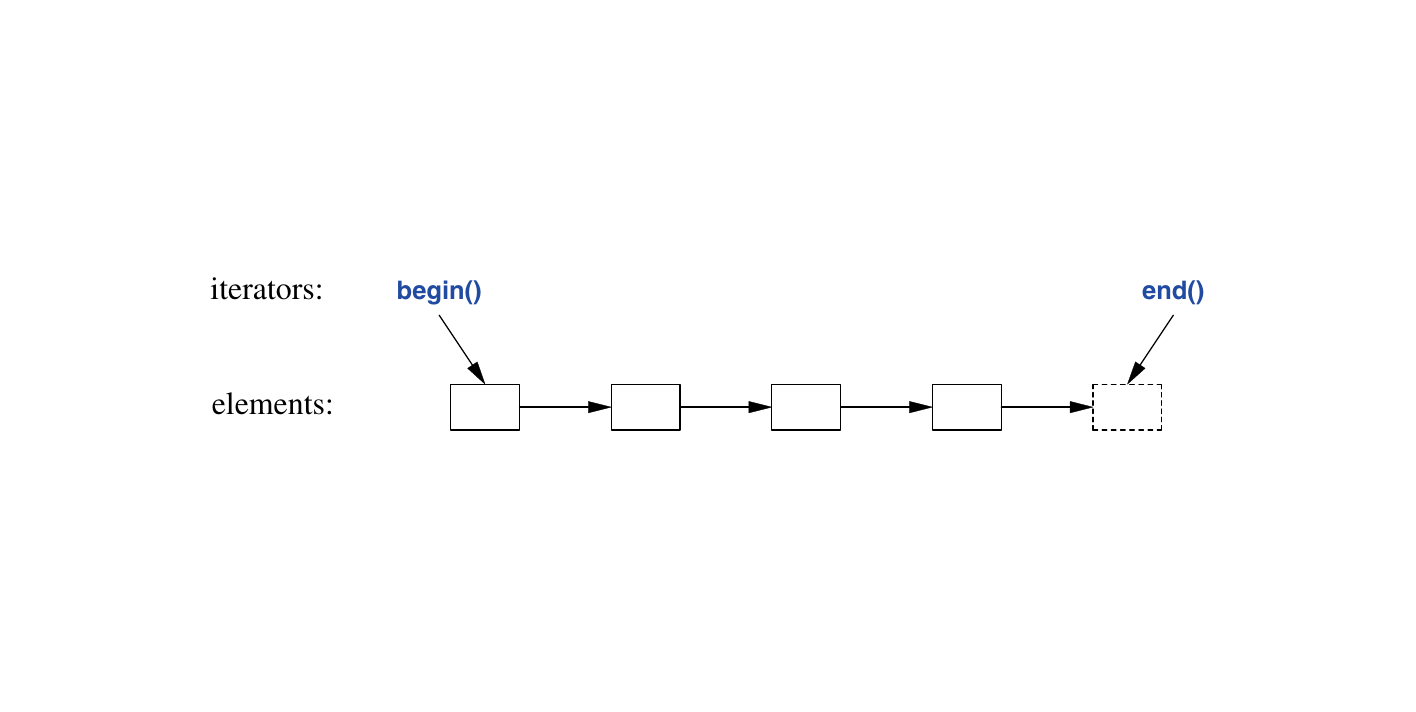
在这个例子中, sort() 函数对由迭代器对 vec.begin() 和 vec.end() 定义的序列进行排序,这个序列恰好是一个向量的所有元素。在写入(输出)时,我们只需要指定要写入的第一个元素。如果写入多于一个元素,那么初始元素之后的元素将被覆盖。因此,为了避免错误, lst 必须至少拥有与 vec 中不重复值数量相等的元素。
遗憾的是,标准库没有提供抽象来支持对容器写入进行的范围检查。然而,我们可以定义一个:
template<typename C>
class Checked_iter {
public:
using value_type = typename C::value_type;
using difference_type = int;
Checked_iter() { throw Missing_container{}; } // 概念forward_iterator要求默认构造函数
Checked_iter(C& cc) : pc{ &cc } {}
Checked_iter(C& cc, typename C::iterator pp) : pc{ &cc }, p{ pp } {}
Checked_iter& operator++() { check_end(); ++p; return *this; }
Checked_iter operator++(int) { check_end(); auto t{ *this }; ++p; return t; }
value_type& operator*() const { check_end(); return *p; }
bool operator==(const Checked_iter& a) const { return p==a.p; }
bool operator!=(const Checked_iter& a) const { return p!=a.p; }
private:
void check_end() const { if (p == pc->end()) throw Overflow{}; }
C* pc {}; // 默认初始化为nullptr
typename C::iterator p = pc->begin();
};显然,这并不是标准库级别的质量,但它展示了这个想法:
vector<int> v1 {1, 2, 3};// 三个元素
vector<int> v2(2);//两个元素
copy(v1,v2.begin());// 溢出
copy(v1,Checked_iter{v2});// 抛错如果我们要将唯一元素放置在一个新 列表 中,可以这样编写:
list<Entry> f(vector<Entry>& vec)
{
list<Entry> res;
sort(vec.begin(), vec.end());
unique_copy(vec.begin(), vec.end(), back_inserter(res));// 在res的末尾追加元素
return res;
}调用 back_inserter(res) 为 res 构造了一个迭代器,该迭代器在容器的末尾添加元素,并扩展容器以容纳它们。这免去了我们先分配固定数量的空间然后再填充的需要。因此,标准容器加上 back_inserter() 消除了使用易出错的、显式的C风格内存管理(使用 realloc() )的需要。标准库中的 list 具有移动构造函数(§6.2.2),使得通过值返回 res 变得高效(即使对于包含数千个元素的 list 也是如此)。
当我们发现像 sort(vec.begin(), vec.end()) 这种基于迭代器对的代码冗长时,可以使用算法的范围版本并编写 sort(vec) (§13.5)。这两种形式是等价的。类似地,范围 for 循环大致等同于直接使用迭代器的C风格循环:
for (auto& x : v) cout << x;// 输出v中的所有元素
for (auto p = v.begin(); p != v.end(); ++p) cout << *p;// 输出v中的所有元素除了更简洁且出错几率更低之外,范围 for 循环的版本往往也更高效。
13.2 迭代器的使用
对于一个容器,可以获取一些指向有用元素的迭代器; begin() 和 end() 就是最好的例子。此外,许多算法也会返回迭代器。例如,标准算法 find 会在一个序列中查找一个值,并返回指向找到的元素的迭代器:
bool has_c(const string& s, char c)// 字符串s是否包含字符c?
{
auto p = find(s.begin(), s.end(), c);
if (p != s.end())
return true;
else
return false;
}与许多标准库的搜索算法一样, find 在未找到时会返回 end() 来表示“未找到”。 has_c() 的一个等效但更简短的定义是:
bool has_c(const string& s, char c)// 字符串s是否包含字符c?
{
return find(s, c) != s.end();
}一个更有趣的练习是找到字符串中所有特定字符出现的位置,并将这些位置作为 vector<char>* 返回。返回 vector 是高效的,因为 vector 提供了移动语义(§6.2.1)。假设我们希望修改找到的位置,我们将传递一个非 const 的字符串:
vector<string::iterator> find_all(string& s, char c)// 在字符串s中查找所有字符c的出现位置
{
vector<string::iterator> res;
for (auto p = s.begin(); p != s.end(); ++p)
if (*p == c)
res.push_back(&*p);
return res;
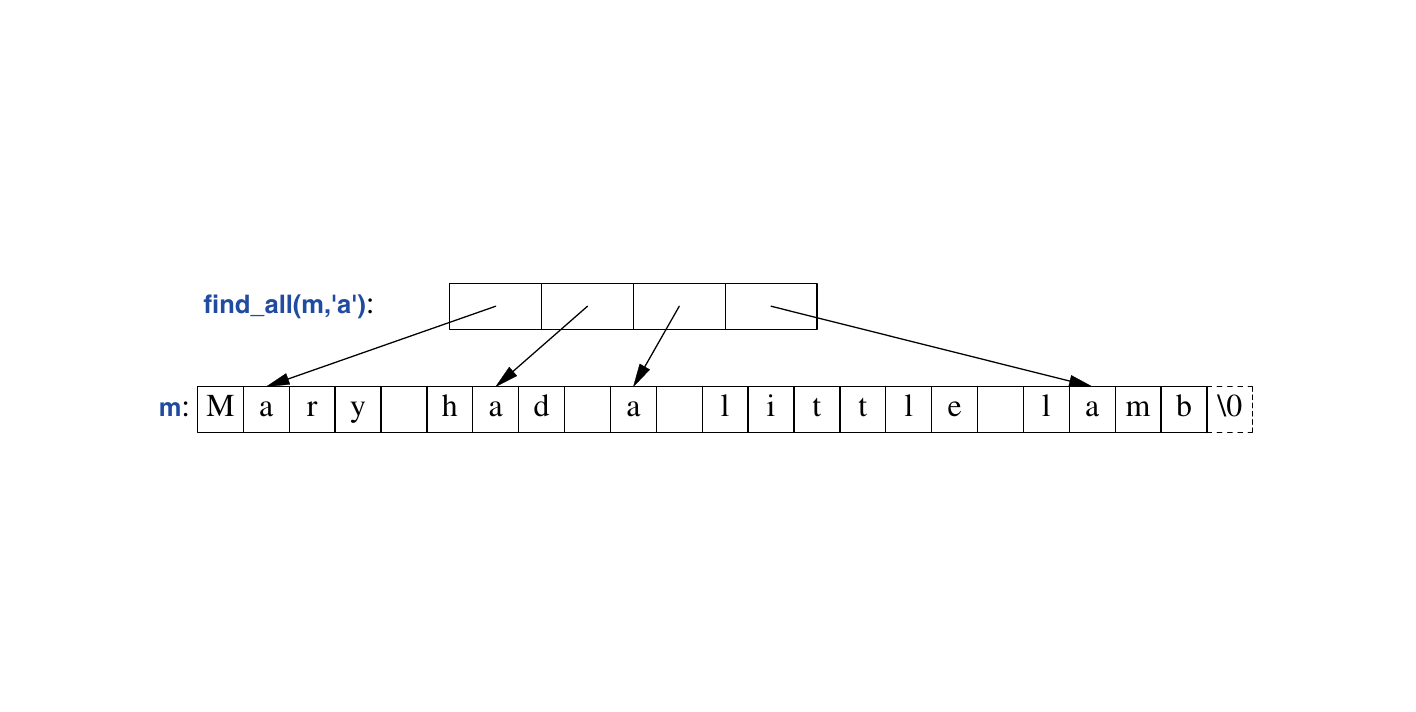
}我们使用传统的循环遍历字符串,利用 ++ 一次向前移动迭代器 p 一个元素,并使用解引用运算符 ***** 查看元素。我们可以这样测试 find_all() :
void test()
{
string m {"Mary had a little lamb"};
for (auto p : find_all(m, 'a'))
if (*p != 'a')
cerr << "a bug!\n";
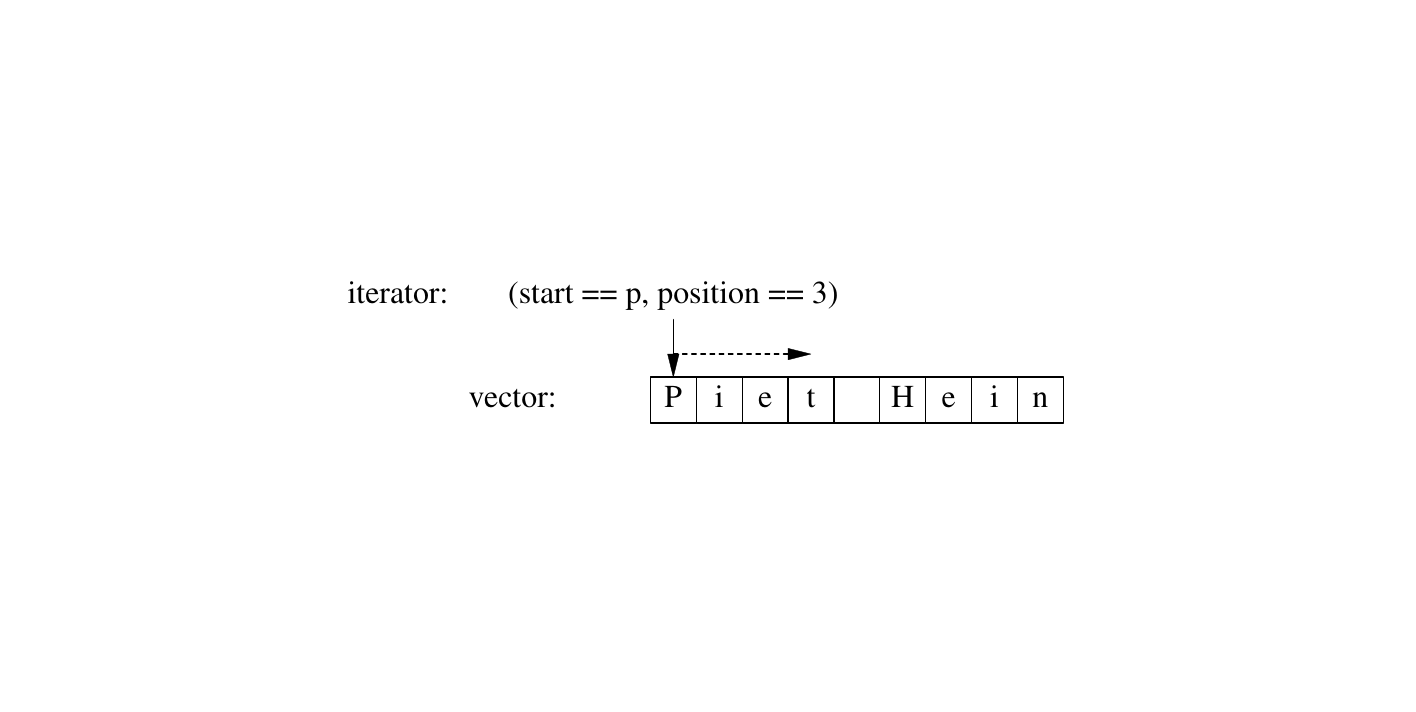
}对 find_all() 的这次调用可以用图形表示如下:
迭代器和标准算法在所有适用的标准容器上都能等效工作。因此,我们可以泛化 find_all() 函数:
template<typename C, typename V>
vector<typename C::iterator> find_all(C& c, V v) // 在c中查找所有v的出现
{
vector<typename C::iterator> res;
for (auto p = c.begin(); p != c.end(); ++p)
if (*p == v)
res.push_back(p);
return res;
}这里使用 typename 关键字是为了告诉编译器, C 的迭代器应该被视为一个类型,而不是某个类型的值,比如说整数 7 。
或者,我们也可以返回元素的普通指针组成的 vector :
template<typename C, typename V>
auto find_all(C& c, V v) -> decltype(vector<decay_t<V>*>{})// 在c中查找所有v的出现
{
vector<decay_t<V>*> res;
for (auto& x : c)
if (x == v)
res.push_back(&x);
return res;
}当我处理这个问题时,我还通过使用范围 for 循环和标准库中的 range_value_t (§16.4.4)来命名元素的类型,从而简化了代码。 range_value_t 的一个简化版本可以这样定义:
template<typename T>
using range_value_type_t = typename T::value_type;使用 find_all() 的任意一个版本,我们可以编写如下测试代码:
void test()
{
string m {"Mary had a little lamb"};
for (auto p : find_all(m, 'a'))// p 是 string::iterator
if (*p != 'a')
cerr << "string bug!\n";
list<int> ld {1, 2, 3, 1, -11, 2};
for (auto p : find_all(ld, 1))// p 是 list<int>::iterator
if (*p != 1)
cerr << "list bug!\n";
vector<string> vs {"red", "blue", "green", "green", "orange", "green"};
for (auto p : find_all(vs, "red")) // p 是 vector<string>::iterator
if (*p != "red")
cerr << "vector bug!\n";
for (auto p : find_all(vs, "green"))
*p = "vert";
}迭代器用于分离算法和容器。算法通过迭代器操作数据,而不了解容器中元素存储的细节。相反,容器也不了解在其元素上操作的算法;它所做的只是在请求时提供迭代器(例如, begin() 和 end() )。这种数据存储和算法之间的分离模型提供了非常通用和灵活的软件设计方式。
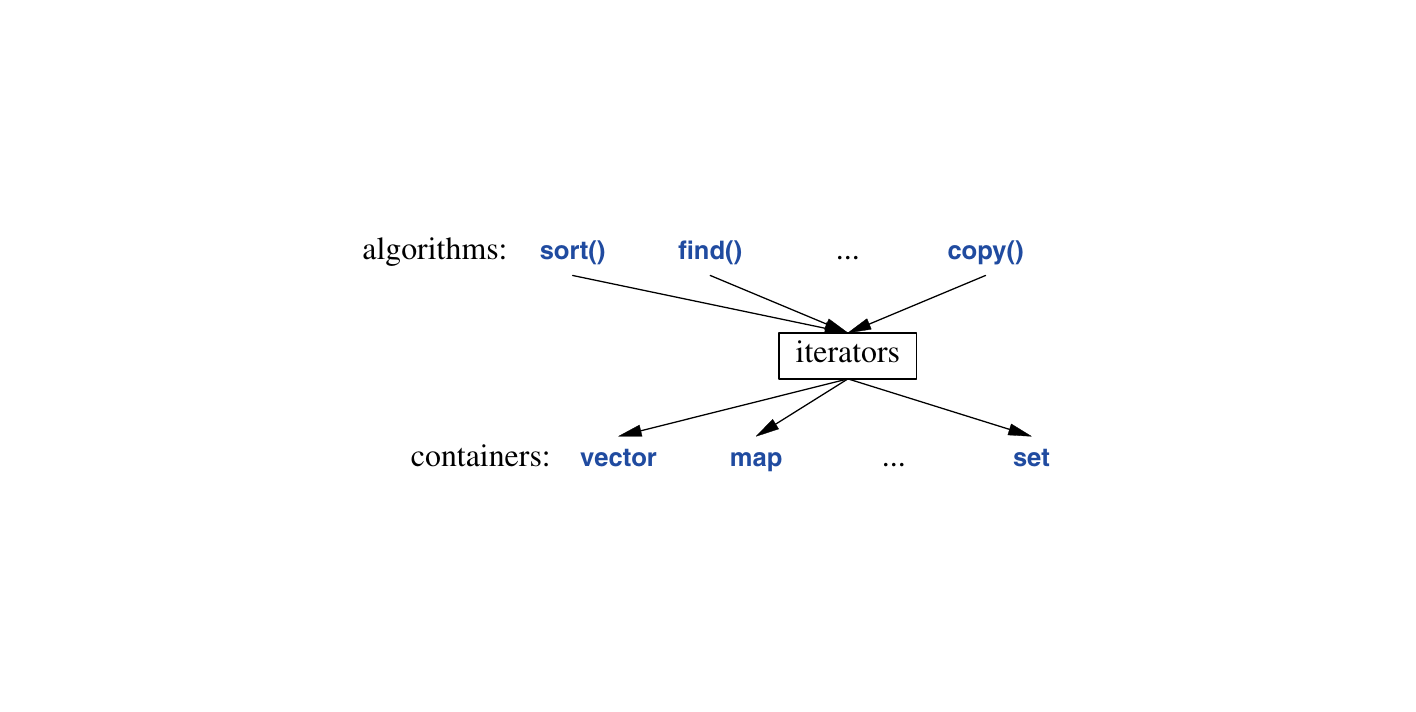
13.3 迭代器类型
迭代器本质上到底是什么?任何一个特定的迭代器都是某个类型的对象。然而,存在许多不同的迭代器类型——因为迭代器需要保存对于特定容器类型执行其任务所需的信息。这些迭代器类型可能因其关联的容器及它们所满足的特殊需求而大相径庭。例如,一个 vector 的迭代器可以就是一个普通的指针,因为指针是引用向量元素相当合理的方式:
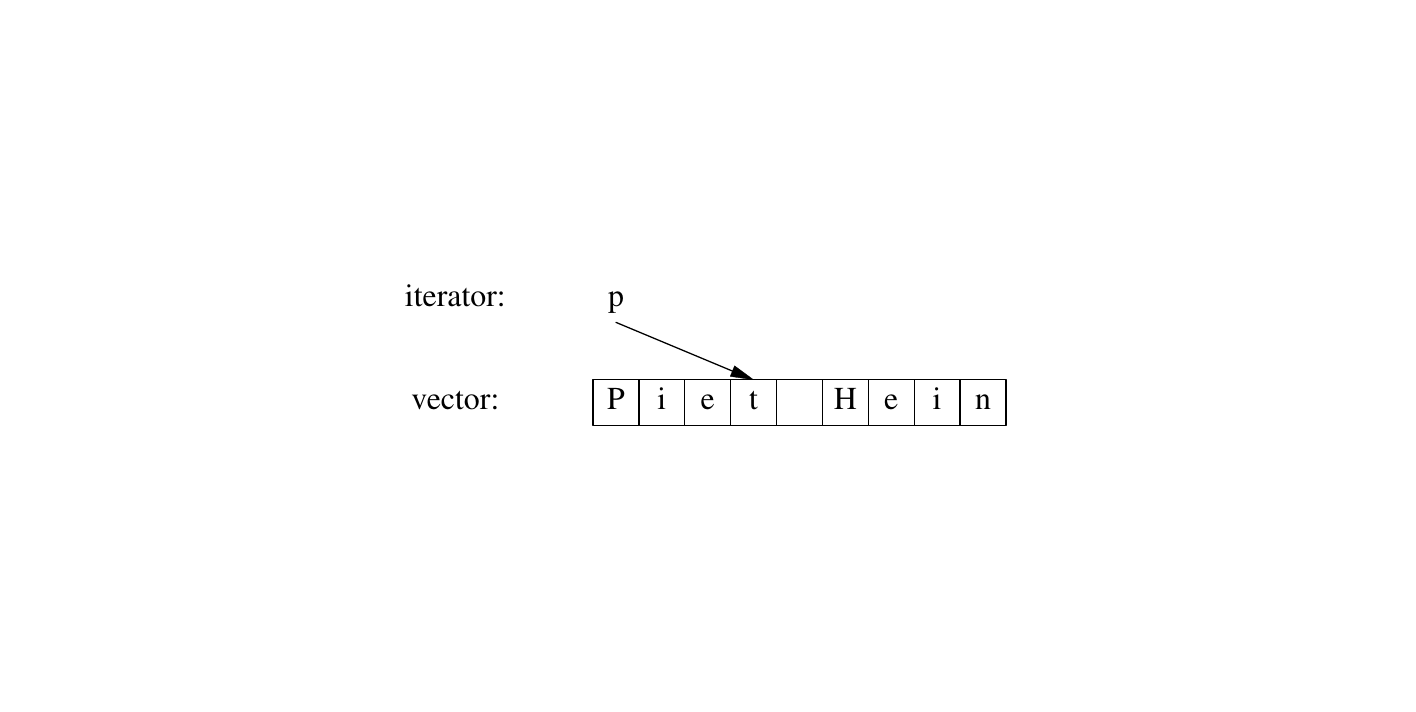
或者, vector 迭代器可以实现为指向 vector 的指针加上一个索引:
使用这样的迭代器可以进行范围检查。 list 迭代器比指向元素的简单指针复杂,因为 list 中的一个元素通常不知道该列表下一个元素的位置。因此, list 迭代器可能是一个指向 链节 (link)的指针:
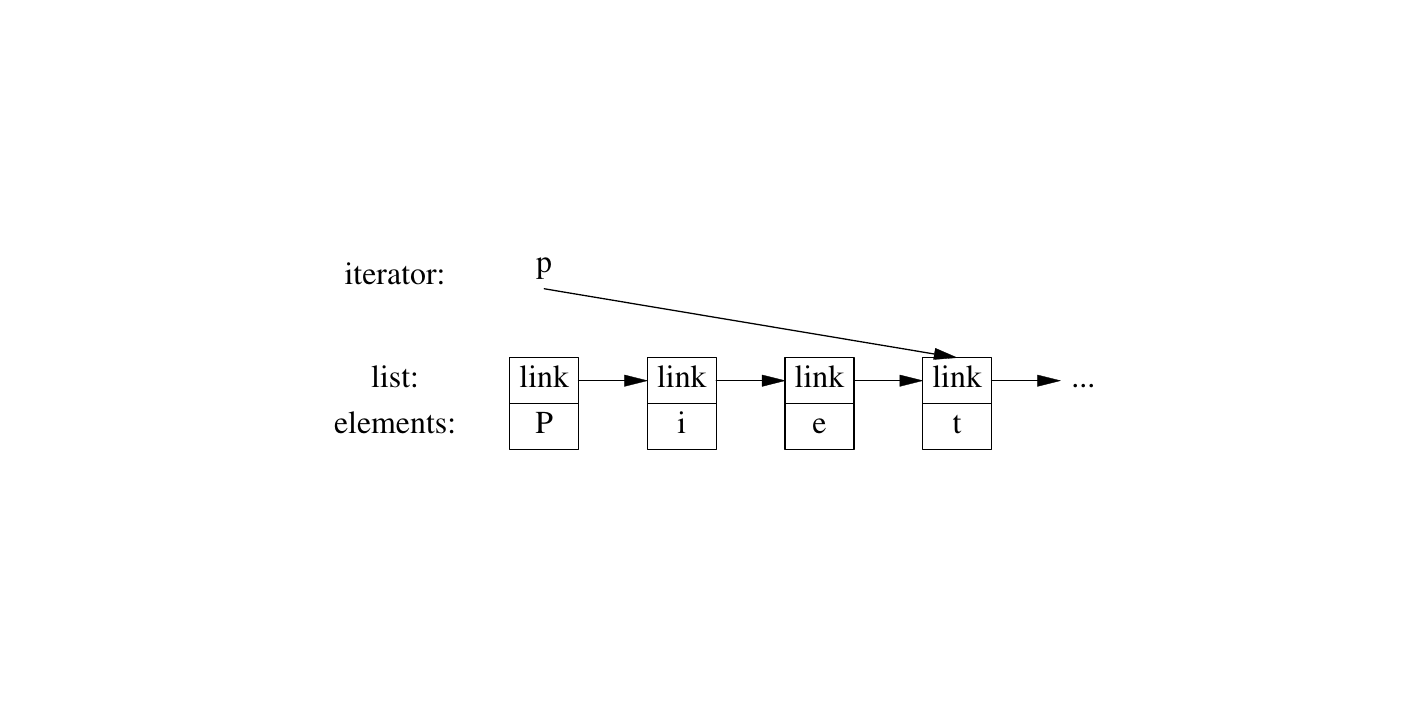
所有迭代器共通的是它们的语义和操作命名。例如,对任何迭代器应用 ++ 都将得到一个指向下一元素的迭代器。类似地, * 运算将返回迭代器所指的元素。实际上,任何遵循这类简单规则的对象都是一个迭代器。 迭代器 是一个通用的概念,一个 concept (§8.2),并且不同类型的迭代器作为标准库概念提供,比如 forward_iterator 和 random_access_iterator (§14.5)。此外,用户很少需要知道特定迭代器的具体类型;每个容器都“知道”其迭代器类型,并按照惯例名称 iterator 和 const_iterator 提供它们。例如, list<Entry>::iterator 是 list<Entry> 的一般迭代器类型。我们很少需要担心该类型是如何定义的细节。
在某些情况下,迭代器并不是一个成员类型,因此标准库提供了 iterator_t<X> ,它可以在定义了 X 迭代器的地方工作。
13.3.1 流迭代器
迭代器是一种通用且有用的概念,用于处理容器中的元素序列。 然而,序列元素不仅仅出现在容器中。例如,输入流会产生一系列值,而我们将一系列值写入输出流。 因此,迭代器的概念可以有效地应用于输入和输出。 要创建一个 ostream_iterator ,我们需要指定将使用哪个流以及写入该流的对象类型。例如:
ostream_iterator<string> oo {cout};// 将字符串写入cout对* oo 赋值的效果是将赋值的值写入 cout 。例如:
int main()
{
*oo = "Hello, ";// 意味着 cout << "Hello, "
++oo;
*oo = "world!\n";// 意味着 cout << "world!\n"
}这是向标准输出写入典型消息的另一种方式。执行 ++oo 是为了模仿通过指针向数组中写入的方式。这样,我们就可以在流上使用算法。例如:
vector<string> v{ "Hello", ", ", "World!\n" };
copy(v.begin(), v.end(), oo);类似地, istream_iterator 允许我们将输入流视为只读容器来处理。同样,我们必须指定要使用的流和期望的值类型:
istream_iterator<string> ii {cin};使用成对的输入迭代器来表示序列,因此我们必须提供一个 istream_iterator 来指示输入结束。这是默认的 istream_iterator :
istream_iterator<string> eos {};通常, istream_iterator 和 ostream_iterator 不直接使用。相反,它们作为参数提供给算法。例如,我们可以编写一个简单的程序来读取文件,对读取的单词进行排序,消除重复项,并将结果写入另一个文件:
int main()
{
string from, to;
cin >> from >> to;// 获取源文件名和目标文件名
ifstream is {from}; // 用于文件"from"的输入流
istream_iterator<string> ii {is}; // 流的输入迭代器
istream_iterator<string> eos {};// 输入终止符
ofstream os {to}; // 用于文件"to"的输出流
ostream_iterator<string> oo {os, "\n"}; // 输出迭代器加上分隔符
vector<string> b {ii, eos}; // b 是从输入初始化的向量
sort(b.begin(), b.end());// 对缓冲区进行排序
unique_copy(b.begin(), b.end(), oo);// 将缓冲区复制到输出,丢弃重复值
return !is.eof() || !os;// 返回错误状态(§1.2.1, §11.4)
}我使用了 sort() 和 unique_copy() 的范围版本。我本可以直接使用迭代器,例如, sort(b.begin(), b.end()) ,这在较旧的代码中很常见。
请注意,要同时使用标准库算法的传统迭代器版本及其范围版本,我们需要明确指定范围版本的调用或使用 using-declaration (§9.3.2):
copy(v.begin(), v.end(), oo);// 可能存在歧义
ranges::copy(v, oo);// 正确
using ranges::copy;// 从这里开始,copy(v, oo)正确
copy(v, oo);// 正确ifstream 是可以连接到文件的 istream (§11.7.2),而 ofstream 是可以连接到文件的 ostream 。 ostream_iterator 的第二个参数用于界定输出值。
实际上,这个程序比实际需要的更长。我们首先将字符串读入向量,然后对其进行排序,最后写出并消除重复项。一个更优雅的解决方案是根本不存储重复项。这可以通过将字符串保留在集合中来实现,集合不保留重复项并保持其元素的有序性(§12.5)。这样,我们可以将使用向量的两行代码替换为使用集合的一行代码,并将 unique_copy() 替换为更简单的 copy() :
set<string> b {ii, eos};// 从输入收集字符串
copy(b.begin(), b.end(), oo);// 将缓冲区复制到输出我们只使用了一次 ii 、 eos 和 oo ,因此我们可以进一步减小程序的大小:
int main()
{
string from, to;
cin >> from >> to;// 获取源文件名和目标文件名
ifstream is {from};// 用于文件"from"的输入流
ofstream os {to};// 用于文件"to"的输出流
set<string> b {istream_iterator<string>{is}, istream_iterator<string>{}}; // 读取输入
copy(b.begin(), b.end(), ostream_iterator<string>{os, "\n"}); // 复制到输出
return !is.eof() || !os;// 返回错误状态(§1.2.1, §11.4)
}是否最后一个简化改进了可读性,这取决于个人品味和经验。
13.4 使用谓词
在迄今为止的例子中,算法简单地“内置”了对序列中每个元素所执行的操作。然而,我们经常希望将该操作作为算法的参数。例如, find 算法((§13.2, §13.5)提供了一种方便的方式来查找特定值。一个更通用的变体则是寻找满足指定条件的元素,即 谓词 (predicate)。例如,我们可能想在一个 map 中搜索第一个大于 42 的值。 map 允许我们将其元素作为 (key, value) 对的序列来访问,因此我们可以在 map<string,int> 的序列中搜索一个 int 大于 42 的 pair<const string,int> :
void f(map<string,int>& m)
{
auto p = find_if(m, Greater_than{42});
// ...
}在这里, Greater_than 是一个函数对象(§7.3.2),它保存了一个值( 42 ),用于与类型为 pair<string,int> 的 map 条目进行比较:
struct Greater_than {
int val;
Greater_than(int v) : val{v} { }
bool operator()(const pair<string,int>& r) const { return r.second > val; }
};或者,我们可以等效地使用 lambda 表达式(§7.3.2):
auto p = find_if(m, [](const auto& r) { return r.second > 42; });谓词不应该修改它所应用的元素。
13.5 算法概述
算法的一般定义是“一组有限的规则,为解决一组特定问题给出了一系列操作步骤,具有五个重要特征:有限性...明确性...输入...输出...有效性”[Knuth, 1968, §1.1]。在C++标准库的背景下,算法是指作用于元素序列的函数模板。
标准库提供了许多算法。这些算法定义在 std 命名空间中,并在 <algorithm> 和 <numeric> 头文件中呈现。这些标准库算法都将序列作为输入。从 b 到 e 的半开序列称为[ b : e )。以下是一些示例:
| f=for_each(b,e,f) | 对于序列[b:e)中的每个元素x,执行f(x) |
| p=find(b,e,x) | p是序列[b:e)中第一个满足∗p==x的p |
| p=find_if(b,e,f) | p是序列[b:e)中第一个满足f(∗p)的p |
| n=count(b,e,x) | n是序列[b:e)中满足∗q==x的元素数量 |
| n=count_if(b,e,f) | n是序列[b:e)中满足f(∗q)的元素数量 |
| replace(b,e,v,v2) | 将序列[b:e)中满足∗q==v的元素替换为v2 |
| replace_if(b,e,f,v2) | 将序列[b:e)中满足f(∗q)的元素替换为v2 |
| p=copy(b,e,out) | 将序列[b:e)复制到[out:p) |
| p=copy_if(b,e,out,f) | 将序列[b:e)中满足f(∗q)的元素复制到[out:p) |
| p=move(b,e,out) | 将序列[b:e)移动到[out:p) |
| p=unique_copy(b,e,out) | 将序列[b:e)复制到[out:p),不复制相邻的重复项 |
| sort(b,e) | 对序列[b:e)中的元素进行排序,使用<作为排序标准 |
| sort(b,e,f) | 对序列[b:e)中的元素进行排序,使用f作为排序标准 |
| (p1,p2)=equal_range(b,e,v) | [p1:p2)是已排序序列[b:e)中值为v的子序列;基本是一个对v的二分查找 |
| p=merge(b,e,b2,e2,out) | 将两个已排序序列[b:e)和[b2:e2)合并到[out:p) |
| p=merge(b,e,b2,e2,out,f) | 使用f作为比较标准,将两个已排序序列[b:e)和[b2:e2)合并到[out:p) |
对于接受[b:e)范围的每种算法, <ranges> 都提供了一个接受范围的版本。请记住(§9.3.2),要同时使用标准库算法的传统迭代器版本及其范围对应版本,您需要明确指定调用或者使用 using 声明。
这些算法,以及更多其他算法(§17.3),可以应用于容器、字符串和内置数组的元素上。
一些算法,如 replace() 和 sort() ,会修改元素值,但没有算法会添加或删除容器中的元素。原因是序列并不标识持有序列元素的容器。若要添加或删除元素,您需要知道这些容器的信息(例如, back_inserter ; §13.1)或直接指向容器本身的东西(例如, push_back() 或 erase() ; §12.2)。
Lambda 表达式作为传递的运算非常常见。例如:
vector<int> v = {0,1,2,3,4,5};
for_each(v.begin(), v.end(), [](int& x){ x=x*x; });//v=={0,1,4,9,16,25}
for_each(v.begin(), v.begin()+3, [](int& x){ x=sqrt(x); });// v=={0,1,2,9,16,25}标准库算法往往比一般手工编写的循环在设计、规范和实现上更为精细。了解它们,并优先于使用原始语言编写的代码。
13.6 并行算法
当同一任务需应用于大量数据项时,只要对不同数据项的计算是独立的,我们就可以并行地在每个数据项上执行该任务:
• 并行执行:任务在多个线程上执行(通常运行在多个处理器核心上)
• 向量化执行:使用向量化(也称为 SIMD,即“单指令、多数据”)在单个线程上执行任务。
标准库同时支持这两种方式,并且我们可以明确指定需要顺序执行;在 execution 命名空间的 <execution> 中,我们找到:
• seq :顺序执行
• par :并行执行(如果可行)
• unseq :无序(向量化)执行(如果可行)
• par_unseq :并行和/或无序(向量化)执行(如果可行)。
考虑 sort() 函数:
sort(v.begin(),v.end()); // 顺序执行
sort(seq,v.begin(),v.end()); // 顺序执行(与默认相同)
sort(par,v.begin(),v.end()); // 并行执行
sort(par_unseq,v.begin(),v.end()); // 并行和/或向量化的执行是否值得进行并行化和/或向量化取决于算法、序列中的元素数量、硬件以及在其上运行的程序对硬件的利用情况。因此,执行策略指示符只是提示。编译器和/或运行时调度器将决定使用多少并发性。这一切都非常复杂,没有测量就不谈论效率的原则在这里尤为重要。
不幸的是,并行算法的范围版本尚未进入标准,但如果我们需要它们,很容易定义:
void sort(auto pol, random_access_range auto& r)
{
sort(pol,r.begin(),r.end());
}大多数标准库算法,包括 §13.5 表中的所有算法( equal_range 除外),都可以像 sort() 一样使用 par 和 par_unseq 请求并行化和向量化。为什么不是 equal_range() ?因为到目前为止,还没有人提出一个有价值的并行算法来实现它。
许多并行算法主要应用于数值数据;参见 §17.3.1。
当请求并行执行时,确保避免数据竞争(§18.2)和死锁(§18.3)。
13.7 建议
- STL算法对一个或多个序列进行操作;§13.1。
- 输入序列是半开放的,由一对迭代器定义;§13.1。
- 您可以根据特殊需求自定义迭代器;§13.1。
- 许多算法可应用于I/O流;§13.3.1。
- 在搜索时,算法通常返回输入序列的末尾以指示“未找到”;§13.2。
- 算法不会直接在其参数序列中添加或删除元素;§13.2,§13.5。
- 编写循环时,请考虑是否可以将其表达为通用算法;§13.2。
- 使用 using 类型别名来清理混乱的符号;§13.2。
- 使用谓词和其他函数对象为标准算法提供更广泛的意义;§13.4,§13.5。
- 谓词不得修改其参数;§13.4。
- 了解标准库中的算法,并优先于手工编写的循环使用它们;§13.5。