第5章 类
第5章 类
简介
- 类
具体类型
- 一种算术类型
- 容器
- 初始化容器
抽象类型
虚函数
类层次结构
- 层次结构的优势
- 层次导航
- 避免资源泄露
建议
5.1 简介
本章及接下来的三章旨在让您大致了解C++对抽象和资源管理的支持能力,不过多涉及详细内容:
• 本章非正式地介绍了定义和使用新类型( 用户定义类型 )的方法。特别是,它介绍了 具体类 、 抽象类 和 类层次结构 所使用的基本属性、实现技术以及语言设施。
• 第6章介绍了C++中具有定义意义的操作,如构造函数、析构函数和赋值操作。它概述了组合使用这些操作以控制对象生命周期和支持简单、高效、完整资源管理的规则。
• 第7章通过模板作为参数化类型和算法的机制引入,这些参数可以是其他类型和算法。对于用户自定义类型和内置类型的操作表示为函数,有时泛化为 函数模板 和 函数对象 。
• 第8章概述了支持泛型编程的概念、技术和语言特性。重点在于 Concepts 的定义与使用,以便精确地指定模板接口并指导设计。为了指定最一般和最灵活的接口,引入了 可变参数模板(Variadic templates) 。
这些是支持被称为 面向对象编程 和 泛型编程 的编程风格的语言设施。第9至18章随后通过展示标准库设施及其使用的示例进行深入。
5.1.1 类
C++的核心语言特性是 类 。类是一种用户定义类型,用于在程序代码中表示一个实体。每当我们的程序设计有一个有用的思想、实体、数据集合等,我们都尝试将其表示为程序中的一个类,这样这个思想就体现在代码中,而不仅仅在我们的头脑中、设计文档中或某些注释里。由精心挑选的一组类构建的程序比直接基于内置类型构建的一切要容易理解得多,也更容易正确实现。特别是,类往往是库所提供的内容。
本质上,所有除了基本类型、运算符和语句的语言功能都旨在帮助更有效地定义类或更方便地使用它们。当我说“更好”时,我的意思是更正确、更容易维护、更高效、更优雅、更容易使用、更容易阅读和更容易推理。大多数编程技术都依赖于特定种类的类的设计与实现。程序员的需求和喜好差异极大。因此,对类的支持是广泛的。在这里,我们考虑三种重要种类的类的基本支持:
• 具体类(§5.2)
• 抽象类(§5.3)
• 类层次结构中的类(§5.5)
令人惊讶的是,许多有用的类属于这三种类型之一。甚至更多的类可以看作是这些类的简单变体,或者使用为这些类所采用的技术组合来实现。
5.2 具体类型
具体类型 的基本思想是它们的行为“就像内置类型一样”。例如,复数类型和无限精度整数在很大程度上类似于内置的 int ,当然它们有自己的语义和操作集。同样, vector 和 string 很像内置数组,只是它们更加灵活,行为更佳(§10.2, §11.3, §12.2)。
具体类型的根本特征是其表示形式是其定义的一部分。在许多重要情况下,比如 vector ,该表示可能只是一到多个指向其他地方存储的数据的指针,但这种表示形式存在于具体类的每个对象中。这使得实现能够在时间和空间上达到最优效率。特别是,它允许我们
• 将具体类型的对象放置在栈上、静态分配的内存中以及其他对象内部(§1.5)。
• 直接引用对象(而不仅仅是通过指针或引用)。
• 立即且完全地初始化对象(例如,使用构造函数;§2.3)。
• 复制和移动对象(§6.2)。
表示形式可以是私有的,只能通过成员函数访问(正如 Vector 所做的那样;§2.3),但它确实存在。因此,如果表示形式在任何重要方面发生变化,用户必须重新编译。这是为了让具体类型表现得完全像内置类型所必须付出的代价。对于不经常改变的类型,以及局部变量提供了急需的清晰度和效率的情况,这是可以接受的,而且往往是理想的。为了增加灵活性,具体类型可以将其表示的主要部分保留在自由存储区(动态内存、堆)上,并通过类对象本身存储的部分来访问它们。这就是 Vector 和 string 的实现方式;它们可以被视为具有精心设计接口的资源句柄。
5.2.1 一种算术类型
经典的用户定义算术类型是 complex :
class complex {
double re, im; // 表示形式:两个double
public:
complex(double r, double i) : re{r}, im{i} {} // 从两个标量构造复数
complex(double r) : re{r}, im{0} {} // 从一个标量构造复数
complex() : re{0}, im{0} {} // 默认构造复数:{0,0}
complex(complex z) : re{z.re}, im{z.im} {} // 复制构造函数
double real() const { return re; } // 返回实部
void real(double d) { re=d; } // 设置实部
double imag() const { return im; } // 返回虚部
void imag(double d) { im=d; } // 设置虚部
complex& operator+=(complex z) {
re+=z.re; // 实部相加
im+=z.im; // 虚部相加
return *this; // 返回结果
}
complex& operator-=(complex z) {
re-=z.re;
im-=z.im;
return *this;
}
};
complex& operator*=(complex&, complex&);// 在类外某处定义
complex& operator/=(complex&, complex&);// 在类外某处定义这是标准库 complex 的一个简化版本(§17.4)。类定义本身仅包含需要访问表示形式的操作。表示形式简单且传统。出于实际原因,它必须与Fortran 60年前提供的内容兼容,我们需要一套常规的运算符。除了逻辑需求, complex 必须高效,否则将无人使用。这意味着简单操作必须内联。也就是说,简单的操作(如 构造函数 、 += 和 imag() )必须在生成的机器代码中不通过函数调用来实现。在类中定义的函数默认是内联的。也可以通过在函数声明前加上关键字 inline 显式请求内联。一个工业级的 complex (如标准库中的那个)会小心地实现适当的内联。此外,标准库中的 complex 将此处所示的函数声明为 constexpr ,以便我们可以在编译时进行复数运算。
复制赋值和复制初始化会隐式定义(§6.2)。
可以不带参数调用的构造函数称为 默认构造函数 。因此, complex() 是 complex 的默认构造函数。通过定义默认构造函数,可以消除该类型未初始化变量的可能性。
函数 real() 和 imag() 上的 const 说明符表明这些函数不会修改调用它们的对象。 const 成员函数可以给 const 和 非const 对象调用,而 非const 成员函数只能给 非const 对象调用。例如:
complex z = {1,0};
const complex cz {1,3};
z = cz; // OK: 赋值给非const变量
cz = z; // 错误:给const赋值
double x = z.real(); // OK: complex::real() 是const许多有用的操作不需要直接访问 complex 的表示形式,因此可以从类定义中单独定义:
complex operator+(complex a, complex b) { return a+=b; }
complex operator-(complex a, complex b) { return a-=b; }
complex operator-(complex a) { return {-a.real(), -a.imag()}; }// 单目负号运算符
complex operator*(complex a, complex b) { return a*=b; }
complex operator/(complex a, complex b) { return a/=b; }这里,我利用了按值传递的参数会被复制的事实,这样我就可以在不影响调用者副本的情况下修改参数,并使用结果作为返回值。
== 和 != 的定义很直观:
bool operator==(complex a, complex b) { return a.real()==b.real() && a.imag()==b.imag(); }// 相等
bool operator!=(complex a, complex b) { return !(a==b); }// 不等complex 类可以这样使用:
void f(complex z) {
complex a {2.3}; // 从2.3构造{2.3,0.0}
complex b {1/a};
complex c {a+z*complex{1,2.3}};
if (c != b)
c = -(b/a)+2*b;
}编译器会将涉及 complex 的运算符转换为适当的功能调用。例如, c!=b 意味着 operator!=(c,b) ,而 1/a 意味着 operator/(complex{1},a) 。
用户定义运算符(“重载运算符”)应谨慎且按照惯例使用(§6.4)。运算符的语法由语言固定,所以不能定义一元" / "。另外,无法改变内置类型运算符的含义,所以不能重新定义 + 使其对整数执行减法。
5.2.2 容器
容器是一种持有元素集合的对象。我们将类 Vector 称为容器,因为 Vector 类型的对象就是容器。如§ 2.3所定义, Vector 作为一个 double 类型的容器并非不合理:它易于理解,建立了一个有用的不变性(§4.3),提供了范围检查的访问(§4.2),并提供了 size() 方法来允许我们遍历其元素。然而,它确实存在一个致命缺陷:它使用 new 分配元素,但从不释放它们。这不是一个好主意,因为C++没有提供垃圾收集器来使未使用的内存可用于新对象。在某些环境中,你可能无法使用收集器,而且通常由于逻辑或性能原因,你更倾向于对销毁有更精确的控制。我们需要一种机制来确保构造函数分配的内存被释放;这种机制就是 析构函数 :
class Vector {
public:
Vector(int s) : elem{new double[s]}, sz{s} {} // 构造函数:获取资源
~Vector() { delete[] elem; } // 析构函数:释放资源
double& operator[](int i);
int size() const;
private:
double* elem; // elem 指向一个大小为 sz 的双精度浮点数数组
int sz;
};析构函数的名称是类名的补运算符 ~ ,后面跟着类名;它是构造函数的补充。
Vector 的构造函数使用 new 运算符在自由存储区(也称为 堆 或 动态内存 )上分配一些内存。析构函数则通过使用 delete[] 运算符释放那部分内存来进行清理。普通的 delete 用于删除单个对象;而 delete[] 用于删除数组。
所有这些操作都不需要 Vector 用户的介入。用户只需像创建和使用内置类型变量一样创建和使用 Vector 。例如:
Vector gv(10); // 全局变量;gv在程序结束时被销毁
Vector* gp = new Vector(100); // 堆上的Vector;不会被隐式销毁
void fct(int n) {
Vector v(n); // ... 使用v ...
{
Vector v2(2*n); // ... 使用v和v2 ...
} // v2在此被销毁
// ... 使用v ...
} // v在此被销毁Vector 遵循与内置类型(如 int 和 char )相同的命名、作用域、分配、生命周期等规则(§1.5)。这个 Vector 为了简化而省略了错误处理;请参阅§4.4。
构造函数/析构函数组合是许多优雅技术的基础。特别是,它是大多数C++通用资源管理技术(§6.3,§15.2.1)的基础。请看 Vector 图示:
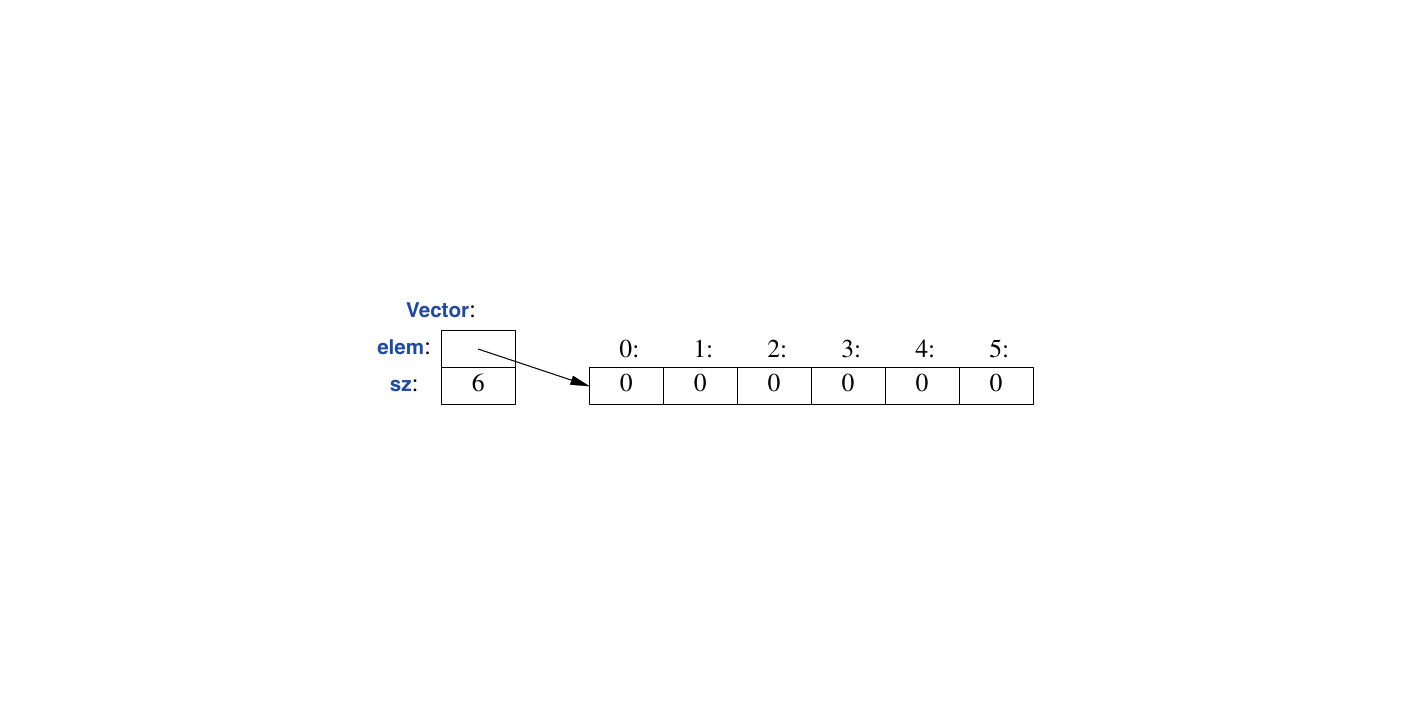
构造函数负责分配元素并适当地初始化 Vector 的成员。析构函数则负责释放这些元素。这种 handle-to-data 模型常用于管理那些在对象生命周期中大小可变的数据。在构造函数中获取资源并在析构函数中释放资源的技巧,被称为 资源获取即初始化 (Resource Acquisition Is Initialization,简称 RAII )。这使我们能够消除“裸 new 操作”,即避免在通用代码中进行分配,而是将它们封装在行为良好的抽象的实现内部。同样,“裸 delete 操作”也应该避免。避免使用“裸 new ”和“裸 delete ”可以使代码出错的可能性大大降低,并且更易于防止资源泄露(§15.2.1)。
5.2.3 初始化容器
容器的存在是为了容纳元素,因此显然我们需要便捷的方式来将元素放入容器中。我们可以创建一个具有适当数量元素的 Vector ,然后稍后分配这些元素,但通常还有其他更优雅的方法。这里,我仅提及两种常用的方式:
- 初始化列表构造函数 :使用元素列表进行初始化。
- push_back() :在序列的末尾(即序列的后面)添加一个新的元素。
这些功能可以这样声明:
class Vector {
public:
Vector(); // 默认初始化为“空”,即没有元素
Vector(std::initializer_list<double>); // 使用双精度浮点数列表初始化
// ...
void push_back(double); // 在末尾添加元素,容器大小增加一
// ...
};push_back() 方法对于输入任意数量的元素非常有用。例如:
Vector read(std::istream& is) {
Vector v;
for (double d; is >> d; ) {//读取浮点值到d,其中is >> d是条件表达式,它尝试从输入流is读取一个double类型的数据到d中。如果读取成功,表达式返回true,继续循环;如果遇到文件结束(EOF)或格式错误,则返回false,循环终止
v.push_back(d);//添加d到v
}
return v;
}这里,我使用了 for 语句而不是更传统的 while 语句来限制 d 的作用域在循环内部。
从 read() 返回大量数据可能会成本高昂。保证返回 Vector 成本低廉的方法是为其提供一个移动构造函数(§6.2.2):
Vector v = read(std::cin);// 此处并复制 Vector 的元素标准库中的 std::vector 如何表示以使 push_back() 及其他改变向量大小的操作高效,在 §12.2 中介绍。
用于定义初始化列表构造函数的 std::initializer_list 是编译器已知的标准库类型:当我们使用 {} 列表,如 {1,2,3,4} ,编译器将创建一个 initializer_list 类型的对象传给程序。因此,我们可以这样写:
Vector v1 = {1, 2, 3, 4, 5}; // v1 有5个元素
Vector v2 = {1.23, 3.45, 6.7, 8}; // v2 有4个元素Vector 的初始化列表构造函数可能这样定义:
Vector::Vector(std::initializer_list<double> lst) // 使用列表初始化
: elem{new double[lst.size()]}, sz{static_cast<int>(lst.size())} {
copy(lst.begin(), lst.end(), elem); // 从 lst 复制到 elem 中(§13.5)
}不幸的是,标准库使用 unsigned int 表示大小和下标,所以我们需要用丑陋的 static_cast 显式地将初始化列表的大小转换为 int 。这是严谨的,因为手写的列表元素数量大于最大整数(对于16位整数是32,767,对于32位整数是2,147,483,647)的概率相当低。然而,类型系统不具备常识。它了解变量可能的值,而不是实际值,因此可能会在没有实际违反时发出警告。这样的警告偶尔能帮助程序员避免严重的错误。
static_cast 不检查它正在转换的值;程序员相信能正确使用它。这并不总是一个好的假设,所以如果有疑问,应该检查值。显式类型转换(通常称为 类型转换 ,以提醒你它们用于支撑一些已损坏的东西)最好避免。尽量只在系统的最低级别使用未经检查的类型转换。它们很容易出错。
其他类型转换包括 reinterpret_cast 和 bit_cast (§16.7),用于将对象视为字节序列处理,以及 const_cast 用于“去除 const 属性”。明智地使用类型系统和精心设计的库,使我们能在更高层次的软件中消除未经检查的类型转换。
5.3 抽象类型
诸如 complex 和 Vector 这样的类型被称为 具体类型 ,因为它们的表示形式是其定义的一部分。在这方面,它们类似于内置类型。相比之下, 抽象类型 是一种完全隔离用户与实现细节的类型。为了做到这一点,我们从表示形式中解耦接口,并放弃真正的局部变量。因为我们对抽象类型的表示形式(甚至它的大小)一无所知,我们必须在自由存储区(§5.2.2)上分配对象,并通过引用或指针(§1.7, §15.2.1)来访问它们。
首先,我们定义一个名为 Container 的类的接口,我们将把它设计为 Vector 的一个更抽象的版本:
class Container {
public:
virtual double& operator[](int) = 0; // 纯虚函数
virtual int size() const = 0;// const 成员函数(§5.2.1)
virtual ~Container() {} // 析构函数(§5.2.2)
};这个类是对特定容器(后续定义)的一个纯粹接口。 virtual 关键字意味着“可能稍后在从此类派生的类中重新定义”。声明为 virtual 的函数称为 虚函数 。从 Container 派生的类为 Container 接口提供实现。奇特的 =0 语法表示该函数是 纯虚函数 ,即从 Container 派生的一些类 必须 定义这个函数。因此,不可能定义一个仅仅是 Container 的对象。例如:
Container c; // 错误:无法创建抽象类的对象
Container* p = new Vector_container(10); // 正确:Container 是 Vector_container 的接口Container 只能作为实现其 operator[]() 和 size() 函数的类的接口。含有纯虚函数的类被称为 抽象类 。
Container 可以这样使用:
void use(Container& c) {
const int sz = c.size();
for (int i=0; i!=sz; ++i)
cout << c[i] << '\n';
}注意, use() 如何在完全不了解实现细节的情况下使用 Container 接口。它使用 size() 和 operator[]() 而没有任何关于具体是哪种类型提供其实现的线索。给多种其他类提供接口的类通常称为 多态类型 。
对于抽象类来说, Container 没有构造函数。毕竟,它没有任何数据需要初始化。另一方面, Container 确实有析构函数,且该析构函数是 virtual 的,这样从 Container 派生的类可以提供实现。同样,这对于抽象类来说也是常见的,因为它们往往通过引用或指针进行操作,而通过指针销毁 Container 的人并不知道它的实现拥有哪些资源;§5.5。
抽象类 Container 只定义了接口,而不包含任何实现。为了让 Container 实际可用,我们需要实现一个容器,该容器实现了其接口所需的功能。为此,我们可以使用具体类 Vector :
class Vector_container : public Container { // Vector_container 实现了 Container
public:
Vector_container(int s) : v(s) { } // 包含 s 个元素的 Vector
~Vector_container() {}
double& operator[](int i) override { return v[i]; }
int size() const override { return v.size(); }
private:
Vector<double> v;
};其中 :public 可以解释为“派生于”或“是...的子类型”。类 Vector_container 被称作是从类 Container 派生的,而类 Container 被称作是类 Vector_container 的基类。另一种术语将 Vector_container 和 Container 分别称为 子类 和 父类 。派生类被认为是从其基类继承成员,因此使用基类和派生类的概念通常被称为 继承 。
成员函数 operator[]() 和 size() 被认为是覆写了基类 Container 中对应的成员。我使用了明确的 override 来清晰表达意图。使用 override 是可选的,但明确指定可以允许编译器捕捉错误,比如函数名称的拼写错误,或是 虚函数 与其预期覆写者的类型之间细微的差异。在较大的类层次结构中,明确使用 override 特别有用,因为它可以避免判断哪些成员应当覆写哪些成员的问题。
析构函数( ~Vector_container() )覆写了基类的析构函数( ~Container() )。请注意,成员析构函数( ~Vector() )会隐式地被其类的析构函数( ~Vector_container() )调用。
对于像 use(Container&) 这样的函数,为了在完全不了解实现细节的情况下使用 Container ,其他某个函数将不得不创建一个可以在其上操作的对象。例如:
void g() {
Vector_container vc(10);
// ... 填充vc ...
use(vc);
}由于 use() 不了解 Vector_container ,而只知道 Container 接口,所以对于 Container 的不同实现,它工作起来同样出色。例如:
class List_container : public Container {
public:
List_container() { }
List_container(initializer_list<double> il) : ld{il} { }
~List_container() {}
double& operator[](int i) override;
int size() const override { return ld.size(); }
private:
list<double> ld; // 标准库中的double列表
};
double& List_container::operator[](int i) {
for (auto& x : ld) {
if (i == 0)
return x;
--i;
}
throw out_of_range{"List container"};
}在这里,表示形式是一个标准库的 list<double> 。通常,我不会使用 list 来实现带有下标操作的容器,因为相比于 vector 的下标操作, list 的性能要差得多。但在本例中,我只是想展示一个与通常实现截然不同的实现方式。
函数可以创建一个 List_container 并让 use() 使用它:
void h() {
List_container lc = {1, 2, 3, 4, 5, 6, 7, 8, 9};
use(lc);
}重点在于 use(Container&) 完全不知道其参数是 Vector_container 、 List_container 还是其他类型的容器;它也不需要知道。它可以使用任何类型的 Container 。它只知道由 Container 定义的接口。因此,如果 List_container 的实现发生了变化,或者使用了一个全新的从 Container 派生的类, use(Container&) 无需重新编译。
这种灵活性的另一面是,对象必须通过指针或引用进行操作(§6.2, §15.2.1)。
完整代码
#include "pch.h";
#include <iostream>;
#include <list>;
#include <vector>;
using namespace std;
class Container {
public:
virtual double& operator[](int) = 0; // 纯虚函数
virtual int size() const = 0;// const 成员函数(§5.2.1)
virtual ~Container() {} // 析构函数(§5.2.2)
};
class Vector_container : public Container { // Vector_container 实现了 Container
public:
Vector_container(int s) : v(s) { } // 包含 s 个元素的 Vector
~Vector_container() {}
double& operator[](int i) override { return v[i]; }
int size() const override { return v.size(); }
private:
vector<double> v;
};
void use(Container& c) {
const int sz = c.size();
for (int i = 0; i != sz; ++i)
cout << c[i] << '\n';
}
void g() {
Vector_container vc(10);
// ... 填充vc ...
use(vc);
}
class List_container : public Container {
public:
List_container() { }
List_container(initializer_list<double> il) : ld{ il } { }
~List_container() {}
double& operator[](int i) override;
int size() const override { return ld.size(); }
private:
list<double> ld; // 标准库中的double列表
};
double& List_container::operator[](int i) {
for (auto& x : ld) {
if (i == 0)
return x;
--i;
}
throw out_of_range{ "List container" };
}
void h() {
List_container lc = { 1, 2, 3, 4, 5, 6, 7, 8, 9 };
use(lc);
}
int main()
{
g();
h();
}5.4 虚函数
再次考虑 Container 的使用:
void use(Container& c) {
const int sz = c.size();
for (int i = 0; i != sz; ++i)
cout << c[i] << '\n';
}如何在 use() 中解析调用 c[i] 到正确的 operator[]() 上呢?当 h() 调用 use() 时,必须调用 List_container 的 operator[]() 。当 g() 调用 use() 时,必须调用 Vector_container 的 operator[]() 。为了实现这种解析, Container 对象必须包含信息——以便它能够在运行时选择正确的函数来调用。常见的实现技术是编译器将虚函数的名称转换为指向函数指针表的索引。这个表通常被称为 虚函数表 (virtual function table),简称 vtbl 。每个具有虚函数的类都有自己的 vtbl ,用来标识其虚函数。这个过程可以用以下图形表示:
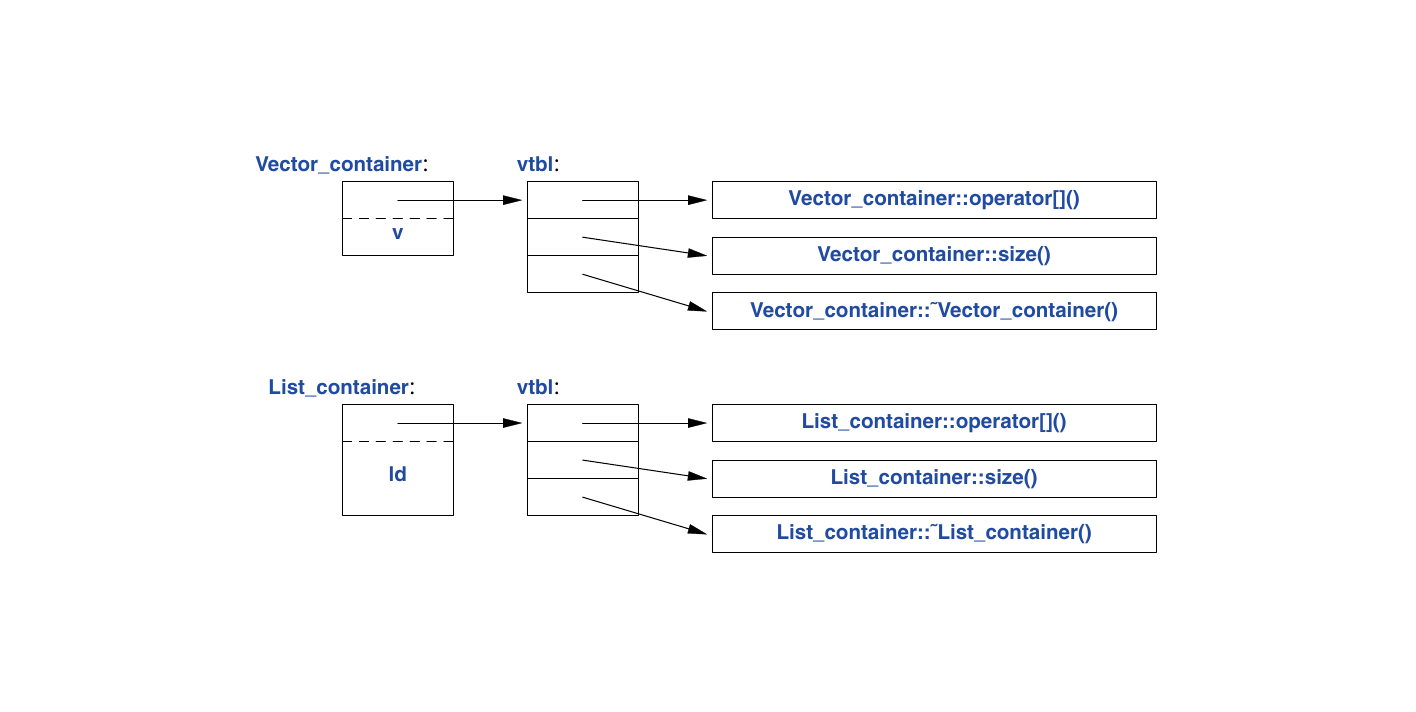
vtbl 中的函数使得即使调用者不知道对象的大小及其数据布局,对象也能被正确使用。调用者实现只需要知道 Container 中指向 vtbl 的指针位置以及每个虚函数所使用的索引。这种虚拟调用机制几乎可以做到与“常规函数调用”机制一样高效(在相差25%以内,且对于对同一对象的重复调用而言成本更低)。它所需的空间开销包括:具有虚函数的每个类的对象上的一个指针,以及这样的每个类的一个 vtbl 。
5.5 类层次结构
Container 示例是一个非常简单的类层次结构示例。 类层次结构 是由派生(例如, : public )创建的格状排列的一组类。我们使用类层次结构来表示具有层次关系的概念,比如“消防车是一种卡车,而卡车又是一种车辆”以及“笑脸是一种圆,而圆则是一种形状”。大型层次结构十分常见,可能包含数百个类,既深又广。作为一个半现实的经典示例,让我们考虑以下形状:
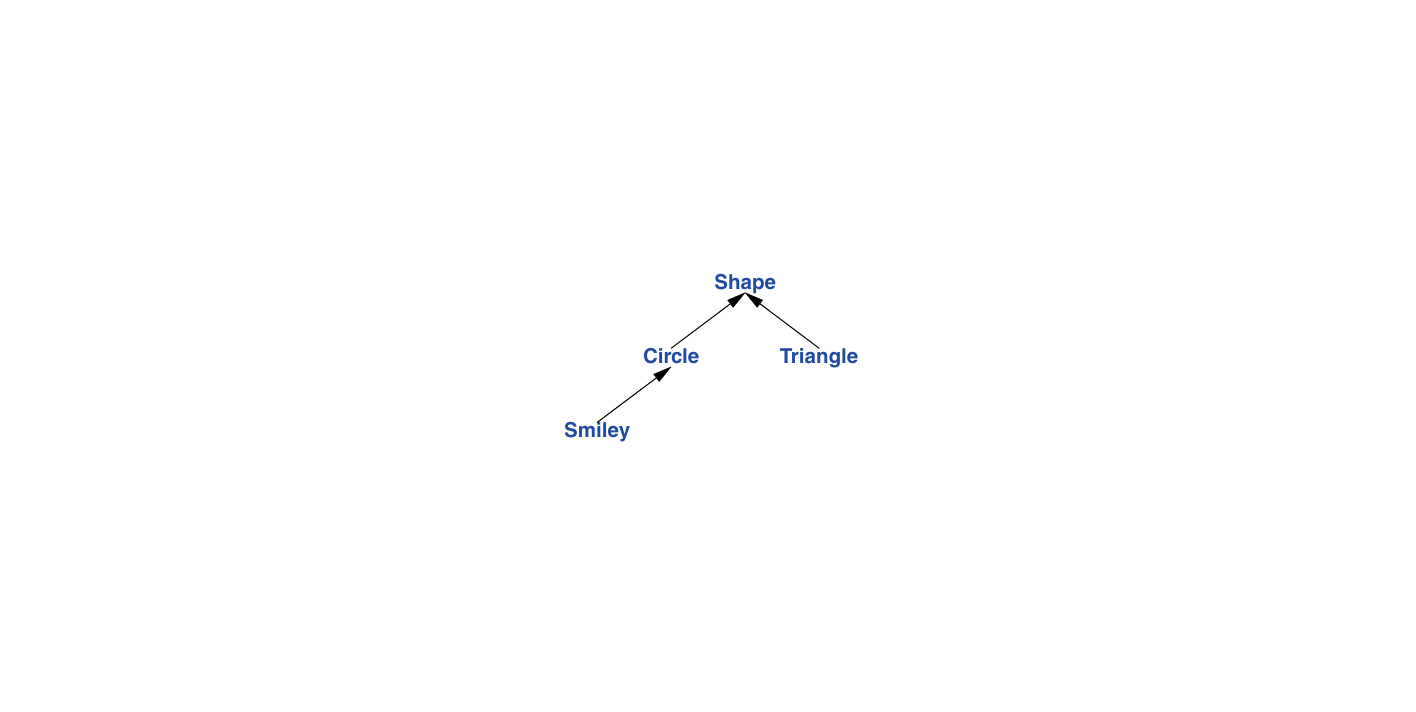
箭头代表继承关系。例如, Circle 类是从 Shape 类派生的。类层次结构通常从基类(根)开始向下绘制,朝向(后续定义的)派生类。为了将这个简单图表示为代码,我们首先需要指定一个类,该类定义所有形状的通用属性:
class Shape {
public:
virtual Point center() const = 0; // 虚函数
virtual void move(Point to) = 0;
virtual void draw() const = 0; // 在当前"Canvas"上绘制
virtual void rotate(int angle) = 0;
virtual ~Shape() {} // 析构函数
// ...
};自然地,这个接口是一个抽象类:就表示而言,除了指向 虚函数表 的指针位置之外,每个 Shape 并没有共通之处。基于这个定义,我们可以编写一般性的函数来操作 Shape 指针的向量:
void rotate_all(vector<Shape*>& v, int angle) { // 将v中的元素旋转angle度
for (auto p : v)
p->rotate(angle);
}为了定义一个特定的形状,我们必须声明它是 Shape 的一种,并指定其特有的属性(包括虚函数的实现):
class Circle : public Shape {
public:
Circle(Point p, int rad) : x{p}, r{rad} {} // 构造函数
Point center() const override { return x; }
void move(Point to) override { x = to; }
void draw() const override;
void rotate(int) override {} // 简单算法
private:
Point x; // 圆心
int r; // 半径
};到现在为止, Shape 和 Circle 的例子相比 Container 和 Vector_container 并未展示新概念,但我们可以进一步构建:
class Smiley : public Circle { // 以圆形为基础构建面部
public:
Smiley(Point p, int rad) : Circle{p,rad}, mouth{nullptr} {}
~Smiley() {
delete mouth;
for (auto p : eyes)
delete p;
}
void move(Point to) override;
void draw() const override;
void rotate(int) override;
void add_eye(Shape* s) {
eyes.push_back(s);
}
void set_mouth(Shape* s);
virtual void wink(int i); // 使第i号眼睛眨眼
// ...
private:
vector<Shape*> eyes; // 通常包含两只眼睛
Shape* mouth;
};我们现在可以利用基类和成员的 draw() 方法来定义 Smiley::draw() :
void Smiley::draw() const {
Circle::draw();
for (auto p : eyes)
p->draw();
mouth->draw();
}注意, Smiley 类通过标准库 vector 管理眼睛,并在析构函数中删除它们。 Shape 的析构函数是虚的, Smiley 的析构函数覆写了它。对于抽象类来说,虚析构函数是必要的,因为派生类的对象通常通过其抽象基类提供的接口进行操作,特别是可能通过基类指针被删除。此时,虚函数调用机制确保调用了正确的析构函数,该析构函数随后会隐式地调用其基类和成员的析构函数。
在这个简化的例子中,将眼睛和嘴巴适当放置在表示面部的圆圈内是程序员的任务。
通过派生新类时增加数据成员、操作或两者,我们获得了极大的灵活性,同时也带来了可能混淆和设计不佳的风险。
5.5.1层次结构的优势
层次结构的类提供了两类好处:
- 接口继承 :派生类的对象可以在需要基类对象的地方使用。也就是说,基类充当了派生类的接口。 Container 和 Shape 类就是这样的例子。这类类往往都是抽象类。
- 实现继承 :基类提供了函数或数据,简化了派生类的实现。比如, Smiley 类对 Circle 构造函数的使用以及调用 Circle::draw() 就是实现继承的例子。这样的基类通常包含数据成员和构造函数。
具体类——尤其是具有小规模表示形式的类——很像内置类型:我们定义它们作为局部变量,通过名称访问它们,复制它们等。而在类层次结构中的类则不同:我们倾向于使用 new 在自由存储上分配它们,并通过指针或引用访问它们。例如,考虑一个从输入流读取描述形状数据并构造相应 Shape 对象的函数:
enum class Kind { circle, triangle, smiley };
Shape* read_shape(istream& is) { // 从输入流is读取形状描述
// 从is读取Shape头型并找到其类型Kind k
switch (k) {
case Kind::circle:
// ... 读取圆形数据 {Point,int} 到 p 和 r ...
return new Circle{p,r};
case Kind::triangle:
// ... 读取三角形数据 {Point,Point,Point} 到 p1, p2, 和 p3 ...
return new Triangle{p1,p2,p3};
case Kind::smiley:
// ... 读取笑脸数据 {Point,int,Shape,Shape,Shape} 到 p, r, e1, e2, 和 m ...
Smiley* ps = new Smiley{p,r};
ps->add_eye(e1);
ps->add_eye(e2);
ps->set_mouth(m);
return ps;
}
}程序可能会这样使用形状读取器:
void user() {
vector<Shape*> v;
while (cin) {
v.push_back(read_shape(cin));
}
draw_all(v); // 对每个元素调用draw()
rotate_all(v, 45); // 对每个元素调用rotate(45)
for (auto p : v)
delete p; // 记得释放元素
}这个例子显然是简化的,特别是在错误处理方面,但它生动地说明了 user() 函数完全不知道它正在操作哪种形状。 user() 代码只需编译一次,之后就可以用于程序中新增的任何 Shape 类型。请注意, user() 外部没有指向 Shape 的指针,因此由 user() 负责释放它们。这是通过 delete 运算符完成的,并且严重依赖于 Shape 的虚析构函数。由于该析构函数是虚的, delete 将调用最深派生类的析构函数。这一点至关重要,因为派生类可能已经获得了各种需要释放的资源(如文件句柄、锁和输出流)。在这种情况下, Smiley 会删除它的眼睛和嘴巴对象。完成这些后,它会调用圆形 Circle 的析构函数。对象通过构造函数“自下而上”(先基类后派生类)构造,通过析构函数“自上而下”(先派生类后基类)销毁。
5.5.2 层次导航
read_shape() 函数返回一个 Shape* 指针,以便我们可以统一处理所有形状。但是,如果我们想使用某个特定派生类提供的成员函数,比如 Smiley 的 wink() 函数,该怎么办呢?我们可以使用 dynamic_cast 运算符来询问“这个 Shape 是否是一种 Smiley ?”:
Shape* ps = read_shape(cin);
if (Smiley* p = dynamic_cast<Smiley*>(ps)) { // ps 指向的是 Smiley 吗?
// 是一个 Smiley;使用它...
} else {
// 不是 Smiley,尝试其他操作...
}如果运行时 dynamic_cast 运算符的参数(此处为 ps )所指向的对象不是预期的类型(此处为 Smiley )或该预期类型的派生类, dynamic_cast 会返回 nullptr 。
当我们有一个指向不同派生类对象的有效指针时,我们会使用 dynamic_cast 转换到指针类型。然后测试结果是否为 nullptr 。这种测试经常方便地放在条件语句中初始化变量时进行。
当不同的类型不被接受时,我们可以直接 dynamic_cast 到引用类型。如果对象不是预期的类型, dynamic_cast 会抛出 bad_cast 异常:
Shape* ps = read_shape(cin);
Smiley& r {dynamic_cast<Smiley&>(∗ps)};// somewhere, catch std::bad_cast谨慎使用 dynamic_cast 可以使代码更清晰。如果我们能在运行时避免检查类型信息,就能编写更简单、更高效的代码。但有时类型信息会丢失,必须恢复。这种情况通常发生在我们将对象传递给某些系统,而该系统接受由基类指定的接口时。当该系统稍后将对象回传给我们时,我们可能需要恢复原始类型。类似于 dynamic_cast 的操作被称为“是某种类型”和“是实例”的操作。这些操作帮助我们在多态性的上下文中找回具体的类型信息,以便执行特定于派生类的操作。
5.5.3 避免资源泄露
资源泄露是指当我们获取了一个资源但未能释放它时发生的情况。必须避免资源泄露,因为泄露的资源对于系统是不可用的。因此,随着系统耗尽所需资源,泄露最终可能导致性能下降甚至崩溃。
在 Smiley 的例子中,有经验的程序员可能已经注意到我留下了三个可能犯错的机会:
- Smiley 的实现者可能忘记删除指向 mouth 的指针。
- 使用 read_shape() 的用户可能忘记删除返回的指针。
- 包含 Shape 指针的容器所有者可能忘记删除所指向的对象。
从这个意义上说,指向自由存储上分配对象的指针是危险的:“plain old pointer”不应用来表示所有权。例如:
void user(int x) {
Shape* p = new Circle{Point{0,0},10};
// ...
if (x < 0) throw Bad_x{}; // 可能泄露
if (x == 0) return; // 可能泄露
// ...
delete p;
}除非 x 为正数,否则这将导致泄露。将 new 的结果赋值给一个“裸指针”是在自找麻烦。
解决此类问题的一个简单方案是在需要删除时使用标准库的 unique_ptr (§15.2.1),而不是使用“裸指针”:
class Smiley : public Circle {
// ...
private:
vector<unique_ptr<Shape>> eyes; // 通常有两只眼睛
unique_ptr<Shape> mouth;
};这是一个资源管理的简单、通用且高效的技术的例子(§ 6.3)。作为这一改变的附带好处,我们不再需要为 Smiley 定义析构函数。编译器将隐式生成一个析构函数,该析构函数会执行 vector 中 unique_ptr (§ 6.3)所需的销毁操作。使用 unique_ptr 的代码将与正确使用原始指针的代码一样高效。
现在考虑 read_shape() 的使用者情况:
unique_ptr<Shape> read_shape(istream& is) // 从输入流is读取形状描述
{
// ... 从is中读取头型并找到其类型Kind k ...
switch (k) {
case Kind::circle:
// ... 读取圆的数据{Point,int}到p和r ...
return unique_ptr<Shape>{new Circle{p,r}};// §15.2.1
// ...
}
void user() {
vector<unique_ptr<Shape>> v;
while (cin) {
v.push_back(read_shape(cin));
}
draw_all(v);
rotate_all(v, 45);
} // 当所有unique_ptr的作用域结束时,所有Shape对象都将被隐式销毁
}这样,每个对象都由一个 unique_ptr 拥有,当不再需要该对象时,即其 unique_ptr 超出作用域时,该对象会被自动删除。
为了让使用 unique_ptr 版本的 user() 正常工作,我们需要 draw_all() 和 rotate_all() 版本能够接受 vector<unique_ptr<Shape>> 作为参数。编写许多这样的 _all() 函数可能会变得繁琐,因此§7.3.2展示了一种替代方法。这种方法可能涉及到泛型编程、模板或者利用策略模式等设计技巧,以减少重复代码并提高代码的重用性。通过这种方式,可以编写更加通用的函数,它们能够处理不同类型的对象容器,而不仅仅是特定的裸指针或智能指针容器。
5.6 建议
- 直接在代码中表达思想;§5.1;[CG: P.1]。
- 具体类型是最简单的类。在适用的情况下,相比于更复杂的类和原始数据结构,优先使用具体类型;§5.2;[CG: C.10]。
- 使用具体类型来表示简单概念;§5.2。
- 对于性能关键的组件,优先使用具体类型而非类层次结构;§5.2。
- 定义构造函数以处理对象的初始化;§5.2.1,§6.1.1;[CG: C.40] [CG: C.41]。
- 仅当函数需要直接访问类的表示时,才将其设为成员函数;§5.2.1;[CG: C.4]。
- 主要为了模拟常规用法而定义运算符;§5.2.1;[CG: C.160]。
- 对称运算符(满足交换律)使用非成员函数定义;§5.2.1;[CG: C.161]。
- 声明一个不修改对象状态的成员函数为 const ;§5.2.1。
- 如果构造函数获取资源,其类需要一个析构函数来释放资源;§5.2.2;[CG: C.20]。
- 避免使用“裸” new 和 delete 操作;§5.2.2;[CG: R.11]。
- 使用资源句柄和RAII(资源获取即初始化)来管理资源;§5.2.2;[CG: R.1]。
- 如果一个类是容器,给它一个初始化列表构造函数;§5.2.3;[CG: C.103]。
- 当需要完全分离接口和实现时,使用抽象类作为接口;§5.3;[CG: C.122]。
- 通过指针和引用访问多态对象;§5.3。
- 抽象类通常不需要构造函数;§5.3;[CG: C.126]。
- 使用类层次结构来表示具有内在层次结构的概念;§5.5。
- 含有虚函数的类应具有虚析构函数;§5.5;[CG: C.127]。
- 在大型类层次结构中,使用 override 明确表示重写;§5.3;[CG: C.128]。
- 设计类层次结构时,区分实现继承和接口继承;§5.5.1;[CG: C.129]。
- 在无法避免遍历类层次结构时使用 dynamic_cast ;§5.5.2;[CG: C.146]。
- 当找不到所需类视为失败时,使用 dynamic_cast 转换为引用类型;§5.5.2;[CG: C.147]。
- 当找不到所需类视为有效替代方案时,使用 dynamic_cast 转换为指针类型;§5.5.2;[CG: C.148]。
- 使用 unique_ptr 或 shared_ptr 避免忘记删除使用 new 创建的对象;§5.5.3;[CG: C.149]。